
TAI #206: Gemini 3.5 Flash Is Stronger, But Flash Is No Longer Cheap
Also, Gemini Omni, Antigravity 2.0, Codex Updates, Deepseek v4-Pro price cuts & more.




What happened this week in AI by Louie
Google I/O 2026 was Google’s biggest AI reset in a while. Google launched Gemini 3.5 Flash, introduced Gemini Omni and Omni Flash, expanded Antigravity into a full standalone agent workspace, launched Managed Agents in the Gemini API, retired the old Gemini CLI, and previewed Gemini Spark as a 24/7 personal agent. The release was clearly designed around one message: Google wants Gemini to be the model, agent runtime, developer environment, consumer assistant, search engine, and creative system behind a lot of its products.
On paper, Gemini 3.5 Flash is a strong release. Google says it is the first Gemini 3.5 model and its strongest agentic and coding model so far. It is generally available through Google Antigravity, the Gemini API in AI Studio, Android Studio, the Gemini Enterprise Agent Platform, the Gemini app, and AI Mode in Search. Google reported 76.2% on Terminal-Bench 2.1, 83.6% on MCP Atlas, 78.4% on OSWorld-Verified, 1656 Elo on GDPval-AA, 84.2% on CharXiv Reasoning, and 83.6% on MMMU-Pro. Artificial Analysis measured it at more than 280 output tokens per second and placed it on the intelligence-versus-speed frontier with an Intelligence Index score of 55, up 9 points from Gemini 3 Flash.
That is the positive case. The model is real, fast, and the agentic benchmark jump from Gemini 3 Flash is meaningful. My overall reaction though was still disappointment.
The first reason is simple. This was a very expensive Flash release, not the Gemini 3.5 Pro release many people were waiting for. Google says 3.5 Pro is already being used internally and should roll out next month. That may end up being the more important model. For now, the new flagship public model at I/O is called Flash, but it no longer priced like the old Flash bargain.
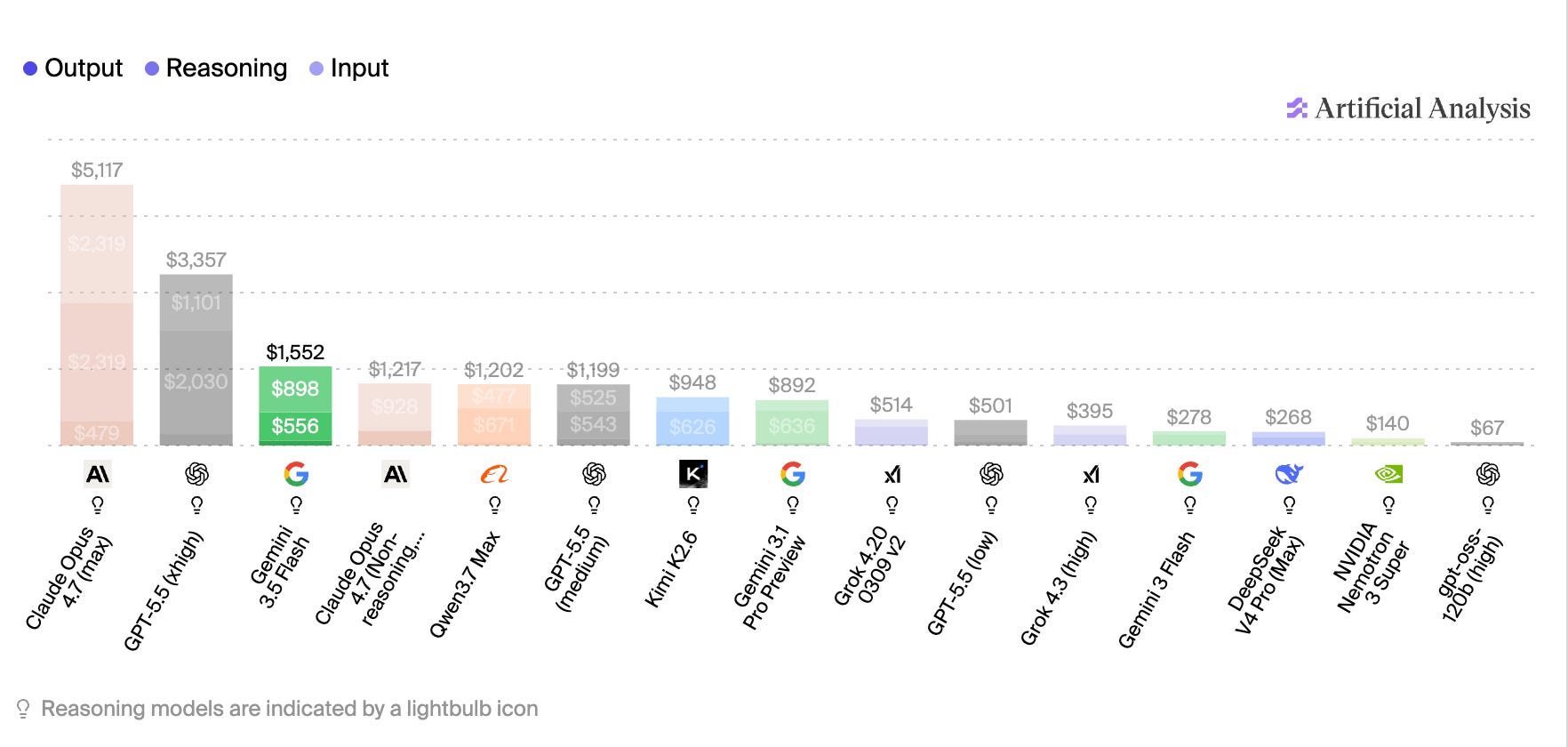
Gemini 1.5 Flash sat at $0.30 per million output tokens after Google’s August 2024 price cut, Gemini 2.0 Flash at $0.40, Gemini 2.5 Flash at $2.50, Gemini 3 Flash Preview at $3.00, and Gemini 3.5 Flash at $9.00. From the 1.5 baseline to 3.5 Flash, that is a 30x increase on output tokens. From Gemini 3 Flash Preview to 3.5 Flash, it is 3x.
Output tokens are also only part of the bill. Input tokens can also balloon when an agent keeps reading its own history and tool outputs. Artificial Analysis captured this better than the headline token price. Running its benchmark suite on Gemini 3.5 Flash cost about $1,552, 5.5x the cost of Gemini 3 Flash and 75% more than Gemini 3.1 Pro. Output token usage was broadly unchanged from Gemini 3 Flash (73M vs 72M), but input token usage rose significantly, driven by more turns in agentic evaluations. The metric that matters is completed workflow per dollar after context growth, thinking tokens, tool calls, grounding charges, cache hit rates, retries, and human cleanup.
I’d add one note here, I think it is possible Gemini 3.5 Pro has been held up in red teaming or even government review. This could justify temporary higher pricing for a 3.5 Flash model that cannibalizes 3.1-Pro-Preview demand (now likely meaningful revenue) while we wait for the new Pro release.
The second reason the release felt disappointing is release cadence. Gemini 3.5 will need to be much stronger than “competitive” to dislodge the enterprise habits forming around OpenAI and Anthropic. OpenAI has moved from GPT-5.2 to GPT-5.4 to GPT-5.5 in a few months, each release aimed more directly at coding, computer use, tool use, long-context work, and enterprise agents. Anthropic has shipped Opus 4.6, Sonnet 4.6, Opus 4.7, Claude Code, and Cowork upgrades in the same window, alongside large enterprise partnerships. From a buyer’s perspective there is always another GPT or Claude improvement arriving, another coding-agent benchmark, another enterprise story, another cloud or systems-integrator partnership. To switch workflows already forming a model has to be better, available, and operationally easy enough to justify the cost of changing.
Google has recently felt too slow where it matters for many real projects. Gemini 3 Pro and Gemini 3.1 Pro spent too long in preview for teams that need stable model IDs, procurement approval, security controls, support expectations, and region-specific deployment paths. To Google’s credit, Gemini 3.5 Flash launched generally available. The catch is that “available” still does not always mean deployable. Google Cloud documentation lists Gemini 3.5 Flash with global, US, and EU multi-region processing, while Gemini 2.5 Flash has a broader regional footprint. For regulated or region-specific projects, that distinction matters.
We have felt this directly. For some client projects we have been stuck on Gemini 2.5 for months because the newer Gemini 3 models were in preview, not available in the right Vertex cloud region. If the best Gemini model is not the model we can deploy in the required region with the required controls, it does not matter how good the benchmark table looks. The price jump from 3 Flash Preview to 3.5 Flash makes the bar higher again. “Flash” used to mean high-throughput economics. 3.5 Flash now looks more like a fast frontier model with a Flash label.
On a positive note, one of the Gemini’s key strengths remains multimodal quality. We still find Gemini’s image and spatial understanding as well as native video ingestion genuinely valuable. For invoices, screenshots, diagrams, charts, visual inspection, messy PDFs, UI reasoning, and image-heavy workflows, Gemini often gives us useful results when other models feel less grounded in the visual structure. The 83.6% on MMMU-Pro and 84.2% on CharXiv Reasoning line up with what we see in practice.
Deepmind’s strength in visual understanding also contributes to Gemini Omni. Google introduced Omni as a new multimodal generation family that starts with video, with Gemini Omni Flash rolling out first through the Gemini app, Google Flow, YouTube Shorts Remix, and YouTube Create. Omni can take text, images, audio, and video as input, then generate and edit video with audio. The demos focus on reference-based generation, character and voice consistency, multi-turn editing, prompt-based scene changes, improved physics, SynthID watermarking, and C2PA Content Credentials.
I am more excited by Omni as an editing model than as a pure one-shot video model. The important idea is that every prompt builds on the previous state. Change the camera angle. Keep the character. Move the scene. Add a reference object. Adjust the lighting. Keep the action but change the style. This is where Gemini’s image and spatial understanding should matter. If the model can preserve identity, reason about object relationships, and hold spatial continuity through edits, AI video becomes much more usable.
My read is that Google I/O 2026 was a strong platform announcement and a weaker model announcement than it first looked. Gemini 3.5 Flash is a serious model. Omni is a serious creative direction. Antigravity, Managed Agents, and Spark are the right product architecture. The release still leaves Google with a hard problem: enterprise AI adoption is being shaped now, and OpenAI and Anthropic are moving quickly enough that “close enough” may not be enough.
Why should you care?
For AI engineers, Gemini 3.5 Flash is worth using where speed, multimodal input, visual reasoning, and structured agent scaffolds matter most. Vision-heavy document processing, UI reasoning, multimodal extraction, high-throughput agents, and Google-native workflows are the obvious fits. For deep reasoning, large repos, long-context retrieval, and the hardest software engineering work, GPT-5.5 and Claude Opus 4.7 still look stronger. Run the same evaluation suite against all three on your own tasks before defaulting to any of them.
For builders working on AI media, Omni is the more interesting release. The short-term question is not whether it beats every video model on raw visual quality. The question is whether conversational, reference-based editing becomes the dominant workflow for AI video. If it does, Google’s combination of Gemini, Flow, YouTube, SynthID, and spatial understanding could matter a lot more than any single benchmark suggests today.
For Google, the path is clear. Gemini 3.5 Pro has to arrive quickly, be widely deployable in the regions and configurations enterprise buyers need, and feel obviously better in the workflows OpenAI and Anthropic are already winning. A strong Flash model is helpful. A much more expensive Flash model is not enough.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
Google Launches Gemini 3.5 Flash
Google launched Gemini 3.5 Flash at Google I/O 2026, positioning it as a high-throughput model for agentic coding and long-horizon software tasks. The model is available through Google Antigravity, the Gemini API in AI Studio, Android Studio, and Google’s enterprise agent stack, with Google claiming it is its strongest coding and agentic model while costing less than half as much as comparable models. Google highlighted scores of 76.2% on Terminal-Bench 2.1, 1656 Elo on GDPval-AA, and 83.6% on MCP Atlas, putting the release squarely in the developer-agent infrastructure bucket rather than the usual chatbot confetti. For AI engineers, the practical significance is that Google is pairing model release, agent runtime, integrated development environment, and deployment path in one stack.
Google Launches Antigravity 2.0
Google released Antigravity 2.0, a standalone desktop development environment built around parallel AI agents rather than a conventional coding assistant bolted onto an editor. The update adds a desktop app, command-line interface, software development kit, voice support, subagents, hooks, asynchronous task management, and migration support from Gemini CLI. Google says Antigravity 2.0 is co-optimized with Gemini 3.5 Flash, which matters because the product is not merely an interface layer; it is becoming Google’s main workspace for multi-agent coding, testing, and repository work. The bigger shift for engineers is architectural: Antigravity is designed to orchestrate multiple agents over real codebases while keeping tool use, review, and task management inside a developer-controlled environment.
Cohere released Command A+, its newest open-weight enterprise model, under the Apache 2.0 license. The model uses a sparse mixture-of-experts architecture with 218 billion total parameters and 25 billion active parameters, supports 128,000-token input context and 64,000-token generation, and is optimized for reasoning, tool use, multilingual work, retrieval-augmented generation, and multimodal document processing. Cohere says it can run on as little as two H100 GPUs, with additional support for vLLM and Transformers. The release is especially relevant for teams that want privately deployable frontier-adjacent models without handing their inference stack to a single hosted provider. Cohere also reported a Terminal-Bench Hard jump from 3% to 25%, which suggests the company is aiming directly at agentic coding and workflow automation workloads.
Google Launches Managed Agents API
Google introduced the Managed Agents API as part of its broader Google Cloud agent platform push, giving developers a hosted way to build agents that can reason, call tools, and execute code inside secure remote environments. This is one of the more practically important launches from the week because it moves agent development closer to managed infrastructure rather than notebook demos, local scripts, or brittle custom sandboxes. For AI engineers, the useful bit is not the branding; it is the combination of model access, tool calling, code execution, remote runtime isolation, and Google-hosted operational plumbing. The release also signals that agent execution environments are becoming a first-class cloud product, much like managed databases or container runtimes became standard infrastructure earlier.
OpenAI Upgrades Codex With Goal Mode, Appshots, and Safer Remote Use
OpenAI shipped a Codex update that adds richer context handling, Goal Mode, browser improvements, browser annotations, Appshots, and “remote locked” computer use. The enterprise release notes also add admin analytics and plugin-sharing status for Codex, giving organizations more visibility into how coding agents are being used across workspaces. For engineers, the important change is that Codex is being pushed further toward long-running, stateful coding work instead of isolated prompt-response sessions. Appshots help Codex understand visual application state, Goal Mode gives longer tasks more explicit direction, and locked remote use gives teams a safer way to let agents operate in controlled environments. This is less splashy than a new model launch, but it is highly consequential for day-to-day agent reliability.
Google Launches Gemini Omni and Omni Flash
Google introduced Gemini Omni, a new multimodal generation model family starting with video, plus Omni Flash for faster access across consumer and creator workflows. Google says the model can generate video from text, image, audio, and video inputs, with physics and world-knowledge improvements, reference-based generation, character consistency, prompt-based editing, and SynthID watermarking. Omni Flash is rolling out through the Gemini app, Flow, and YouTube Shorts for Google AI Plus, Pro, and Ultra users, while Google Cloud says API and Agent Platform access are coming in the following weeks. For AI engineers, the near-term significance is multimodal application design: video generation is moving from isolated creative tooling toward programmable model endpoints and agent workflows.
Google announced Gemini Spark, a 24/7 personal AI agent built on Gemini 3.5 and Antigravity. It is rolling out first to trusted testers, with a beta planned for Google AI Ultra subscribers the following week. Google describes Spark as a background agent that can work across Workspace, connected services, the open web, and later local files, with permission prompts, isolated ephemeral virtual machines, Data Loss Prevention hooks, and Agent Gateway controls in enterprise contexts. For AI engineers, Spark matters less as a personal assistant and more as a preview of where persistent agents are heading: long-running, cross-application task execution with enterprise policy controls wrapped around them. The hard parts will be permissioning, auditability, memory, and failure recovery, not calendar tricks.
Cloudflare Integrates Claude Managed Agents With Cloudflare Sandboxes
Cloudflare announced an integration between Anthropic’s Claude Managed Agents and Cloudflare Sandboxes, giving Claude-hosted agents a secure execution layer for code, browsers, tools, networking, and observability. The architecture separates the agent loop from the execution environment: Claude handles reasoning, while Cloudflare executes commands, manages sandbox isolation, handles outbound proxying, connects to private services, records browser sessions, and exposes logs, metrics, and Secure Shell access. This is a serious infrastructure story for agent builders because sandbox quality is now a gating factor for production agents. Fast, cheap, isolated execution beats “just run it on my laptop” by a country mile, especially once agents start touching internal systems, private networks, and user-specific credentials.
Anthropic Expands Claude Compliance API Integrations
Anthropic added Claude Compliance API integrations with security and compliance tools, expanding the ways IT and security teams can govern Claude across enterprise environments. Cloudflare separately announced support for the Claude Compliance API inside Cloudflare Cloud Access Security Broker, letting organizations monitor Claude usage, uploads, prompts, and generated content through an API integration rather than endpoint agents. This is not a model-quality story, but it is important for AI engineers because adoption often stalls when security teams cannot observe or govern usage. Compliance APIs are becoming the “please let this past procurement” layer for enterprise AI products. The release also shows that model vendors are being forced to build administration, audit, and data-governance surfaces alongside raw model capability.
Google Launches Chrome DevTools for Agents
Google announced Chrome DevTools for agents, making browser debugging workflows available to Google Antigravity and more than 20 coding agents. This is easy to miss among the larger I/O announcements, but it is a sharp little release for AI engineers building web agents. Browser agents need to inspect Document Object Model state, network activity, console errors, screenshots, page events, and user interface behavior, and ordinary prompt-only observation is rarely enough. By connecting agents to Chrome DevTools primitives, Google is giving them better instrumentation for debugging, test generation, front-end repair, and browser automation. The result should be fewer agents guessing from screenshots and more agents reasoning from actual runtime state, which is kinder to everyone except flaky selectors.
Qwen Launches Qwen3.5-LiveTranslate-Flash
Qwen released Qwen3.5-LiveTranslate-Flash, a simultaneous interpretation model built on Qwen3.5-Omni. The official Qwen listing describes it as a model that translates from sound to sight and word, focused on real-time interpretation rather than static text translation. Details exposed publicly are thinner than the launches from Google, Cohere, or xAI, but the direction is important: low-latency speech, translation, and multimodal understanding are converging into single model families rather than separate automatic speech recognition, translation, and rendering pipelines. For AI engineers, this opens design space for live meeting copilots, accessibility tools, multilingual support agents, and media workflows where latency and partial output quality matter more than polished batch translation.
Ai2 released OlmoEarth v1.1, updating its Earth observation foundation model family with efficiency improvements aimed at lowering compute requirements while maintaining performance from the first version. Ai2 says the v1.1 models reduce compute by up to 3x through transformer and token-efficiency improvements, with model weights, training code, and technical materials available to developers. This is a narrower release than the general coding-agent launches, but it is meaningful for AI engineers working on geospatial AI, climate analytics, remote sensing, infrastructure monitoring, agriculture, or defense-adjacent imagery pipelines. The valuable part is cost reduction: Earth observation models can be expensive to fine-tune and run, so better token and architecture efficiency directly affects whether teams can deploy them outside research labs.
Claude Code Ships Usage, Agent, and Code Review Updates
Anthropic shipped several Claude Code updates during the window, including usage, agent, and code review improvements. The updates add per-category usage breakdowns for skills, subagents, plugins, and per-Model Context Protocol-server cost; keyboard scrolling in diff detail views; Markdown task-list rendering; enterprise settings for Claude.ai cloud Model Context Protocol connectors; improved background sessions; and stronger code-review workflows. Anthropic also added JSON output for claude agents, OpenTelemetry agent identifiers, GitHub repository and pull request information in status JSON, plugin browsing improvements, and additional hook inputs for background tasks and session crons. These are not fireworks, but they are exactly the features that make terminal agents easier to administer, meter, and debug inside engineering teams.
DeepSeek Makes V4-Pro Price Cut Permanent
DeepSeek announced that it will make a 75% price cut on its flagship V4-Pro model permanent, reducing API pricing to a quarter of the previous level. Reuters reported that prices now range from 0.025 to 6 yuan per million tokens, down from 0.1 to 24 yuan per million tokens. This is not a new model release, but it belongs in the top 20 because pricing changes alter what engineers can actually build. Cheaper high-capability inference changes routing strategies, batch processing economics, evaluation loops, agent iteration, and whether teams can afford to run more reasoning steps per task. The practical takeaway is simple: model quality still matters, but token economics increasingly decide which systems survive production traffic.
AI Tip of the Day
AI teammates work best when their workspace is clearly scoped.
When using tools that can read and write files, the folder you share matters. If you give the AI a messy project folder with old drafts, outdated reports, random downloads, and duplicate files, it may use the wrong source material. If you give it too much access, you also increase the risk of accidental edits or confusion.
Create a simple project workspace instead. Use an inbox folder for raw files, a reference folder for brand guides or templates, and an outputs folder for finished work. Tell the AI which folders it can read, which files are the source of truth, and where final deliverables should go.
A good folder structure is not admin work. It is prompt engineering for files.
This tip comes directly from our AI for Work course. If you want to start learning how to use AI for your own workflows and benefit from its efficiency gains, you might find that our AI for Work course is a great starting point for professionals.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Ragdoll Archers https://ragdollarchers2.io is the pinnacle of physics-based archery games, featuring incredibly hilarious and unpredictable "ragdoll" movements.