
This AI newsletter is all you need #68
What happened this week in AI by Louie
This week, we witnessed the introduction of LLaVA v1.5, a new open-source multimodal model stepping onto the scene as a contender against GPT-4 with multimodal capabilities. It uses a simple projection matrix to connect the pre-trained CLIP ViT-L/14 vision encoder with Vicuna LLM, resulting in a robust model that can handle images and text. The model is trained in two stages: first, updated the projection matrix based on a subset of CC3M for better alignment, and then, fine-tuned the entire model for two specific use cases, Visual Chat and Science QA, which resulted in state-of-the-art accuracy on the latter benchmark.
The model, released alongside a free-to-access demo, attracted some attention, mainly due to its impressive multimodal capabilities. Users shared their experience on multiple use cases where the model offers food recipes based on an image of the food, solves CAPTCHA codes, generates UI codes, or identifies objects and animals. The model performs well on all tasks mentioned and is a valid competitor for GPT-4.
We are glad to see an open-source model in the multimodal space and expect this can lead to experiments with many new applications. We are now waiting for a wider rollout of the GPT-4 vision model and the much-hyped Google Gemini model to see how they compare and what can be built!
- Louie Peters — Towards AI Co-founder and CEO
Our Free Certification Course on Training & Fine-Tuning LLMs for Production is now live!

We’re excited to release Towards AI’s second free certification course on Training and fine-tuning LLMs for Production in collaboration with Activeloop and Intel Disruptor Initiative. In this course, you will cover the intricacies of training, fine-tuning, and seamlessly integrating these models into AI products. This course will guide you in building a state-of-the-art and cost-efficient AI stack for preparing LLMs for production. It will also cover essential topics such as proprietary versus open-source models, various LLM training methodologies, and production deployment strategies. We also touch upon advanced fine-tuning techniques like LoRA, QLoRA, SFT, and RLHF or training custom models with Cohere. With the support of our partners at Cohere and Lambda, qualifying participants will receive compute credits to be able to run the examples themselves! The ~60 lesson tutorials with ~10 in-depth practical projects and nine accompanying videos are now live on the course page.
Hottest News
1. Meta Quietly Unveils Llama 2 Long AI That Beats GPT-3.5 Turbo and Claude 2 on Some Tasks
Meta is releasing Llama 2 Long, an enhanced version of Llama 2 that underwent continual pretraining with longer training sequences and upsampled long texts. By adding 400 billion tokens and making minor changes to the Rotary Positional Embedding (RoPE), Llama 2 Long can now attend to longer information sequences and include less related information in its model’s knowledge base.
2. Microsoft To Unveil In-House AI Chip, Reducing Reliance on NVIDIA
Microsoft plans to debut its first AI chip next month. Codenamed “Athena,” the chip could allow Microsoft to reduce its reliance on NVIDIA-designed GPUs for AI acceleration in data centers.
3. OpenAI Is Exploring Making Its Own AI Chips
OpenAI is considering developing its own AI chips for ChatGPT due to a global shortage of processors for training AI models. This move could help reduce the high operating costs of ChatGPT, currently $700,000 per day. OpenAI’s decision may diverge from Microsoft, their partner, who is also working on their own AI chips.
4. Introducing Stable LM 3B: Bringing Sustainable, High-Performance Language Models to Smart Devices
Stability AI introduced Stable LM 3B, a high-performing language model designed for smart devices. With 3 billion parameters, it outperforms state-of-the-art 3B models and reduces operating costs and power consumption. The model enables a broader range of smart devices, PCs, and edge computing applications.
Replit is releasing its AI capabilities to all its 23M+ users for free. The code completion and code assistance features are now enabled by default. Replit has also trained a new model, replit-code-v1.5–3b, to power these new features in this massive rollout.
Five 5-minute reads/videos to keep you learning
1.Attention Sinks in LLMs for Endless Fluency
Windowed attention with attention sink tokens is a solution for maintaining fluency in Chat-style Large Language Models (LLMs) like Llama, Mistral, MPT, Falcon, and GPT-NeoX (Pythia), which often struggle with memory limitations. This method effectively manages attention scores and prevents a loss of fluency when the first token moves outside the window during window attention.
2. Fine-Tuning Models Using Prompt-Tuning With Hugging Face’s PEFT Library
This article explores fine-tuning using prompt tuning with Hugging Face’s PEFT Library. It delves deeper into the technique and applications and examines a notebook containing examples of two different models.
3. Mastering Customer Segmentation With LLM
This article provides a comprehensive guide on customer segmentation leveraging LLMs. It covers techniques such as K-means clustering, the PyOD library for outlier detection, the Elbow Method, and Silhouette visualization for determining optimal clusters, evaluation metrics, and using PCA, T-SNE, and LLMs for extracting text embeddings.
4. Safety Risks in Fine-Tuning LLMs
This paper highlights potential safety issues when customizing pre-trained large language models like Meta’s Llama and OpenAI’s GPT-3.5 Turbo. While existing safety alignment infrastructures can restrict harmful behaviors of LLMs at inference time, they do not cover safety risks when fine-tuning privileges are extended to end-users.
5. Godfather of Artificial Intelligence Geoffrey Hinton on the Promise, Risks of Advanced AI
Geoffrey Hinton believes AI systems may be more intelligent than we know, and there’s a chance the machines could take over. This is a transcript of his conversation on the risks of AI, the future, sentient AI, and more.
Papers & Repositories
1.Efficient Streaming Language Models With Attention Sinks
Researchers from MIT, Meta AI, and Carnegie Mellon have developed StreamingLLM, a framework that enables infinite-length language modeling in LLMs without expensive fine-tuning. This efficient approach allows models like GPT-3 and PaLM to handle contexts longer than 4 million tokens by utilizing attention sink tokens, significantly improving performance.
2. A Long Way To Go: Investigating Length Correlations in RLHF
This paper demonstrates that optimizing for response length is a significant factor behind RLHF’s reported improvements in these settings. It explores interventions to replicate these improvements without increasing size, but effectiveness varies.
3. Meta, INRIA Researchers Discover That Explicit Registers Eliminate ViT Attention Spikes
Researchers at Meta and INRIA have discovered a new approach to tackling Vision Transformers (ViTs) attention spikes. Introducing dedicated “register” tokens for temporary storage enabled smoother attention maps, improved downstream performance, and better object discovery capabilities in ViTs.
4. Improved Baselines With Visual Instruction Tuning
Researchers have significantly enhanced the LLaVa multimodal LLM using CLIP-ViT-L-336px and MLP projection. By incorporating academic-task-oriented VQA data and response prompts, the final 13B checkpoint achieved remarkable performance on various benchmarks. Moreover, it requires only 1.2M publicly available data and can be fully trained on a single 8-A100 node in just a day.
5. Think Before You Speak: Training Language Models With Pause Tokens
A recent study suggests that using pause tokens in language models can enable more thorough calculations before generating the next token, leading to improved performance on reasoning tasks. The study found significant score gains on tasks such as answering questions and reasoning.
Enjoy these papers and news summaries? Get a daily recap in your inbox!
The Learn AI Together Community section!
Weekly AI Podcast

In this episode of the “What’s AI” podcast, Louis Bouchard interviews the amazing Auxane Boch. With a focus on AI ethics, this iteration explores the world of AI ethics and governance with an expert, delving into responsible AI practices, the balance between innovation and regulation, and the role of ethics in AI development and deployment. Auxane shares insights into how companies can navigate this landscape, especially with the impending EU regulations. Catch the full episode on YouTube or listen to it on your favorite streaming platform.
Meme of the week!

Meme shared by rucha8062
Featured Community post from the Discord
Dogecoin created InfoGPT, a chatbot that can answer questions from documents. It is built with Langchain, LlamaCPP, Streamlit, ChromaDB, and Sentence Transformers. It is compatible with PDF, TXT, CSV, and DOCX files. Check it out on GitHub and support a fellow community member! Share your feedback and contributions in the thread here.
AI poll of the week!
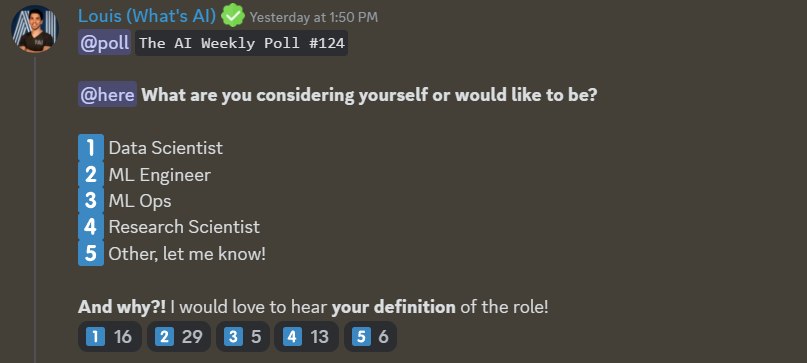
Join the discussion on Discord.
TAI Curated section
Article of the week
Reinforcement Learning: Function Approximation and Deep Q-Networks — Part 4 by Tan Pengshi Alvin
This article will explore two types of Value Function Approximation. The first is the incremental method by stochastic gradient descent with a linear equation and Temporal Difference methods. The article also discusses the popular Deep Q-Networks (DQN). The Deep Q-Networks are the Function Approximation extension to the Off-Policy Q-Learning.
Our must-read articles
Addressing Data Leakage: Essential Considerations for Trustworthy Machine Learning Models by Mala Deep
You Probably Know GANs, But Do You Know How To Train It? by Youssef Hosni
Comprehensive Introduction to AI Image Generation by Youssef Hosni
If you are interested in publishing with Towards AI, check our guidelines and sign up. We will publish your work to our network if it meets our editorial policies and standards.
Job offers
Prompt Engineer — 061023 @Sirion Pte Ltd (Remote/Canada)
Machine Learning Research Scientist @Neural Magic (Remote)
Machine Learning Engineer @Callsign (London, UK)
Lead Data Scientist (WA) @Tiger Analytics (Seattle, WA, USA)
Staff Machine Learning Engineer @Clari (Remote)
Junior Developer with Python(temp) @Clarity AI (Remote)
Manager, Data Platforms @Angi (Remote)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
If you are preparing your next machine learning interview, don’t hesitate to check out our leading interview preparation website, confetti!

This AI newsletter is all you need #68 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.