
TAI #207: Claude Opus 4.8 Is Better, but Dynamic Workflows Are the Bigger Story
Also, Anthropic files for an IPO after raising $65B, Liquid AI LFM2.5–8B-A1B, Nemotron 3 Ultra, and more.



What happened this week in AI by Louie
Anthropic released Claude Opus 4.8 on May 28, six weeks after Opus 4.7. It landed alongside two unusually large company announcements: Anthropic raised $65 billion at a $965 billion post-money valuation and confidentially submitted a draft S-1 for an initial public offering. OpenAI brought its frontier models and Codex to AWS, while NVIDIA and Microsoft unveiled RTX Spark PCs designed to run personal AI agents locally. The labs are racing on three fronts at once: better models, distribution everywhere, and more compute per task once the models start working.
My early read is that Opus 4.8 is a strong upgrade, though Anthropic’s own “modest but tangible” description is fair. It feels better in everyday use: cleaner writing, closer instruction-following, and fewer of the familiar AI-output signatures- the throat-clearing, repetitive caveats, cloying agreement, over-formatting, and the compulsion to turn every answer into a miniature consulting deck. It is easier to direct and less likely to add a layer of slop you then strip out by hand.
That comes with a trade-off. Anthropic says Opus 4.8 follows instructions more literally, especially at lower effort. Mostly I want that: ask for a narrow rewrite or a specific coding task, and it does that task carefully instead of improvising five adjacent ones. But literal following can lead to tunnel vision, where older versions inferred sensible extra steps. Opus 4.8 rewards writing the scope down. If you expect it to check a second codebase, use a skill, inspect production data, or verify its own result, say so.
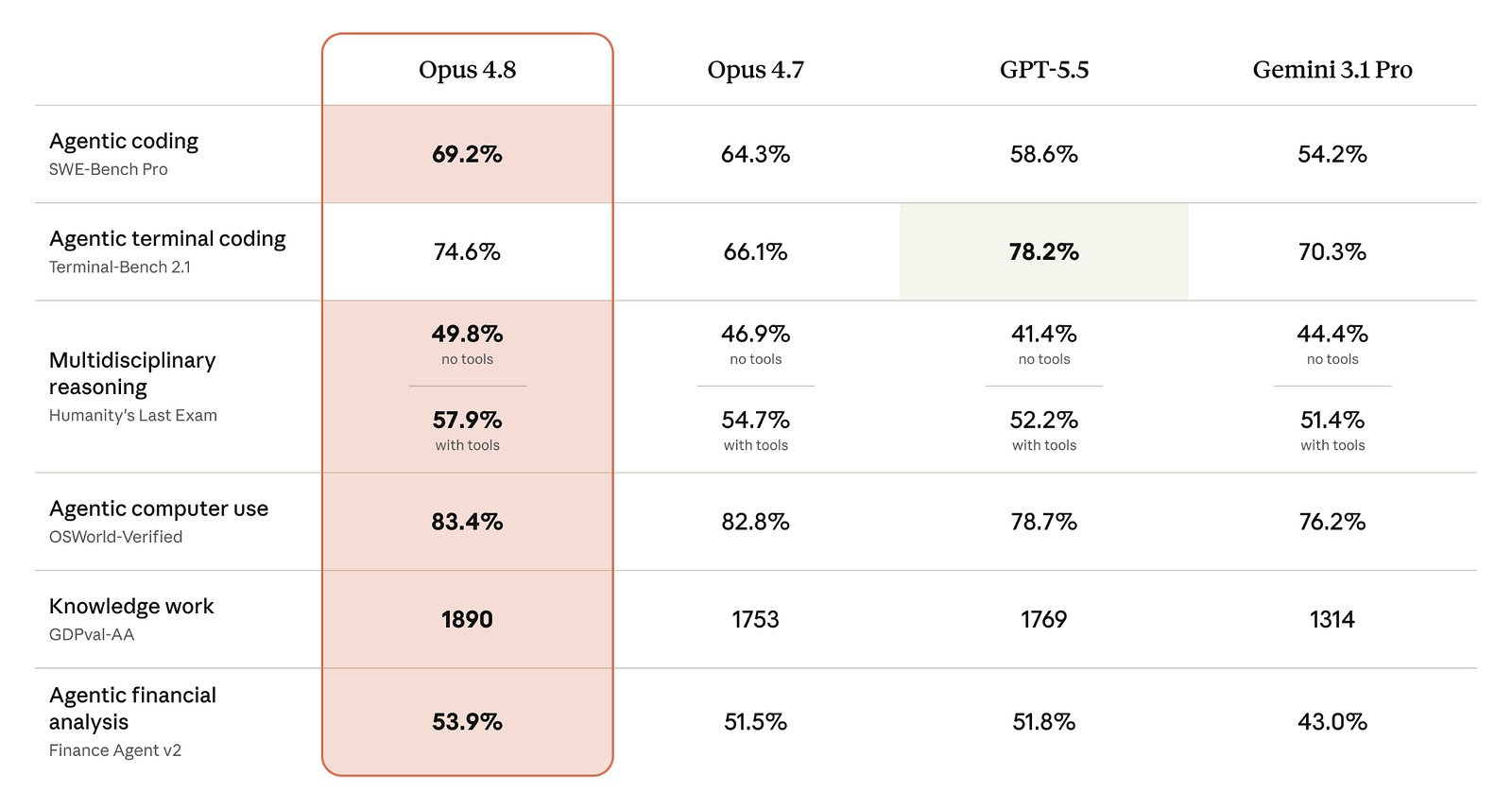
The benchmark gains are broad without a Mythos-scale jump. On Anthropic’s evaluations, Opus 4.8 scores 69.2% on SWE-bench Pro versus 64.3% for Opus 4.7; 57.9% versus 54.7% on Humanity’s Last Exam with tools; 83.4% versus 82.8% on OSWorld-Verified for computer use; and 53.9% versus 51.5% on Finance Agent v2. Its GDPval-AA score for professional knowledge work rises from 1753 to 1890. GPT-5.5 still leads Anthropic’s Terminal-Bench 2.1 table at 78.2%, with Opus 4.8 at 74.6%.
One of the more useful improvements is honesty about flawed work. Anthropic says Opus 4.8 is around four times less likely than Opus 4.7 to let flaws in its own code go unnoticed. In its system card, it became the first Anthropic model to record a 0% bad-behavior rate in an evaluation for uncritically reporting flawed results. The same card is not all good news: Anthropic flags a regression in computer-use safety and prompt-injection resistance, a side effect of cutting some adversarial-agent training to protect honesty, so weigh that before pointing Opus 4.8 at the open web or untrusted inputs. Better judgment lowers the review burden without removing it, and early users have already caught the model declaring work complete without running the build. I would keep explicit verification gates in every serious workflow.
Artificial Analysis puts Opus 4.8 at 61.4 on its Intelligence Index, up 4.1 points from Opus 4.7 and currently first overall, and its like-for-like suite run came in 8.4% cheaper, roughly $4,686 versus $5,117- a better score for slightly less money, not a step change.
Standard API pricing is flat at $5 and $25 per million tokens for input and output, respectively. Fast mode is three times cheaper than the Opus 4.7 Fast tier, down from $30/$150 to $10/$50. That is a sensible correction, but Fast mode is still poor value for most users: it costs twice the standard per-token price for up to 2.5x output throughput, which speeds token generation but not tool calls, reasoning, or queueing over a long agent run. I would use it only where latency has clear economic value.
The upper reasoning modes are more important than the price card. Opus 4.8 now defaults to high effort, and Anthropic says xhigh allocates substantially more thinking than the same setting on Opus 4.7, while max can tip into overthinking. List price per token is flat, but the model now has more room to spend tokens. Increasingly, the cost of a model is set by the workflow around it, the effort level, context size, verification loops, and the number of subagents, rather than the API price printed on the launch page.
That sets up the more important release: Dynamic Workflows in Claude Code. In this research preview, Claude writes a JavaScript orchestration script, runs it in a separate background runtime, and delegates parts of a complex job to many subagents. Intermediate work stays in script variables rather than bloating the main conversation, so Claude can split a migration into phases, parallelize independent tasks, have other agents review them, rerun failed tests, and hand back the results while your main session stays responsive.
The high-compute setting is called ultracode, combining xhigh reasoning with automatic orchestration. Anthropic caps a run at 1,000 subagents with up to 16 running concurrently, and its own demo shows a migration fanning out across dozens of agents, with individual Opus 4.8 subagents each burning tens of thousands of tokens before the job finishes.
Anthropic is direct about the bill: its launch post warns that Dynamic Workflows can consume substantially more tokens than a typical Claude Code session, and early users are already hitting usage limits after a single large run. Its own earlier research sets the scale. Ordinary agents used roughly four times as many tokens as a chat exchange, multi-agent systems roughly fifteen times as many, and token use alone explained 80% of the performance variance on BrowseComp. The economic shape is consistent: better answers often come from spending far more inference compute on search, parallel exploration, criticism, and verification.
More compute is not automatically more performance, though. A recent study of agent scaling found the returns are family-dependent, and Anthropic’s own models showed the highest variance and occasional multi-agent underperformance, with results swinging from +81% to −70% depending on how the task was structured. Coordination overhead is real, and a swarm pointed at a poorly specified task mostly buys you a larger bill.
There is real value when the task fits. Anthropic says Jarred Sumner used Dynamic Workflows to port Bun from Zig to Rust: roughly 750,000 lines of Rust code, 99.8% of the existing test suite passing, 11 days from first commit to merge, with two reviewers on every file. Anthropic is clear the port is not yet in production, so treat it as an impressive engineering result rather than proof of full autonomy.
I run a similar pattern in Codex for coding, research, and white-collar work, often up to 20 subagents in parallel: the model first creates an orchestration plan, then some subagents search sources, some work on code edits, some test assumptions, some criticize a draft, some verify facts, and some iterate on sections before anything reaches me. Dynamic Workflows adds scale and automation to this setup: Anthropic is turning the agent manager into a product primitive and letting the model decide when a larger swarm is justified.
Used well, this is powerful; used carelessly, it gets expensive fast. The sensible rule is to reserve large workflows for tasks with a clear decomposition, migrations, audits, research projects, security reviews, and test generation, and to inspect the plan on a small slice before turning the swarm loose.
Anthropic ended the launch with a bigger flag: it expects to bring Mythos-class models, more capable than Opus, to all customers in the coming weeks, once stronger cyber safeguards are ready. Mythos Preview has already found more than 10,000 high- or critical-severity vulnerabilities through Project Glasswing partners. Opus 4.8 is a strong refinement; the larger release is what to watch.
OpenAI will probably respond quickly. GPT-5.6 has not been announced, so treat this as my expectation, but OpenAI shipped GPT-5.5 just 49 days after GPT-5.4, and GPT-5.5 is now 40 days old. Google says Gemini 3.5 Pro is due this month. Opus 4.8 is good enough to use today, and I am most curious to see what Anthropic means by Mythos-class soon.
Why should you care?
The thing to understand about Dynamic Workflows is that the swarm actually works. Running many agents well has always been the hard part: deciding how to split a job, when to parallelize, which results to trust, and when to spawn a reviewer or rerun a failed test. Most developers never get this right, which is why multi-agent setups so often underperform a single good agent. A recent agent-scaling study put numbers to it, with results ranging from +81% to −70% depending solely on how the task was structured. Dynamic Workflows hands that orchestration to the model itself: Claude writes the script, manages the agents, and decides when a larger swarm is justified.
That is the real unlock, and it is an economic one. Token usage can be one of the best predictors of answer quality if used effectively, with Anthropic’s own research finding it explained 80% of the performance variance on BrowseComp, but spending those tokens productively requires demand orchestration skills that few people have. In fact, the recent trend of “tokenmaxing” at enterprise is causing some pushback on LLM budgets. The very best engineers can spend up to $1m LLM tokens per month, albeit with highly diminishing returns, but it is non-trivial to use even just $200 tokens per month effectively. Dynamic Workflows lowers that barrier, so far more people can put serious compute behind a problem and get the gains rather than just a bigger bill.
It is still far from perfect, and the strongest results so far came from talented engineers aiming it well. Jarred Sumner’s 750,000-line Bun port from Zig to Rust is the showcase precisely because a domain expert set up the lifetimes, the file-level structure, and two reviewers per file before the swarm ran. Claude handles the coordination, but the quality of the decomposition, the spec, and the definition of done still comes from a person who knows the problem. Point it at something vague, and the swarm mostly amplifies the vagueness.
So the leverage is moving toward people who can frame and direct work rather than hand-wire agents. For individuals, take one repetitive job, point a workflow at it, and learn where it needs your judgment. For teams, build the verification layer first: what the agents can touch, what a correct result looks like, and which checks must pass. The model now manages the swarm. Your edge is knowing what to ask it for.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Anthropic Introduces Claude Opus 4.8
Anthropic released Claude Opus 4.8 on May 28, 41 days after Opus 4.7. The model scores 61.4 on the Artificial Analysis Intelligence Index, compared to 60.2 for GPT-5.5 and 57.3 for Opus 4.7. Coding performance improved across the board: 69.2% on SWE-bench Pro (up from 64.3%), 88.6% on SWE-bench Verified (up from 87.6%), and 83.4% on OSWorld-Verified for computer use. Mathematical reasoning also saw a significant gain, with USAMO 2026 rising to 96.7% from 69.3% on Opus 4.7. On alignment metrics, Opus 4.8 is the first Claude model to score 0% on uncritically reporting flawed results, and Anthropic reports it is roughly 4x less likely than Opus 4.7 to let flaws in its own code pass unremarked. Pricing remains at $5/$25 per million tokens. Fast mode operates at 2.5x speed and is priced at $10/$50, which Anthropic states is 3x cheaper than fast mode on previous Opus models. User-selectable effort controls are now available on claude.ai. The 1M-token context window carries over from Opus 4.7.
2. NVIDIA Releases Nemotron 3 Ultra
NVIDIA announced Nemotron 3 Ultra, the largest model in the Nemotron 3 family, with 550B total parameters and 90% sparsity, activating 55B parameters per token. Artificial Analysis, which partnered with NVIDIA on evaluation, measured a score of 48 on its Intelligence Index, ahead of Gemma 4 31B (39), Nemotron 3 Super (36), and gpt-oss-120b (33) among US open-weight models. It represents a 12-point jump over Nemotron 3 Super, released in March 2026 at 120B parameters. Among global open-weight models, Nemotron 3 Ultra trails Kimi K2.6 at 54, which currently ranks fourth globally. NVIDIA is positioning inference throughput as a differentiator, with the model exceeding 300 tokens per second in BF16. NVF4 quantization will also be available for higher throughput. The model completes the three-tier Nemotron 3 family alongside Nano for edge deployment and Super for mid-range enterprise workloads.
3. Anthropic Ships Dynamic Workflows and Cheaper Fast Mode
Anthropic launched Dynamic Workflows in Claude Code, a feature designed to handle tasks too large for a single session by planning the work, distributing it across up to 1,000 parallel subagents, and returning a consolidated result. Claude generates a JavaScript orchestration script for each task, which a runtime executes in the background while the session remains responsive. The orchestration plan is stored in script variables rather than Claude’s context window. A secondary set of agents can attempt to refute each agent’s findings, iterating until results converge. Up to 16 agents can run concurrently. In one reported use case, Jarred Sumner used the feature to port Bun from Zig to Rust, generating 750,000 lines of code in 11 days with a 99.8% test pass rate. Dynamic Workflows is available in the Claude Code CLI, desktop app, and VS Code extension for Max, Team, and some Enterprise plans, as well as through the API on Amazon Bedrock, Vertex AI, and Microsoft Foundry.
4. Liquid AI Releases LFM2.5-8B-A1B
Liquid AI released LFM2.5-8B-A1B, an edge MoE model with 8.3B total parameters and 1.5B active per token, designed for tool calling and agentic workflows on consumer hardware. It builds on LFM2-8B-A1B from October 2025 with several updates: the context window expands from 32K to 128K tokens, pretraining scales from 12T to 38T tokens, and the vocabulary doubles to 128K for improved tokenization efficiency in non-Latin languages. The model operates in reasoning-only mode, producing explicit chains of thought before generating a response. Its architecture comprises 24 layers (18 double-gated LIV convolution blocks and 6 GQA layers) and supports 9 languages. The AA-Omniscience Index improved by 53.62 points over its predecessor, accompanied by a 56.01-point improvement in non-hallucination rate. Liquid AI reports benchmark scores competitive with models at 20B and above. The model is available on Hugging Face under the LFM1.0 license with day-one support for llama.cpp, MLX, vLLM, and SGLang.
5. StepFun Releases Step 3.7 Flash
StepFun released and open-sourced Step 3.7 Flash, a 198B-parameter sparse MoE vision-language model that activates 11B parameters per token. The model combines a 196B language backbone with a 1.8B vision encoder (ViT), supports a 256K context window, and exposes three configurable reasoning levels (high, medium, low) that allow a trade-off between speed, cost, and depth per request. It targets agentic workflows, coding, search, and multimodal tasks. On ClawEval-1.1, it scored 67.1; on SWE-Bench Pro, it scored 56.3; and on τ²-bench, it achieved 98%+ across all difficulty levels. The model runs at 400 tokens per second and is compatible with Claude Code, Hermes Agent, OpenClaw, and MCP. Weights are available on Hugging Face and support local deployment on a Mac Studio M4 Max or DGX Spark.
6. Hermes Agent Ships Tool Search for MCP
Nous Research’s open-source Hermes Agent now includes Tool Search, a feature that addresses context bloat caused by MCP tool schemas. Rather than loading every tool’s JSON schema into the context on every turn, Tool Search defers MCP and plugin schemas until the model requires them, replacing the full catalog with three lightweight bridge tools: tool_search, tool_describe, and tool_call. In a typical deployment with five MCP servers and 34 tools, prompt sizes averaged 45,000 tokens per turn, with roughly 22,000 consumed by tool schemas alone. Anthropic’s evaluations measured accuracy improving from 49% to 74% on Claude Opus 4 with large tool catalogs when Tool Search is enabled. Core Hermes tools (terminal, read_file, web_search, send_message) are never deferred. The feature introduces approximately 300 tokens of overhead plus at least one additional round trip per cold tool, making it most effective when many tools are attached but few are used per turn.
7. Perplexity AI Open-Sources Unigram Tokenizer
Perplexity’s research team reimplemented their Unigram tokenizer from scratch in Rust and open-sourced it as pplx-unigram within their pplx-garden inference repository. The encoder targets XLM-RoBERTa’s 250K-token Unigram vocabulary, commonly used in ranking and retrieval models. At production input lengths, it reduces p50 latency by roughly 5x compared to the Hugging Face tokenizers crate, 2x compared to SentencePiece (C++), and 1.5x compared to IREE’s tokenizer (C), with zero steady-state heap allocations. In production, it reduced CPU utilization in Perplexity’s inference stack by 5-6x and cut double-digit milliseconds from reranker latency. The gains are meaningful because small models like rerankers and embedders complete GPU inference in single-digit milliseconds, making CPU-side tokenization a non-trivial portion of the total end-to-end latency.
AI Tip of the Day
Routing simple requests to smaller models reduces costs, but average quality scores across mixed traffic can hide routes that have regressed. A cheaper model that handles summarization well can fail on extraction, tool argument formatting, or policy-constrained decisions.
Before promoting a model to a cheaper route, build a regression set for each task type individually: classification, entity extraction, rewrite, retrieval query generation, tool call construction, and final answer generation. Track accuracy, latency, and cost per route, not in aggregate. A model that scores 92% across all traffic might score 60% on tool argument creation, and that one route will break your agent before your dashboard catches it.
The promotion rule is straightforward: a model qualifies for a route only if it meets the route’s task-specific threshold. If it fails extraction but passes summarization, route summarization to it, and keep extraction on the expensive model. Partial promotion per task is cheaper than full promotion with silent regressions.
We cover routing architecture and per-task evaluation in depth in our Full Stack AI Engineering course.
Five 5-minute reads/videos to keep you learning
This article walks through the process of building a contract intelligence pipeline that automates end-to-end contract review. It combines PaddleOCR, hybrid RAG retrieval, and GPT-4o within a LangGraph state machine to build a system that accepts PDFs, scanned images, and XML files, applies image denoising and deskewing before OCR, and then constructs both a FAISS and a BM25 index, fused via Reciprocal Rank Fusion.
2. Agent Memory with Vector Stores: HNSW, Forgetting, and Budgets
This article benchmarks exact cosine search against HNSW across memory sizes from 100 to 1M entries, finding HNSW delivers a 783x speedup at scale while maintaining 95% recall. It covers three eviction strategies and concludes that recency-decay scoring with a tunable half-life outperforms FIFO without the O(N) cost of relevance-only eviction. It also works through context budget arithmetic, setting k=10–20 as the practical ceiling for 8K-context models, and includes a full Python implementation using the Anthropic SDK.
3. Claude Can’t Run Regression. A 200-Year-Old Theorem Proves It Never Will
Regression estimates conditional expectations, not predictions or causes. This article lays out why the 200-year-old statistical framework remains irreplaceable alongside modern machine learning. LLMs mishandle regression in four specific ways: conflating R-squared with model quality, misreading p-values as evidence of truth, skipping diagnostic reasoning from residuals, and failing to justify causal assumptions. Those assumptions, Gauss-Markov included, cannot be learned from data. They require domain knowledge and human judgment that no language model trained on text can substitute.
4. Sliding Windows Forget: Why Long-Running LLM Apps Need Memory Policy
Long-running LLM apps fail at context selection more often than they fail at reasoning. This article introduces LLM-Context-Optimization-Engine, a benchmark harness that compares eight context policies across synthetic sessions up to 10,000 turns. Importance-based selection retains 90.7% of current critical facts under a 600-message budget, while sliding windows retain close to none. Retrieval improves recall but introduces stale evidence alongside valid facts.
5. Reinforcement Learning: The Post-Training Engine Behind Reasoning Models
Reinforcement learning has moved from games and robotics into the core of how modern LLMs reason and behave. This article traces that shift across RLHF, DPO, RLAIF, and GRPO, explaining how each method shapes model behavior differently. DeepSeek-R1 demonstrates that RL-driven reasoning can emerge from strong base models, while distillation makes those gains deployable at scale.
Repositories & Tools
1. SkyRL is a modular, full-stack reinforcement learning framework for training LLM agents, covering training, sampling, and a gymnasium of tool-use environments.
2. Hermes Web UI is a lightweight, self-hostable browser interface for Hermes Agent with full CLI parity.
3. Supermemory is an open-source memory and context engine for AI agents that automatically extracts facts from conversations, builds user profiles, and handles contradictions and temporal updates.
4. mKernel is a library of persistent CUDA kernels that fuse intra-node NVLink communication, inter-node RDMA, and dense compute into a single kernel, enabling fine-grained tile-level overlap across multiple GPUs and nodes without NCCL.
5. MarkItDown is an open-source Python utility for converting files into Markdown for use with LLMs, with a plugin architecture.
6. Polar is a rollout infrastructure for training RL agents on any harness, decoupling agent execution from training so teams can run RL over existing coding harnesses.
Top Papers of The Week
1. SIA: Self-Improving AI with Harness & Weight Updates
Current self-improvement research is split into two silos: one rewrites agent scaffolds (prompts, tools, retry logic) while keeping model weights fixed, and the other updates weights via RL while keeping the scaffold fixed. SIA unifies both by having a Feedback-Agent iteratively update both the harness and the weights of a task-specific agent. The system is task-agnostic, requiring only a task specification and a verifier. Evaluated across Chinese legal charge classification, low-level GPU kernel optimization, and single-cell RNA denoising, SIA demonstrates that jointly optimizing scaffold and weights outperforms either approach in isolation.
2. The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
MiniMax introduces the M2 series, a family of MoE language models with 229.9B total parameters and only 9.8B activated per token. The model is designed end-to-end for agentic deployment, built on three components: agent-driven data pipelines that produce large-scale, verifiable trajectories grounded in executable workspaces with artifact-aligned rewards; Forge, a scalable agent-native RL system for long-horizon agent trajectories with windowed-FIFO scheduling and prefix-tree merging; and the latest M2.7 checkpoint, which takes a first step toward self-evolution by autonomously debugging training runs and modifying its own scaffold. On Hugging Face, M2.5 scores 75.8% on SWE-bench Verified and 55.4% on SWE-bench Pro.
3. GrepSeek: Training Search Agents for Direct Corpus Interaction
Modern retrieval compresses corpus access into a single top-k similarity step, but this step becomes a bottleneck for agentic tasks that require exact lexical constraints, multi-step hypothesis refinement, or the recovery of evidence that was filtered out early. GrepSeek trains search agents to interact with a raw corpus directly using general-purpose terminal tools (grep, file reads, shell commands, lightweight scripts) rather than embedding models or vector indices. The approach outperforms index-based retrieval baselines across agentic search, multi-hop QA, and IR ranking tasks, with average gains of +11.0% on BrowseComp-Plus, +30.7% on multi-hop QA, and +21.5% on IR ranking.
4. Exploring Autonomous Agentic Data Engineering for Model Specialization
This paper formalizes Autonomous Agentic Data Engineering, a task in which LLMs serve as autonomous data engineers who plan, generate, and iteratively optimize training data to specialize a student model, guided entirely by post-training performance improvement. The agent treats data as an optimizable component, running end-to-end data curation loops across multiple domains without human intervention. In experiments, GPT-5.2, acting as the data engineer, constructed a training curriculum that improved a student model by 57.29% entirely through iterative, agent-driven data adaptation.
5. Self-Improving Language Models with Bidirectional Evolutionary Search
Best-of-N sampling and tree search face two limitations when used for self-improvement: they rely on sparse verification signals, and they only explore regions with high model probability. This paper proposes Bidirectional Evolutionary Search (BES), which couples forward candidate evolution with backward goal decomposition. The forward search recombines partial trajectories using evolution operators to reach candidates that no single model rollout would produce. The backward search recursively decomposes the original task into checkable subgoals, providing dense intermediate feedback to guide the forward pass. BES improves both post-training data generation and inference-time search across math and coding tasks.
Quick Links
1. OpenAI frontier models and Codex are now generally available on AWS, accessible through Amazon Bedrock in both commercial and GovCloud regions. GPT-5.5 and GPT-5.4 run on Bedrock’s next-generation inference engine via the Responses API, with pricing matching OpenAI’s first-party rates and usage counting toward existing AWS commitments. Codex is available through the Codex App, CLI, and IDE integrations, with all inference routed through Bedrock under the same IAM, VPC isolation, and encryption controls that AWS customers already use.
Who’s Hiring in AI
Software Engineer, Ad Formats @OpenAI (San Francisco, CA, USA)
AI/Machine Learning Engineer @Oddball (Remote)
AI Developer PL/SR @CI&T (Remote/Brazil)
Python Engineer (AI/ML Focus) @Oowlish (Remote)
A.I. Engineering Intern @Sezzle (Remote)
Lead AI/ML Applied Scientist @UnitedHealth Group (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
I found your insights on the improvements in Claude Opus 4.8 fascinating, especially regarding dynamic workflows. It's exciting to see how AI is evolving! Have you personally implemented any of these new features in your projects? https://fnaffree.io