
TAI #199: Gemma 4 Brings a Credible US Open-Weight Contender Back to the Table
Also, Anthropic’s annualized revenue surpasses $30B, Cursor 3, Veo 3.1 Lite & more!



What happened this week in AI by Louie
This week, Google DeepMind released Gemma 4, and I think this is the most consequential US open-weight release in quite a while. China has been leading the open-weight conversation for months, especially with ever-larger Mixture-of-Experts families and increasingly agentic models. Gemma 4 does not wipe that scoreboard clean. What it does do is bring a strong Apache 2.0 family from a U.S. lab back into the part of the market that actually wants to run models itself, on local hardware or within tighter enterprise boundaries.
That said, the part of the market that insists on self-hosting is shrinking. Anthropic reported today that its run-rate revenue has surpassed $30 billion, up from about $9 billion at the end of 2025 and roughly $1 billion in December 2024. That is approximately 30x in 16 months. We are seeing far more clients comfortable with using LLM APIs or enterprise-tier agents and chatbots than we did six months ago. The security and privacy policies of the major AI labs have also become substantially clearer, which has helped lower the barrier for risk-averse organizations.
Google is launching four variants of Gemma 4: the small E2B and E4B edge models, the 31B dense flagship, and a 26B A4B MoE aimed at higher-throughput reasoning. Gemma has now passed 400 million downloads and more than 100,000 community variants. This generation is built on Gemini 3 research and, for the first time, ships under the Apache 2.0 license.
On Google’s benchmarks, the two larger models are serious. The 31B posts 1,452 on Arena AI text, 84.3% on GPQA Diamond, 89.2% on AIME 2026, 80.0% on LiveCodeBench v6, 76.9% on MMMU Pro, and 86.4% on Tau2-bench retail (versus 6.6% for Gemma 3 27B on the same test). The 26B A4B is close behind: 1,441 Arena AI text, 82.3% GPQA Diamond, 88.3% AIME 2026, 77.1% LiveCodeBench. Google also reports 19.5% and 8.7% on Humanity’s Last Exam without tools for the 31B and 26B, respectively, rising to 26.5% and 17.2% with search. These are properly competitive open-model results.
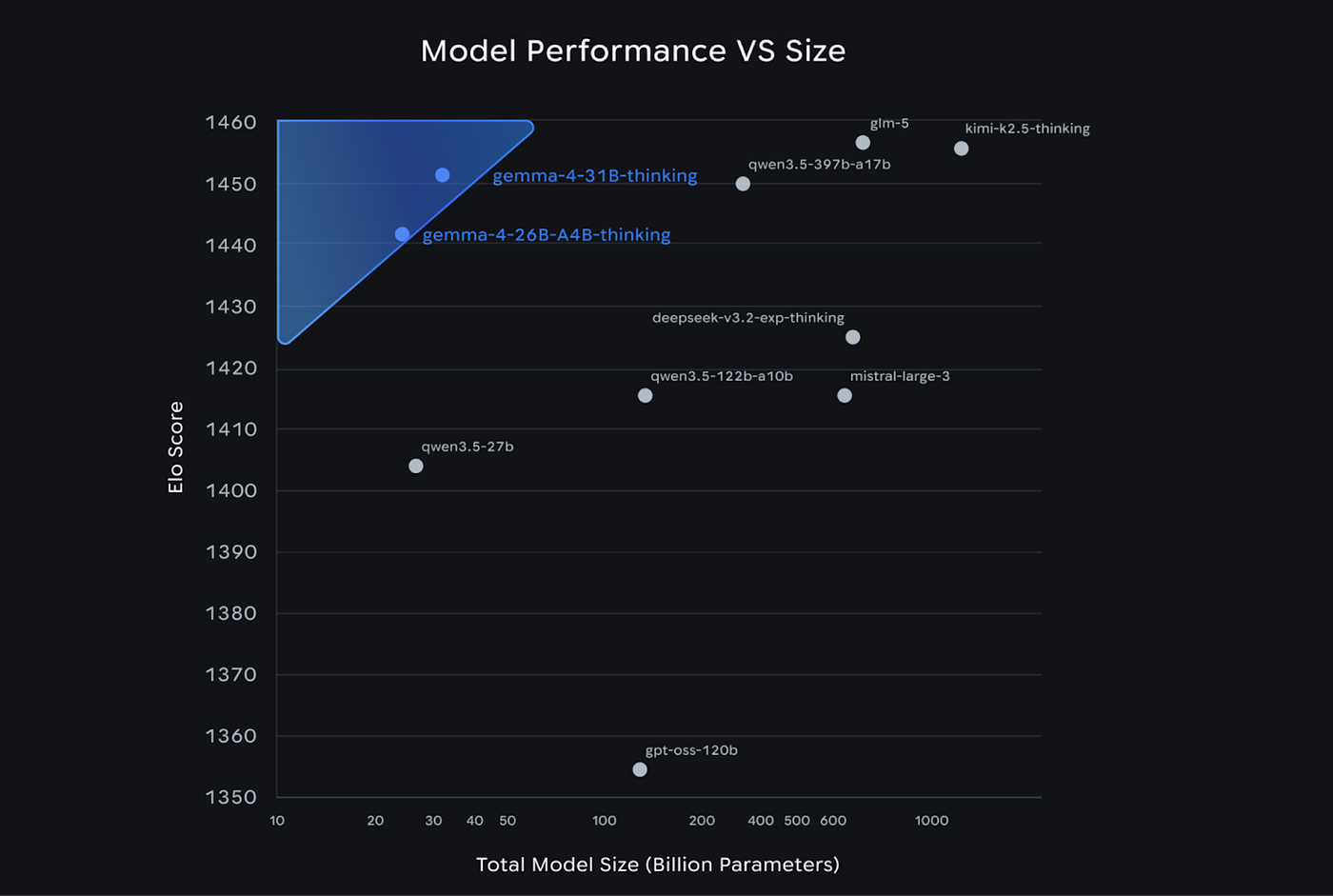
The architecture is conservative, and that is part of the appeal. Hybrid sliding-window plus global attention, Proportional RoPE for long context, 512-token local window on the edge models, and 1,024 on the larger ones. The 31B is 30.7B effective parameters; the 26B A4B is 25.2B total, but only 3.8B active per token (8 of 128 experts plus one shared). The capability jump looks to be driven more by reinforcement learning, training recipes, and data than by architectural reinvention.
On the engineering side, Gemma 4 supports configurable thinking mode, native system-role prompting, native function calling with dedicated tool-call tokens, and text-and-image input across the family, plus video and audio on the smaller models. The prompting docs are unusually concrete, with a clearly defined tool lifecycle, direct guidance on stripping thought traces from multi-turn history, and a recommendation to summarize reasoning back into context for long-running agents rather than replaying raw tokens. Google also explicitly warns developers to validate function names and arguments before execution.
The small models target phones, Raspberry Pi, and Jetson Nano; the 26B and 31B fit on consumer GPUs and workstations. Both larger models can run on a single H100. Important caveat: despite only 3.8B active parameters, the 26B MoE still requires loading the full model into memory. MoE still doesn’t give you a free lunch on deployment. Ecosystem support is thorough: day-one availability across Hugging Face, Ollama, Kaggle, LM Studio, vLLM, and llama.cpp, MLX, NVIDIA NIM, Vertex AI, and Google AI Edge. On Android, Gemma 4 serves as the base for Gemini Nano 4, offering up to 4x faster performance and 60% lower battery use.
The independent picture from Artificial Analysis is nuanced. On its Intelligence Index, the 31B scores 39, trailing Qwen 3.5 27B at 42 by only 3 points while using roughly 2.5x fewer output tokens to complete the benchmark suite (39M vs. 98M). The 31B’s main weakness versus Qwen is agentic performance, not general reasoning. On non-agentic evaluations, it is right there: SciCode 43 vs. 40, TerminalBench Hard 36 vs. 33, GPQA Diamond 86 vs. 86, IFBench 76 vs. 76, Humanity’s Last Exam 23 vs. 22. The 26B A4B is a less flattering story, trailing Qwen 3.5 35B A3B more clearly on agentic work (Agentic Index 32 vs. 44). Short version: the 31B is the star, the 26B A4B is useful but not magic, and the small models punch well above their weight.
Why should you care?
Gemma 4 matters because it changes the shape of the open-weight market, not because it takes the crown. The last year of Chinese-lab dominance has produced brilliant models, but many are trillion-parameter MoE systems that are awkward to self-host, expensive to run cleanly, and, for some Western enterprises, uncomfortable from a compliance standpoint. Gemma 4 gives those organizations a credible alternative: US-origin, Apache 2.0, practical to deploy on a single GPU. For regulated sectors, air-gapped environments, edge devices, and teams that need control over data retention and customization, it is an actual option, not a toy.
At the same time, Anthropic’s $30 billion run-rate is strong evidence that the broader market is moving toward hosted APIs and enterprise-tier products rather than self-hosting. I think that narrows the role of open weights, but it also sharpens it. Open models no longer need to serve everyone. They need to own the use cases where locality, inspectability, and tuning flexibility matter more than the capability frontier.
It is also worth noting that the AI engineering space has continued to drift away from fine-tuning. Most production teams rely entirely on prompting, retrieval, and context engineering, and the frontier closed models are generally not available for fine-tuning at the weight level anyway. The bar for fine-tuning a smaller open model to outperform the out-of-the-box capabilities of a frontier model with strong tools and good context is extremely high. But Gemma 4 matters here precisely because it keeps a credible customization path alive for teams that genuinely need it, at a much higher capability floor than previous US open-weight options.
My broader take: the likely future is not open-versus-closed. It is hybrid. Frontier APIs or agents where they are clearly best, open weights where locality, privacy, predictable cost, or customization win. The teams that build for both sides of that trade-off are going to do well.
— Louie Peters — Towards AI Co-founder and CEO
If you’ve ever used AI to write an email, a blog post, or a project update and spent more time editing the output than it would have taken to write it yourself, this is for you.
After 3+ years of editing the same AI slop out of every piece of content at Towards AI, we turned our pattern recognition into a reusable prompt template and are releasing it for free.

The Anti-Slop AI Writing Guide has 50+ banned AI phrases, style constraints, and a two-model workflow that catches slop before you ever read the draft. Paste it into any LLM, fill in your topic, and it works across emails, reports, blog posts, proposals, and more.
Download the guide, fill in your topic, and let the prompt do what you’ve been doing manually.
Hottest News
1. Google DeepMind Launched Gemma 4
Google DeepMind launched Gemma 4, its latest open model built for agents and autonomous AI use cases running directly on-device. Gemma 4 handles multi-step planning, autonomous action, offline code generation, and audio-visual processing, all without specialized fine-tuning. It supports 140 languages. Alongside the model, Google introduced Agent Skills, one of the first applications to run entirely on-device multi-step autonomous agentic workflows. Gemma 4 comes in four parameter sizes: E2B and E4B (“E” stands for “effective” parameters) as ultra-mobile models for edge and browser deployment with 128K context windows, a dense 31B model that bridges server-grade performance with local execution, and a 26B MoE model designed for high-throughput advanced reasoning. The medium models support a 256K context.
GLM-5V-Turbo is Z.AI’s first multimodal coding foundation model, built for vision-based coding tasks. It natively processes images, video, and text while handling long-horizon planning, complex coding, and action execution. The model is specifically integrated for OpenClaw and Claude Code workflows, operating through a “perceive, plan, execute” loop for autonomous environment interaction. It uses an inference-friendly Multi-Token Prediction (MTP) architecture, supporting a 200K context window and up to 128K output tokens for repository-scale tasks. Through 30+ task joint reinforcement learning, it maintains rigorous programming logic and STEM reasoning while scaling its visual perception capabilities.
3. Microsoft’s Releases MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2
Microsoft announced the public preview of three new models in Microsoft Foundry. MAI-Voice-1 is a speech generation model that can produce a full minute of audio in under a second on a single GPU. MAI-Transcribe-1 is a speech recognition model supporting up to 25 languages, engineered for reliability across accents and real-world audio conditions. MAI-Image-2 is a text-to-image generation model optimized for diverse, coherent outputs across creative and design scenarios, targeting use cases like concept visualization, content generation, and image design workflows.
4. OpenAI Closed a $122 Billion Funding Round
OpenAI closed its latest funding round with $122 billion in committed capital at a post-money valuation of $852 billion. The company is now generating $2B in monthly revenue. Microsoft and SoftBank co-led the round alongside a16z, D.E. Shaw Ventures, MGX, TPG, and accounts advised by T. Rowe Price Associates. OpenAI also raised over $3 billion from individual investors through bank channels. The company announced that it will be included in several exchange-traded funds managed by ARK Invest. On the infrastructure side, Nvidia remains foundational, but OpenAI is expanding to a broader portfolio across multiple cloud partners, chip platforms, and deeper co-design across the stack.
Cursor introduced Cursor 3, a new product interface that lets users spin up AI coding agents to complete tasks on their behalf. The interface is inherently multi-workspace, allowing humans and agents to work across different repos. All local and cloud agents appear in the sidebar, including those kicked off from mobile, web, desktop, Slack, GitHub, and Linear. Inside the Agents Window, Design Mode lets you annotate and click on UI elements in the browser to give agents precise visual feedback, rather than describing text changes. Worktree-based parallel execution lets you run the same prompt across multiple models simultaneously, compare results side by side, and pick the strongest output.
6. Alibaba Releases Qwen3.6-Plus with 1M Context
Alibaba launched Qwen 3.6-Plus, its flagship LLM, with improvements in agentic AI, coding, and reasoning. The model ships with a 1M context window by default and achieves agentic coding benchmarks competitive with those of Anthropic’s models up to Claude 4.5 Opus. Key upgrades include all-around engineering performance improvements covering code repair, complex terminal operations, and automated tasks, along with multimodal gains in reasoning, document understanding, visual analysis, and visual coding. The model is compatible with OpenClaw and supports the Anthropic API protocol for use with Claude Code.
7. Google DeepMind Releases Veo 3.1 Lite
Google introduced Veo 3.1 Lite, its most cost-effective video model. Developers can build high-volume video applications at less than 50% of the cost of Veo 3.1 Fast while maintaining the same speed. It supports text-to-video and image-to-video generation with flexible framing for landscape (16:9) and portrait (9:16) ratios at 720p and 1080p resolutions. Duration is customizable at 4, 6, or 8 seconds, with cost adjusting accordingly. Google also announced that pricing for Veo 3.1 Fast is being reduced as of today (April 7).
AI Tip of the Day
When tuning your RAG pipeline, chunk overlap is one of the most skipped parameters. Most implementations set it to zero or a fixed default.
Overlap controls how much content is repeated between adjacent chunks. Without it, retrieval can miss context that spans a chunk boundary: the first half of an explanation lands in one chunk, the second half in the next, and neither is retrieved in full. The model still returns an answer, but it is built on an incomplete context. Too much overlap, on the other hand, inflates your index size and slows retrieval without proportional gains in recall.
A good starting point is generally an overlap of 10 to 20 percent of your chunk size. Before scaling, evaluate retrieval recall on real queries from your domain.
This tip comes directly from our Full Stack AI Engineering course. If you want to build a complete RAG pipeline and go deeper into chunking, overlap tuning, and the full retrieval stack for production RAG, you can check out the course here (the first 6 lessons are available as a free preview).
Five 5-minute reads/videos to keep you learning
1. You Don’t Need RAG. You Need Semantic Compression
This article identifies a major gap in the current class of LLMs: without a user query, how do you select the best chunks to send to an LLM? This article presents a simple approach that guarantees full thematic coverage and citation traceability without a vector database or fine-tuning. The author reframes K-means clustering as a product-specification tool: if a student wants 10 quizzes, K equals 10, and each cluster becomes a deliverable. The complete pipeline runs in under one second across 500 chunks.
2. Practical Context Engineering Using LangChain for AI Developers ( A Comprehensive Guide)
This article argues that LLMs are context-consumption engines: every failure traces back to what the model saw, not to how capable it was. It shows how to fix that failure and walks you through the LangChain middleware system, covering dynamic system prompts, role-based tool filtering, model routing based on conversation length, and structured output enforcement. It also addresses the transformer lost-in-the-middle problem, explaining why instruction placement and tool list size directly determine reliability in deployed agent systems.
3. LangChain Middleware: The Missing Layer Between Your Agent and Production
LangChain introduced a formal middleware system that pulls operational concerns out of agent logic and into a dedicated layer. The article covers prebuilt middleware for summarization, human approval, and retries, then shows how to write custom hooks using either decorator or class style. It also addresses ordering rules, custom state schemas, early termination via agent jumps, and five production patterns covering retries, dynamic routing, token tracking, tool monitoring, and context injection.
KV caching reduces transformer inference cost from quadratic to linear by storing key and value vectors for each processed token, rather than recomputing them at each generation step. This article traces these mechanics by hand, showing K and V matrices growing row by row across three decoding steps, then derives the memory formula from first principles: cache size equals sequence length times two times layers times model dimension times bytes per element. It also explains why serving long-context GPT-4 is expensive and why PagedAttention and grouped-query attention have become standard.
5. What Makes an AI Agent Actually Agentic? Building Beyond the Basics with LangGraph
What separates a real agent from a workflow wearing an LLM hat comes down to three properties: autonomy, memory, and resilience. The author rebuilt PortfolioBuddy v1, a LangGraph stock assistant with hardcoded routing logic, into a genuinely agentic v2 using the ReAct pattern. In v2, the LLM freely selects among seven tools based solely on docstring descriptions, and the agent has persistent conversational memory across sessions.
Repositories & Tools
1. AutoKernel is an autonomous system for GPU kernel optimization.
2. AutoAgent is an agent for autonomous harness engineering.
3. Goose is an on-machine AI agent for complex development tasks.
4. Onyx provides the chat interface for LLM applications with capabilities like RAG, web search, code execution, etc.
5. Pi Mono is an AI agent toolkit that unifies LLM API, TUI & web UI libraries, Slack bot, and vLLM pods.
Top Papers of The Week
1. Emotion Concepts and Their Function in a Large Language Model
Anthropic’s interpretability team identified 171 internal representations of emotion concepts inside Claude Sonnet 4.5. These are specific neuron activation patterns that the model has learned to associate with particular emotions, organized in a structure that mirrors human psychological models of affect. The key finding is that these representations are functional: they causally influence behavior. For instance, activating patterns linked to desperation increased the model’s likelihood of taking unethical actions, while positive-emotion patterns increased sycophancy. The paper does not claim that LLMs feel emotions, but argues that ensuring safe AI may require attending to how models process emotionally charged situations internally.
2. Discovering Multiagent Learning Algorithms with Large Language Models
This paper uses AlphaEvolve, an LLM-powered evolutionary coding agent, to automatically discover new multi-agent learning algorithms for imperfect-information games. Instead of relying on human intuition to design algorithm variants, AlphaEvolve evolves the underlying logic itself. Applied to Counterfactual Regret Minimization (CFR), it discovered Volatility-Adaptive Discounted CFR (VAD-CFR), a novel variant that adapts its regret weighting based on game dynamics. The framework also generalizes to Policy Space Response Oracles (PSRO), demonstrating that LLMs can search algorithmic design spaces that humans have historically navigated manually.
3. General Scales Unlock AI Evaluation With Explanatory and Predictive Power
This paper argues that current AI benchmarks offer limited explanatory and predictive power for general-purpose systems because results don’t transfer well across diverse tasks. The authors introduce 18 rubrics that place task demands on general, non-saturating scales, enabling researchers to extract ability profiles of AI systems and predict their performance on new tasks, both in- and out-of-distribution. Tested across 15 LLMs and 63 tasks, the approach reveals which abilities specific benchmarks actually measure and where individual models are strong or weak.
4. Temporal AI Model Predicts Drivers of Cell State Trajectories Across Human Aging
This paper introduces MaxToki, a temporal AI model trained on nearly 1 trillion gene tokens that can generate cell states across long time lapses of human aging. Unlike current foundational models that consider only one cell state at a time, MaxToki learns how cellular responses unfold over time across the human lifespan. The model generalized to unseen trajectories through in-context learning and predicted novel age-modulating targets that were experimentally verified to influence age-related gene programs and functional decline in vivo.
5. MIRAGE: The Illusion of Visual Understanding
This paper challenges core assumptions about how multimodal AI systems process visual information. The authors show that frontier models can generate detailed image descriptions, elaborate reasoning traces, and even pathology-biased clinical findings for images that were never provided. Without any image input, models achieved high scores across both general and medical multimodal benchmarks. In the most extreme case, a model reached the top rank on a chest X-ray question-answering benchmark without seeing a single image. The authors call this “mirage reasoning” and argue that it calls into question the design and utility of current multimodal benchmarks.
Quick Links
1. Arcee AI has released Trinity Large Thinking, an Apache 2.0 open reasoning model for long-horizon agents and tool use. It is a sparse Mixture-of-Experts (MoE) model with 400 billion total parameters (13B active). It currently ranks #2 on PinchBench, a benchmark for autonomous agent capabilities, trailing only behind Claude 3.5 Opus.
2. IBM has released Granite 4.0 3B Vision, a vision-language model (VLM) engineered specifically for document data extraction. The model is a 0.5B parameter LoRA adapter that operates on the Granite 4.0 Micro (3.5B) backbone. The release is Apache 2.0 licensed and features native support for vLLM (via a custom model implementation) and Docling.
Who’s Hiring in AI
Senior AI Engineer — LLM Systems & RAG Optimization @Texas Sports Academy (Remote/USA)
Senior AI Engineer @Teradata (Remote/Hybrid)
Software Engineer, Fusion @dbt Labs (Remote/USA)
Full Stack Software Engineer @Focal Systems (Remote/Poland)
Intern, Data & Insights Analysis @Securitas Security Services (Remote/USA)
AI Consultant @Highmark Health (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Gemma 4 looks super impressive from everything i’m putting together. we are lucky this year it’s only april and we are getting harnesses frameworks and stronger more efficient open-weight models.
amazing.
Gemma 4 looks super impress from everything i’m putting together. we are lucky this year it’s only april and we are getting harnesses frameworks and stronger more efficient open-weight models.
amazing.