
This AI newsletter is all you need #70
What happened this week in AI by Louie
This week in AI, we were particularly interested in seeing two new agent models released. Nvidia has unveiled Eureka, an AI agent designed to guide robots in executing complex tasks autonomously. This agent, powered by GPT-4, can independently generate reward functions that surpass the performance of human experts in 83% of tasks, achieving an average enhancement of 52%. The fascinating demo shared by the company illustrates the agent’s ability to train a robotic hand to perform the rapid pen-spinning trick and a human. As mentioned by one of the authors in a blog post, this library utilizes generative AI and reinforcement learning to solve complex tasks.
In other agent news, Adept researchers have introduced a multi-modal architecture for AI agents named Fuyu, with 8 billion parameters. This model adopts a decoder-only architecture capable of processing images and text, simplifying the network design, scalability, and deployment. Additionally, unlike most existing models, it accepts images of varying dimensions, rendering it a valuable addition for use in agents. The model can generate responses for sizable images in just 100 milliseconds. We are excited about the recent progress on AI agents for physical and online applications. While still early in commercialization, agents capable of independently interacting with their environment and executing complex tasks create many opportunities for new AI products and applications.
- Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI Halted the Development of the Arrakis Model
OpenAI’s plans for developing the AI model Arrakis to reduce compute expenses for AI applications like ChatGPT have been halted. Despite this setback, OpenAI’s growth momentum continues, with a projected annual revenue of $1.3 billion. However, they may face challenges with Google’s upcoming AI model Gemini and scrutiny at an AI safety summit.
2. ‘Mind-Blowing’ IBM Chip Speeds Up AI
IBM has developed a brain-inspired computer chip (NorthPole) that significantly enhances AI’s speed and efficiency by reducing the need to access external memory. NorthPole is made of 256 computing units, or cores, each of which contains its own memory.
3. NVIDIA Breakthrough Enables Robots To Teach Themselves
NVIDIA researchers created an AI agent called Eureka, which can automatically generate algorithms to train robots — enabling them to learn complex skills faster. Eureka-generated reward programs outperform expert human-written ones on more than 80% of tasks.
4. Fuyu-8B: A Multimodal Architecture for AI Agents
Adept introduced Fuyu-8B, a powerful open-source vision-language model designed to comprehend and respond to questions regarding images, charts, diagrams, and documents. Fuyu-8B improves over QWEN-VL and PALM-e-12B on 2 out of 3 metrics despite having 2B and 4B fewer parameters, respectively.
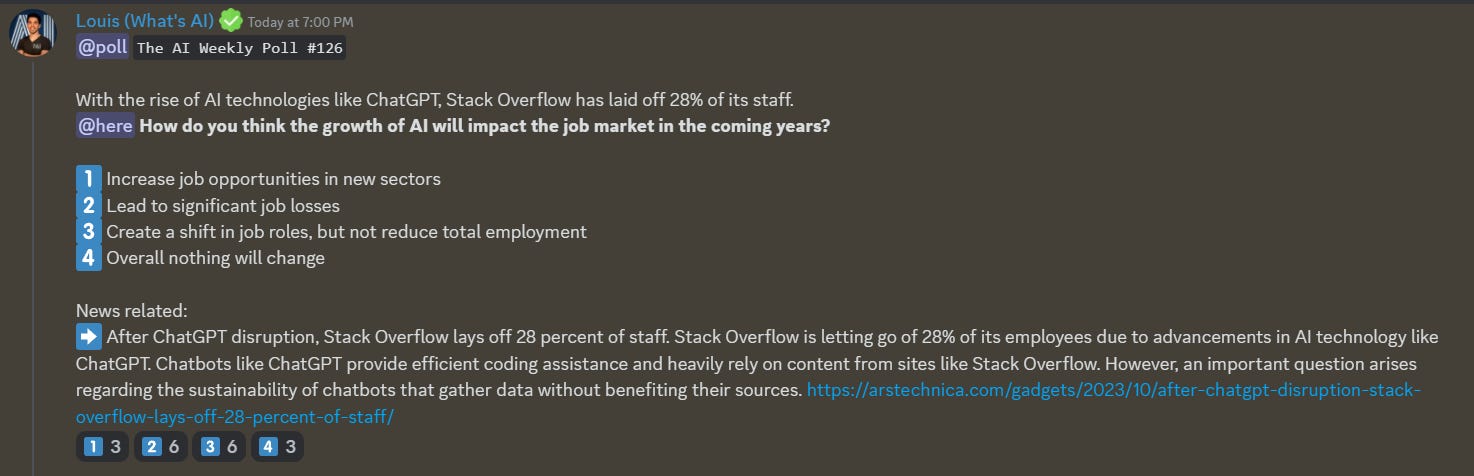
5. After the ChatGPT Disruption, Stack Overflow Laid Off 28 Percent of Its Staff
Stack Overflow is letting go of 28% of its employees due to advancements in AI technology like ChatGPT. Chatbots like ChatGPT provide efficient coding assistance and heavily rely on content from sites like Stack Overflow. However, an important question arises regarding the sustainability of chatbots that gather data without benefiting their sources.
Five 5-minute reads/videos to keep you learning
This article provides essential numbers and equations for working with large language models (LLMs). It covers topics such as compute requirements, computing optima, minimum dataset size, minimum hardware performance, and memory requirements for inference.
2. Why LLaVa-1.5 Is a Great Victory for Open-Source AI
LLaVa-1.5, a smaller yet powerful alternative to OpenAI’s GPT-4 Vision, proves the potential of open-source models for Large Multimodal Models (LMMs). It emphasizes the significance of understanding multimodality in AI, debunking doubts about the feasibility of open-source approaches.
3. GPT-4 Vision Prompt Injection
Vision Prompt Injection is a vulnerability that allows attackers to inject harmful data into prompts via images in OpenAI’s GPT-4. This risks system security, as attackers can execute unauthorized actions or extract data. Defending against this vulnerability is complex and may affect the model’s usability.
GPT-4 is rapidly improving its response speed, particularly in the 99th percentile, where latencies have decreased. GPT-4 and GPT-3.5 maintain a low latency-to-token ratio, indicating efficient performance.
5. Introducing The Foundation Model Transparency Index
A team of researchers from Stanford, MIT, and Princeton has developed a transparency index to evaluate the level of transparency in commercial foundation models. The index, known as the Foundation Model Transparency Index (FMTI), assesses 100 different aspects of transparency, and the results indicate that there is significant room for improvement among major foundation model companies.
Papers & Repositories
1.BitNet: Scaling 1-bit Transformers for Large Language Models
BitNet is a 1-bit Transformer architecture designed to improve memory efficiency and reduce energy consumption in large language models (LLMs). It outperforms 8-bit and FP16 quantization methods and shows potential for effectively scaling to even larger LLMs while maintaining efficiency and performance advantages.
2. HyperAttention: Long-context Attention in Near-Linear Time
HyperAttention is a novel solution that addresses the computational challenge of longer contexts in language models. It outperforms existing methods using Locality Sensitive Hashing (LSH), considerably improving speed. It excels on long-context datasets, making inference faster while maintaining a reasonable perplexity.
3. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
This paper introduces a new framework called Self-RAG. It is an enhanced model that improves Retrieval Augmented Generation (RAG) by allowing language models to reflect on passages using “reflection tokens.” This improvement leads to better responses in knowledge-intensive tasks like QA, reasoning, and fact verification.
4. PaLI-3 Vision Language Models: Smaller, Faster, Stronger
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. It utilizes a ViT model trained with contrastive objectives, which allows it to excel in multimodal benchmarks.
5. DeepSparse: Enabling GPU-Level Inference on Your CPU
DeepSparse is a robust framework that enhances deep learning on CPUs by incorporating sparse kernels, quantization, pruning, and caching of attention keys/values. It achieves GPU-like performance on commonly used CPUs, enabling efficient and robust deployment of models without dedicated accelerators.
Enjoy these papers and news summaries? Get a daily recap in your inbox!
The Learn AI Together Community section!
Meme of the week!

Meme shared by sikewalk
Featured Community post from the Discord
G.huy created a repository containing code examples and resources for parallel computing using CUDA-C. It provides beginners with a starting point to understand parallel computing concepts and how to utilize CUDA-C to leverage the power of GPUs for accelerating computationally intensive tasks. Check it out on GitHub and support a fellow community member. Share your feedback and questions in the thread here.
AI poll of the week!
Join the discussion on Discord.
TAI Curated section
Article of the week
Practical Considerations in RAG Application Design by Kelvin Lu
The RAG (Retrieval Augmented Generation) architecture has been proven efficient in overcoming the LLM input length limit and the knowledge cutoff problem. In today’s LLM technical stack, RAG is among the bedstones for grounding the discussed application on local knowledge, mitigating hallucinations, and making LLM applications auditable. This article discusses some of the practical details of RAG application development.
Our must-read articles
Unlocking the Mysteries of Diffusion Models: An In-Depth Exploration by Youssef Hosni
Introduction to Machine Learning: Exploring Its Many Forms by RaviTeja G
QLoRA: Training a Large Language Model on a 16GB GPU by Pere Martra
If you are interested in publishing with Towards AI, check our guidelines and sign up. We will publish your work to our network if it meets our editorial policies and standards.
Job offers
Machine Learning Engineer, Large Language Model & Generative AI @Hireio, Inc. (Seattle, WA, USA)
Machine Learning Engineer @Pixelynx (Freelancer/ Berlin, Germany)
Jr. Machine Learning Engineer @BreederDAO (Remote)
Tech Lead Machine Learning Engineer @Baubap (Remote)
Machine Learning Engineer @iTechScope (Remote)
Instructor, AI/Machine Learning, Simplilearn (Part-time) @Fullstack Academy (Remote)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
If you are preparing your next machine learning interview, don’t hesitate to check out our leading interview preparation website, confetti!

This AI newsletter is all you need #70 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.