
TAI #198: Real-Time Speech AI Gets Serious: Google and OpenAI Race to Own the Voice Layer
Also, Cohere Transcribe, Sora cancelled, TRIBE v2, and more!



What happened this week in AI by Louie
Real-time speech AI has been progressing quietly for the past year, but the past few weeks have delivered enough to warrant a dedicated look. Google released Gemini 3.1 Flash Live on March 26, OpenAI shipped GPT-Realtime-1.5 on February 23, and Cohere launched its Apache 2.0-licensed Transcribe model the same day as Google. We are now past the point where real-time voice AI feels like a demo-stage curiosity. It is starting to look like deployable infrastructure, and headline audio pricing has fallen sharply since OpenAI’s original Realtime API launch in October 2024.
Google’s Gemini 3.1 Flash Live is the headline release. It is Google’s highest-quality real-time audio model, designed for voice-first agents that can reason, call tools, and hold natural conversations across 70 languages. It accepts audio, video, text, and image input, supports function calling with Google Search grounding and extended thinking, and is available in developer preview via the Gemini Live API.
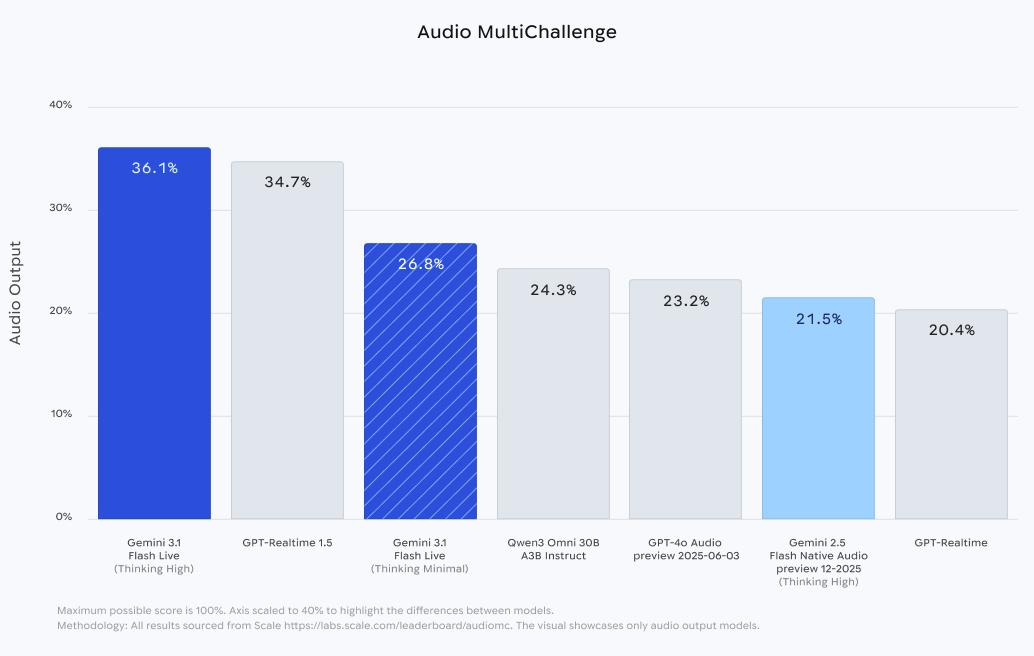
The benchmarks are strong. On ComplexFuncBench Audio, which tests multi-step function calling, Gemini 3.1 Flash Live leads with 90.8% compared — a big step up from 71.5% on the prior Flash 2.5 model. On Scale AI’s AudioMultiChallenge, which tests instruction-following amid real-world interruptions and hesitations, Gemini scores 36.1% with thinking enabled, compared to GPT-Realtime-1.5 at 34.7%. On BigBenchAudio for reasoning, Gemini reaches 95.9% with high thinking, compared to GPT-Realtime-1.5 at 81.1%. The catch is that these top Gemini scores require extended thinking, which adds latency. With minimal thinking, Gemini drops to 70.5% on BigBenchAudio and 26.8% on AudioMultiChallenge, both below GPT-Realtime-1.5. The reasoning-versus-latency trade-off is now a live engineering decision, not a footnote.
Google has also improved tonal understanding, with the model recognizing pitch, pace, frustration, and confusion and adjusting its responses accordingly. Enterprise customers, including Verizon, LiveKit, and The Home Depot, have tested 3.1 Flash Live. The Home Depot highlighted the model’s ability to capture alphanumeric product codes in noisy environments and handle customers switching languages mid-conversation.
OpenAI’s GPT-Realtime-1.5 looks strongest on conversational dynamics and transport options rather than on raw reasoning benchmarks. Artificial Analysis currently gives it a 95.7% Conversational Dynamics score and a 0.82-second time-to-first-audio. The same benchmark page lists Gemini 3.1 Flash Live at 2.98 seconds with high thinking and 0.96 seconds with minimal thinking. In practice, GPT-Realtime-1.5 should feel snappier in live conversation, while Gemini scores higher on published reasoning benchmarks.
A key operational improvement in GPT-Realtime-1.5 is OpenAI’s reported 10.23% gain in alphanumeric transcription accuracy. That matters because phone numbers, order IDs, and product codes are where voice systems often fail. OpenAI also supports WebRTC, WebSocket, and SIP for Realtime, which gives developers a direct path into browser, server, and telephony stacks. Perplexity says it already uses Realtime-1.5 in production for millions of voice sessions each month.
They are not the only players, either. Step Audio R1.1 out of China is a notable contender in the speech-to-speech space, winning on several benchmarks at very competitive pricing. Grok’s Voice Agent also remains in the running. The field is getting crowded fast.
The pricing tells an important story, but it is worth being precise about what is being compared: raw audio model cost, not total application cost. OpenAI documents audio tokenization at 1 token per 100 milliseconds for user audio and 1 token per 50 milliseconds for assistant audio. At $32 per million audio input tokens and $64 per million audio output tokens, that works out to roughly $0.096 per minute of two-way audio before text tokens, grounding, or telephony. Google publishes direct per-minute equivalents for Gemini 3.1 Flash Live Preview: $0.005 per minute of audio input and $0.018 per minute of audio output, or a total of $0.023 per minute. That makes Google about 4.2x cheaper on headline audio rates, although the model remains in preview and Google notes that preview models may change and may have tighter rate limits.
Another development that shows what this all unlocks is Google Live Translate. On March 26, Google expanded real-time headphone translation to iOS and additional countries, including France, Germany, Italy, Japan, Spain, Thailand, and the UK. The feature works with any headphones, supports 70+ languages, and preserves the original speaker’s tone and cadence. This is the closest thing to a universal translator that exists today. Five years ago, it was science fiction. Now it runs on a phone with any pair of earbuds. Google Meet’s speech translation beta extends this into professional settings, translating your speech in real time “in a voice like yours.” Search Live expanded to over 200 countries this week. The direction is clear: multilingual voice interaction is becoming a default capability, not a premium feature.
The cost trajectory reinforces this. In late 2024, OpenAI’s original Realtime API priced audio input at $100 per million tokens. GPT-Realtime brought that to $32. Gemini 3.1 Flash Live enters at $3 (albeit with different tokenisation), with a free tier. That’s a huge cost reduction in under two years.
Cohere also contributed this week from a different angle. Cohere Transcribe is not a conversational model but a dedicated automatic speech recognition (ASR) system: 2 billion parameters, conformer-based, 14 languages, Apache 2.0. It ranks first on the Hugging Face Open ASR Leaderboard with an average word error rate (WER) of 5.42%, ahead of Zoom Scribe v1 at 5.47% and OpenAI Whisper Large v3 at 7.44%, and processes audio at 525x real-time. For enterprises in healthcare, legal, finance, or government that cannot send audio to third-party cloud APIs, this is the most important release of the week. Open weights, consumer-GPU-sized, and zero licensing cost.
On a personal note, one of my favourite audio-based AI tools right now is Granola. It captures high-quality transcripts of your computer audio and calls with minimal setup, and then lets you run top models over those transcripts to produce call summaries or fully cleaned-up notes. It’s the kind of product that shows where this whole space is heading: speech capture and understanding becoming an ambient background layer in everyday work.
Why should you care?
Speech is becoming a first-class modality because it maps onto existing behaviors in search, meetings, support, and translation. A model that can reason over spoken language in real time, handle interruptions cleanly, call tools, and switch languages has a much clearer route into daily workflows than a text-only chatbot.
The live translation thread is perhaps the most important long-term signal. Google Live Translate, expanding to iOS with 70+ languages and tone-preserving headphone translation, is a capability people have been waiting for for decades. When this moves into Google Meet (already in beta), into contact centers, and eventually into the Gemini API for any developer to build on, the number of human interactions it can reshape is enormous. This would allow, for example, a doctor consulting with a patient across a language barrier without waiting for an interpreter. Or a multinational meeting where nobody is forced into English.
I expect we’ll see speech-first interfaces become standard across customer support, education, healthcare, and accessibility within the next 12 to 18 months. The cost barrier is gone. The accuracy is reaching production thresholds. The remaining challenge is that voice naturalness still varies by language, inference and reasoning introduces some delay, and benchmarks still miss domain vocabulary and emotional nuance. So the right approach is still human evaluation on your own recordings and accents, together with easy escalation to a real human operator, not blind faith in a leaderboard.
— Louie Peters — Towards AI Co-founder and CEO
We have co-published an article with Paul Iusztin, covering the mental model that prevents you from overengineering your next AI system.
Here is what you will learn:
The fundamental difference between an agent and a workflow.
How to use the complexity spectrum to make architecture decisions.
When to rely on simple workflows for predictable tasks.
Why a single agent with tools is often enough for dynamic problems.
The exact breaking points that justify moving to a multi-agent system.
Hottest News
1. OpenAI Scraps Sora Video Platform Months After Launch
OpenAI has shut down Sora, its AI video-generation app, less than two years after it generated widespread attention for creating realistic clips from simple text prompts. Alongside the shutdown, OpenAI is also winding down its $1B content partnership with Disney. The company says it’s shifting focus to developments like robotics “that will help people solve real-world, physical tasks.” For context, Sora pulled in just $1.4M in global net in-app revenue since launch, compared to $1.9B for ChatGPT over the same period.
2. Anthropic Rolls Out Computer Use Capabilities
Anthropic now lets Claude directly use your computer to complete tasks. When Claude doesn’t have access to the tools it needs, it will point, click, and navigate your screen, opening files, using the browser, and running dev tools without any setup. The feature is available in research preview for Claude Pro and Max subscribers, and also works with Dispatch, which lets you assign Claude tasks from your phone. On the safety side, the system automatically scans model activations to detect risky behavior, Claude always asks permission before accessing new applications, and you can stop it at any point.
Google’s research team has introduced TurboQuant, a compression algorithm that reduces LLM key-value cache memory by 6x and delivers up to 8x speedup, with zero accuracy loss. TurboQuant is “data-oblivious,” so it doesn’t require dataset-specific tuning or calibration. It’s also designed to work smoothly with modern GPUs by using vectorized operations instead of slow, non-parallelizable binary searches. Under the hood, it uses a two-stage approach: MSE-optimal quantization followed by a 1-bit QJL transform on the residual, providing unbiased inner-product estimates that are critical for maintaining transformer attention accuracy.
4. Google Releases Gemini 3.1 Flash Live
Google has released Gemini 3.1 Flash Live in preview for developers through the Gemini Live API in Google AI Studio. The model targets low-latency, more natural real-time voice interactions. It uses WebSockets (WSS) for full-duplex communication, supporting barge-in (user interruptions) and simultaneous transmission of audio, video frames, and transcripts. The model is also optimized for triggering external tools directly from voice, scoring 90.8% on ComplexFuncBench Audio for multi-step function calling.
5. Cohere AI Launches Cohere Transcribe
Cohere has released Cohere Transcribe, an automatic speech recognition (ASR) model built on a large Conformer encoder paired with a lightweight Transformer decoder. To maintain memory efficiency and stability, it uses native 35-second chunking logic, automatically segmenting longer audio into overlapping chunks and reassembling them, enabling it to handle extended recordings without performance degradation. The model supports 14 languages and currently ranks #1 on the Hugging Face Open ASR Leaderboard (as of March 26, 2026) with an average Word Error Rate of 5.42%.
Meta has released TRIBE v2, a tri-modal foundation model that serves as a digital mirror of human brain activity in response to visual, auditory, and linguistic stimuli. It uses state-of-the-art encoders such as LLaMA 3.2 for text, V-JEPA2 for video, and Wav2Vec-BERT for audio to capture features that are shared between AI models and the human brain. TRIBE v2 can accurately predict brain responses to new stimuli, tasks, and subjects without retraining, achieving 2–3x improvement over standard methods on auditory and visual datasets. A subject-specific layer maps universal learned representations onto individual fMRI voxels, the 3D pixels that track neural activity through changes in blood flow and oxygenation.
AI Tip of the Day
To ensure your RAG retrieval is working correctly, split your evaluation into two layers. For retrieval, measure whether relevant evidence was retrieved using metrics like recall@k and Mean Reciprocal Rank. For generation, measure faithfulness to the retrieved context and the answer’s relevance to the question, often using an LLM judge calibrated against human labels.
High retrieval recall with low faithfulness suggests the model had the right evidence, but failed to use it properly. High faithfulness with low retrieval recall suggests the model stayed grounded in the retrieved context, but retrieval surfaced incomplete or off-target evidence. These are two completely different problems with two completely different fixes, and without the split, you can’t tell which one you’re dealing with.
If you’re currently building a RAG pipeline and want to go deeper into evaluation, retrieval strategies, and the full production stack, check out our Full Stack AI Engineering course.
Five 5-minute reads/videos to keep you learning
1. Vectorless RAG: Your RAG Pipeline Doesn’t Need a Vector Database
Vectorless RAG reasons about where in the document the answer lives, the same way a human expert would, instead of searching for similar text. This article explains the concept, where it outperforms traditional RAG, and how to build it using PageIndex, an open-source library that implements it in about 50 lines of Python.
2. Exploration and Exploitation: The Simple Yet Profound Logic at the Heart of Reinforcement Learning
The exploration-exploitation trade-off of reinforcement learning mirrors a fundamental human dilemma: stick with what works or try something new. This article walks through the core mechanics, covering ε-greedy strategies, Upper Confidence Bound, and Thompson Sampling as progressively smarter approaches to balancing exploration and exploitation. It also extends the logic to full RL via Q-learning and value functions.
3. Building a Data Analysis Agent with LangGraph
This article walks you through building a data analysis agent with LangChain, LangGraph, and GPT-4o-mini. This agent autonomously investigated Singapore Airbnb data, surfacing three validated findings across four iterations. The system pairs four single-responsibility agents with six pandas tools, using conditional routing and a loop to let the agent decide when to stop rather than the developer. It also covered governance alignment with Singapore’s IMDA framework, metric honesty, and one hard lesson: prompt instructions cannot enforce behavior. Code can.
4. MCP + A2A + OWL Ontology: I Built the Agentic Mesh Your Enterprise Agents Are Missing
This article walks you through building an Agentic Mesh that includes MCP for tool access, OWL and SHACL for shared semantic contracts, and Google’s A2A protocol for validated agent communication. SHACL constraints block invalid data from crossing agent boundaries, while A2A Agent Cards advertise each agent’s ontology version.
5. Microsoft IQ vs. ServiceNow: I Built the Layer Both Are Missing
Microsoft IQ and ServiceNow’s AI Control Tower tackle enterprise AI governance from opposite ends: one defines business semantics across a three-tier intelligence layer, the other governs every agent through a vendor-agnostic control plane. The article argues that both miss the point of runtime determinism. Using OWL ontologies and SHACL constraints, the piece builds an ontology firewall that intercepts MCP tool calls and blocks semantically invalid agent actions before they reach production.
Repositories & Tools
1. Superpowers is a complete software development workflow for coding agents, built on top of composable “skills”.
2. A-Evolve is a universal infrastructure for self-improving agents that works with any evolution algorithm.
3. AIO Sandbox is an all-in-one agent sandbox environment that combines Browser, Shell, File, MCP operations, and VSCode Server in a single Docker container.
4. ProRLAgent Server is a scalable multi-turn rollout system for training and evaluating RL agents.
5. Covo-Audio is a 7B-parameter end-to-end large audio language model that directly processes continuous audio inputs and generates audio outputs within a single unified architecture.
Top Papers of The Week
1. TurboQuant: Near-Optimal Online Vector Quantization
This paper introduces TurboQuant, a data-oblivious vector quantization algorithm that achieves near-optimal distortion rates across all bit-widths by randomly rotating inputs and applying optimal scalar quantizers to each coordinate. KV cache quantization achieves absolute quality neutrality at 3.5 bits per channel and marginal quality degradation at 2.5 bits per channel.
2. Voxtral TTS
Voxtral TTS is a multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. It combines autoregressive generation of semantic speech tokens with flow matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch. In human evaluations conducted by native speakers, it achieves a 68.4\% win rate over ElevenLabs Flash v2.5.
3. MSA: Memory Sparse Attention Scales End-to-End to 100M Tokens
This paper presents Memory Sparse Attention (MSA), a trainable, massively scalable memory-model framework. MSA achieves linear complexity in both training and inference while maintaining stability, exhibiting less than 9% degradation when scaling from 16K to 100M tokens. Furthermore, KV cache compression, combined with Memory Parallel, enables 100M-token inference on 2xA800 GPUs.
4. OpenResearcher: Fully Open Pipeline for Deep Research Trajectory Synthesis
This paper introduces OpenResearcher, a reproducible pipeline that decouples one-time corpus bootstrapping from multi-turn trajectory synthesis and executes the search-and-browse loop entirely offline using search, open, and find over a 15M-document corpus. They synthesized 97K+ trajectories and achieved a 30B model that scored 54.8% on BrowseComp-Plus (+34 points over the base).
5. Agentic AI and The Next Intelligence Explosion
This paper challenges the idea of a monolithic AI singularity, arguing instead that future transformative intelligence will emerge from complex, socially organized interactions among multitudes of AI agents and humans. The authors emphasize that building scalable, cooperative “agent institutions” and constitutional checks and balances is critical for safely managing the combinatorial explosion of intelligence.
Quick Links
1. Chroma releases Context-1, a 20B parameter agentic search model designed to act as a specialized retrieval subagent. By focusing solely on retrieval, Context-1 achieves 10x faster inference and 25x lower costs than frontier models like GPT-5.4, while matching their accuracy on complex benchmarks like HotpotQA and FRAMES.
Who’s Hiring in AI
DevOps and Build Engineer — Compiler @NVIDIA (India)
Application Systems Engineering Manager @Gusto, Inc. (New York, NY, USA)
Staff AI Engineer — AI Creator @DataCamp (Belgium/Dubai/Portugal/UK/USA)
Embedded AI Solutions Engineer @Correlation One (Remote/NAMER)
Middle Python Engineer, Document App @PandaDoc (Remote/Poland)
Research Engineer @Turing (Remote/Columbia)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.