
Introduction to Reinforcement Learning Series.

Introduction to Reinforcement Learning Series. Tutorial 2: The Return, Value Functions & Bellman Equation
Table of Content:
Aside: How many timesteps does an MDP have?
Why not maximize the reward rt?
3. Exercise 1 — Barry’s Blissful Breakfast Maze
6. Example: Calculate the Value function with Bellman
Pseudocode to Calculate the Value function using Bellman
What would this look like in Python?
7. Exercise: Plane Repair Value
Parts of this tutorial have been adapted from Reinforcement Learning: an Introduction
Introduction
In the previous tutorial, we saw how reinforcement learning algorithms learn a policy. The algorithm’s aim is to find the optimal policy. This is the policy that takes the actions that maximize the sum of future rewards received.
In this tutorial, we start by better defining the goal of learning the optimal policy. We then introduce the key concept (value functions) and equation (Bellman Equation) that allow us to build our first reinforcement learning algorithm in Tutorial 3!
This series initially formed part of Delta Academy and is brought to you in partnership with the Delta Academy team’s new project Superflows!

1. Return Gt
In Tutorial 1 we discussed, informally, the objective of reinforcement learning algorithms. We said that the goal of a reinforcement learning algorithm is to maximize the cumulative reward it receives in the long run.
We define this as the return, denoted Gt.
Simple Return Formula
The simplest way to express the return Gt is the sum of all future rewards you’ll receive where rt is the reward at time t, up to the final timestep T (if it exists — otherwise continue to infinity, ∞ ).

Note: we use GtSum above since we define Gt in the general case below
Aside: How many timesteps does an MDP have?
Not all MDPs last for an infinite number of timesteps. Those with terminal states are called episodic MDPs. The episode ends when you reach those states.
Typically this final timestep in an MDP is denoted by T, as in the equation above.
E.g. in a game of chess, there are many possible states where the game is over. One player has won, or the game is a stalemate. These are the terminal states, and every game of chess would be one episode.
Example #2: if getting a robot to navigate to a certain location, episodes could terminate when it successfully reaches this location, or when it runs out of battery!
Whether the MDP is episodic — has 1 or more terminal states — or not is typically part of the environment and not up to the RL designer.
In some cases, however (e.g., the robot navigation one), the designer also chooses whether the MDP is episodic or not, since they design the environment the agent trains in.
Why not maximize the reward rt?
The real world is complex; not every desirable action yields an instant reward. So we can’t just consider immediate rewards for action, but also possible future rewards.
This is best explained with an example.
Example: Barry’s Blissful Breakfast
Alongside being a busy airline CEO, Barry loves an American Breakfast with bacon and pancakes — nothing brings him greater pleasure. Barry is only rewarded at the end of his breakfast preparation when he eats that first blissful mouthful.
He must first choose which oil to use — vegetable or motor oil. This is the only decision he needs to make — the then cooks the breakfast and serves it up before he can eat it.
When one of the two final states is reached (circles on the right below), the Markov Decision Process terminates, meaning the episode is over.
We can express Barry’s cooking as the Markov Decision Process below.

If we were in the starting state ‘Barry is hungry’ and only considered the reward we’d get immediately after picking the oil, the two options look the same. Both give a reward of 00.
However, in the long run (looking 2 steps into the future), we can see that using motor oil is a terrible idea since it always leads to a negative reward!
If we instead looked at the return we’d get from each successor state when choosing the action at the start (positive for vegetable oil, negative for motor oil), then Barry can make the correct choice.
2. Discounting the Future γ
Do you value $100 given to you now as much as $100 given to you 2 weeks in the future?
You’d probably rather have the $100 now. Future rewards are subject to uncertainty, so we intrinsically discount them compared with immediate rewards.
Discounting future rewards also encourages prompt action, since acting sooner means you have to wait less time for your rewards.
To imitate this, we introduce a discount factor, γ (lowercase Greek letter gamma) when calculating the return. We define 0≤10≤γ≤1 since gamma discounts the relative value of future rewards.
For the reward that we receive n timesteps into the future, we multiply that reward by γn to discount it.
This means each reward is discounted by an exponentially decaying gamma term (γn ). This decay is shown in the diagram below.

Note: we normally use a γ closer to 1 , such as 0.9 or 0.99, as we often deal with many timesteps.
This also has a nice mathematical property. It allows us to solve MDPs that have infinite timesteps without having to consider infinite-sized returns. This is because the exponential decay from the γ terms goes to zero as you look further into the future, changing an infinite sum to a finite one.
General Return Formula
This leads to the following general formula for the return:
The GtSum we saw earlier is a special case of this equation where γ=1, so no terms are discounted (since γ2=1 if γ=1 ).
Example of Discounted Return
First, let’s imagine we’re in an MDP where you’re being paid $1 for each timestep for 3 more timesteps — you’re being paid to guard a valuable piece of art and it’s near the end of your shift.
To illustrate gamma, we’ll set γ=0.5 (very low).
Since you know all this, you can calculate the return:
The reward at t is worth $1
The reward at t+1 is worth $1 × 0.5 = ¢50
The reward at t+2 is worth $1 × 0.52 =¢25
The episode terminates at t+3
Your return from time t would be $1 + ¢50 + ¢25 = $1.75 which isn’t the actual amount of money you’d receive in the next 3 timesteps (which is really $3 ). Instead, it’s how much you value the money at the time t, discounting the future rewards.
Review:
1. Give the general formula for a Markov decision process’s return at time t.
➥ Gt = ∑∞i = 1 γirt + i
2. What trick do we use to tractably compute the return for Markov decision processes with infinite timesteps?
➥ Use a discount factor γ< 1. Because each step’s return is scaled by γn, future terms converge to zero. The resulting sum is effectively finite.
3. What does Gt denote in a Markov decision process?
➥ The return at time t, i.e. the value it tries to maximize.
4. What is an episodic Markov decision process?
➥ One with a terminal state, i.e. a finite number of time steps.
5. Define GtSum in terms of Gt.
➥ GtSum = Gt where γ =1.
6. Notation for a Markov decision process’s return at time t?
➥ Gt.
7. What does T denote in the context of a Markov decision process?
➥ The final time step.
8. Notation for the final time step in an episode Markov decision process?
➥ T.
9. What range of values can γ take in Markov decision processes?
➥ 0 < = γ < = 1
10. What does γ denote in Markov decision processes?
➥ A discount factor for future rewards.
11. For a chess-playing Markov decision process, what is an “episode”?
➥ A single game of chess.
3. Exercise 1 — Barry’s Blissful Breakfast Maze

https://replit.com/team/delta-academy-RL7/21-Barrys-Blissful-Breakfasts
Barry decides to open Barry’s Blissful Breakfasts — a fully operational restaurant that only serves his favourite breakfast of bacon cooked with vegetable oil.
To commemorate the anniversary of opening this restaurant, he wants to run an event for his customers. One Sunday evening after closing time, he builds a maze with obstacle-course elements in the restaurant. He hides prizes around the restaurant — vouchers for extra bacon or vegetable oil on your breakfast.
He then tests out the course and hidden prizes himself before deciding whether it’s complete.
Calculate the return at each timestep of Barry’s test run, given the rewards he receives in the test run.
4. Value Functions vπ(s)
Definition: The value function vπ(s) of a state s is the expected return from s while following policy π.
A higher value for a state means a higher expected return, meaning the return is on average higher given you follow policy π.
Whereas returns are the discounted sums of future rewards you experience, the value function is the expected return from this state. Since we’ve only focused on deterministic examples thus far, this distinction may be unclear.
➤ Why does the policy affect the expected return?
We’ll explain this with an example.
Suppose we think about the value of the starting state: “Barry is hungry”. The expected return we get depends on which action we pick — if we “Use Vegetable Oil”, the start state has a positive value, and if we “Use Motor Oil” it has a negative value.
Since the action is chosen by the policy, the value of the starting state depends on which policy you follow.

➤ Example: the difference between value and return
Suppose there’s a very simple MDP — you flip a fair coin once, get $1 if it lands on heads, and nothing if it lands on tails. Then the MDP terminates.
Restated:
50% of the time, it lands on heads, so your return is $1.
The other 50% of the time, it lands on tails, so your return is $0.
However, the value of your starting state (before flipping) is ¢50, since this is the expected return. Note that you never get a return of ¢50¢50 in an episode!
Mathematical Definition
The value function is defined as:

➤ Notation
Definitions of notation we’ve not seen before:
E is the symbol for ‘expectation’ and acts on the variables inside the brackets (in this case Gt ). This means the average value of Gt if you did infinite simulations from that state.
The subscript of E (in this case π ) just refers to the conditions under which the expectation is taken. This is equivalent to saying: “Given that we follow policy π(s) ”. Since the policy affects how the state changes and the rewards you see, it’s important this is specified.
▼ Expected values — main ideas video
<a href="https://medium.com/media/baf59149f570693fd53dafb89ea76dc0/href">https://medium.com/media/baf59149f570693fd53dafb89ea76dc0/href</a>
If you’re still unclear: don’t worry too much! Not understanding the mathematical notation won’t stop you from understanding what the value intuitively means or how to estimate the value function algorithmically (covered in the next tutorial).
While a value function exists for any policy π, an agent will usually not know the exact value function of the policy it is following.
An approximate value function is commonly estimated and re-estimated from the sequences of states and rewards an agent observes from experience in the environment. This allows it to determine its policy by choosing the action that leads to the highest value successor state.∗∗
**The process of estimating the value function is explored in the next tutorial.
5. Bellman Equation
This is one of the key equations of Reinforcement Learning algorithms. And it comes from a very simple observation.
The value function vπ(st) where st is the state at time t and π is the policy you’re following, can be decomposed into two components:
The reward received rt at timestep t
The value function vπ(st+1) at state st+1
To put it another way, the value of the state you’re in is the reward you get this timestep plus the value of the next state you’re in.

Mathematically, when dealing with deterministic rewards this is:

This is given that you follow policy π to select at (the action taken at state st).
The γ is the discount factor we’ve just been introduced to.
▼ Mathematical generalization of this equation which deals with randomness
In general, the state transition function T (the function that determines the successor state given the previous state and action) can be random. Similarly, the reward function R (the function that outputs the reward from the environment) doesn’t need to be deterministic.
As a result, for this to be true, we must take expectations over the rewards and successor states.

While this might seem self-evident, this equation is the heart of a key class of reinforcement learning algorithms.
6. Example: Calculate the Value function with Bellman
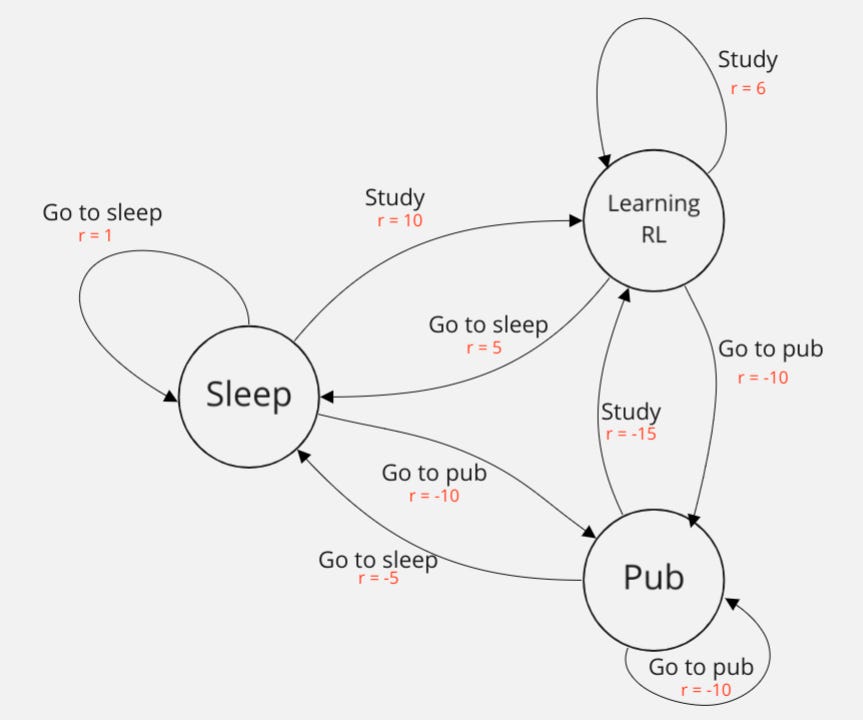
So how can we calculate the value function of an MDP for a specific policy?
In the above example, we know:(1)
The state transitions for different actions (e.g. if you’re in the state Pub and take action Go to sleep then you move to state Sleep)
In general, this is referred to as the state transition function.
2. The reward for every state-action pair possible
In general, this is referred to as the reward function
There aren’t any terminal states in this MDP. Given this, we can ‘simulate’ how the environment and rewards evolve into the future and calculate the return as a weighted sum of rewards.
In the code below we first calculate the value of Sleep since it's visited from all other states when following the optimal policy. (2)
➤ Footnotes
(1) It’s common to not have access to either of these in Reinforcement Learning problems. For example, in chess, the state transitions between your turns aren’t easy to calculate since they depend on the move the opponent makes. We’ll see how this is dealt with in future tutorials.
(2) Reminder: the optimal policy is to Go to sleep when at the Pub and alternate between Learning RL and Sleep otherwise.
Pseudocode to Calculate the Value function using Bellman
INITIALISE policy as the optimal policy
INITIALISE value_function as a mapping from each state to 0
INITIALISE state as "Sleep"
# First calculate the value of "Sleep"
FOR steps_into_future in {0, 1, ..., large_number}:
Sample action from policy(state)
Sample reward from reward_function(state, action)
# This is the term from the next timestep into the future
UPDATE value_function "Sleep" term by adding (gamma ** steps_into_future) * reward
UPDATE current_state to transition_fn(state, action)
END FORNext, we can use the Bellman Equation to calculate the values for the other states, using the value for Sleep we just calculated.
# `Pub` is 1 step from `Sleep` if following optimal policy
INITIALISE current_state as "Pub"
INITIALISE action as "Go to sleep"
Sample reward from reward_fn(state, action)
UPDATE value_function "Pub" term to be reward + gamma * value_function("Sleep")
# `Learning RL` is also 1 step away from `Sleep` when following the optimal policy
INITIALISE current_state as "Learning RL"
INITIALISE action as "Go to sleep"
Sample reward from reward_fn(state, action)
UPDATE value_function "Learning RL" term to (reward + gamma * value_function("Sleep"))In this case, you can also calculate the values for Pub and Learning RL the same way we did for Sleep, but the above trick saves some time.
What would this look like in Python?
To make the above pseudocode more concrete, how can we represent the state transition function, the reward function, and the value function in Python code?
In general, they are stochastic functions with inputs and outputs. In this case, all our functions are deterministic, so we can use a dictionary as a neat representation. Below are examples:
optimal_policy = {
"Pub": "Go to sleep",
"Sleep": "Study",
"Learning RL": "Go to sleep"
}
initial_value_fn = {"Sleep": 0, "Pub": 0, "Go to sleep": 0}
# Below are the actual values for gamma = 0.9
value_function = {'Pub': 63.68, 'Sleep': 76.32, 'Learning RL': 73.68}The state transition function is much longer since it needs an entry for all state-action pairs (9 in this case).
So it hasn’t been written above, but would have the following format: {(state, action): successor_state}.
Review
1. How can we use a Markov decision process’s estimated value function to form a policy?
➥ Choose the action which leads to the successor state with the highest value according to the value function.
2. Define a Markov decision process’s value function (in words).
➥ The expected return from a given state while following a given policy.
3. How does the Bellman Equation help us solve Markov decision processes’ value functions?
➥ It allows us to solve for the value function at a given state using only the successor state’s value. No need to search the entire tree for each state.
4. Give the Bellman Equation (assuming deterministic rewards).
➥ vπ(st ) = rt + γvπ(st+1)
5. What is a Markov decision process’s reward function?
➥ For every state and action, gives the associated reward.
6. What is a Markov decision process’s state transition function?
➥ Given an action and a state, produces a successor state.
7. Give the mathematical definition of a Markov decision process’s value function.
➥ vπ(st )= Eπ[Gt]
7. Exercise: Plane Repair Value


https://replit.com/team/delta-academy-RL7/22-Plane-Repair-Value
Now in Hong Kong (that was quick!), Barry’s execs are asking him for proof that the optimal policy you proposed for plane repairs (from the previous tutorial — see diagram) is correct.
They want to see the value functions of the two possible deterministic* policies that are possible, with a discount factor γ=0.99.
**Deterministic means that no randomness is involved. The opposite, a stochastic policy, would output a probability distribution over the possible actions (e.g. when Faulty, Fly 80% of the time, Repair 20% of the time). We aren’t considering these for now.
Introduction to Reinforcement Learning Series. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.