
TAI #197: Anthropic Turned the OpenClaw Demand Signal Into a Product
Also, Jensen Huang on $1 trillion revenue, Elon Musk launches Terafab, Cursor’s Composer 2 rides Kimi K2.5, and more!



What happened this week in AI by Louie
Last week, I wrote about quiet agent upgrades. This week, Anthropic continued to launch features that make the bigger picture obvious. In ten weeks, it went from launching Cowork (January 12) to shipping persistent phone-to-desktop threads via Dispatch (March 17) and direct computer use (March 23), adding plugins, admin controls, and scheduled tasks along the way. A paid Claude Cowork user can now message an agent from their phone, let it work on their machine, connect it to dozens of apps, and hand it the mouse to the full computer when connector or API access isn’t available. OpenClaw, at roughly 333,000 GitHub stars, did the product discovery. Anthropic built and shipped many of its key features at an incredible pace (only possible by using Claude Code itself to build features!), but with a much more enterprise-friendly risk profile: connectors first, explicit per-app permissions, prompt-injection scanning, and admin controls. Open source found the primitive. Anthropic wrapped it in the permission model that lets a company actually deploy it.
The agent story feeds directly into the AI infrastructure debate that dominated the rest of the week. Computer use, browser control, and persistent background tasks are dramatically more token-intensive than chat. A single Cowork session running scheduled tasks, clicking through apps, and filling spreadsheets burns far more compute than a conversation. Every new agentic workflow Anthropic or anyone else ships multiplies the demand per user. That is part of why the people at the top of the AI stack sound increasingly frustrated with the pace of supply expansion further down.
At GTC, Jensen Huang said Nvidia expects at least $1 trillion in cumulative Blackwell and Rubin revenue through 2027, then clarified that this estimate was conservative because it excluded additional products. On the All-In podcast, he called Dario Amodei’s forecast of roughly $1 trillion in non-infrastructure AI revenue by 2030 “very conservative,” adding that Anthropic will do “way better than that” because every enterprise software company will become a value-added reseller of model tokens. I suspect Jensen is also privately nervous about the supply chain’s willingness to ramp as aggressively as his demand forecasts require. His current approach has been to invest directly in suppliers to force capacity expansion: Nvidia recently committed $4 billion to optical interconnect suppliers Coherent and Lumentum to address the silicon photonics bottleneck, and on the February earnings call, management described supporting the “extreme ecosystem” of suppliers from a capacity standpoint as one of the company’s most important priorities.
The further down the supply chain you go, the fewer people believe those numbers. Broadcom said today that TSMC has become a production bottleneck, with meaningful new capacity not materializing until 2027, and that the squeeze now extends beyond wafers into lasers and printed circuit boards. Memory prices in some segments have more than tripled over the past year. Samsung is pushing customers toward three- to five-year contracts to justify expansion. The top of the stack is trying to force conviction into the middle, and the middle is still hesitant to invest at the scale implied by demand forecasts.
That backdrop makes Elon Musk’s Terafab announcement easier to parse. Tesla and SpaceX plan a joint chip fabrication complex in Austin, starting with an initial $20–25 billion facility, though the full project at the scale Musk described would cost dramatically more. At full capacity, Terafab would target 1 terawatt of annual compute output, compared with roughly 0.5 terawatt for the entire current U.S. electricity network. Musk said every fab on Earth currently produces about 2% of what his companies would eventually need, and that 80% of Terafab’s output would be directed toward orbital data centers in space. These numbers really only make sense if AI leads to a large multiplication of the global economy from current levels.
The pieces Musk already has are real but partial. Tesla’s chip team has been designing custom AI chips for years, with AI5 targeting production in 2027 and AI6 in 2028. Samsung plans to begin volume fabrication of Tesla chips in Texas in the second half of 2027. SpaceX is building what will be the largest PCB and panel-level packaging facility in North America at its Bastrop site, backed by a $280 million-plus Texas semiconductor innovation grant. Musk is also recruiting aggressively, posting on X that anyone in Korea working in chip design, fabrication, or AI software should apply to Tesla, in what looks like a direct play for TSMC and Samsung talent.
What Musk lacks is any experience running an actual fabrication plant. The gap between chip design plus advanced packaging and full-scale leading-edge lithography is enormous. TSMC has roughly 50,000 engineers who do nothing but fab operations, and it has spent decades and hundreds of billions of dollars building that capability. The EUV lithography machines that any 2nm fab requires are made exclusively by ASML, which has a record backlog of roughly €39 billion and whose capacity is likely to be a key bottleneck for anyone trying to build a new leading-edge fab on an ambitious timeline. Each EUV machine costs $200–400 million, weighs 165 tons, and requires specialized ocean transport. There is no fast lane for procurement.
I suspect Terafab is partly a manufacturing project and partly a supply-chain pressure tactic, similar to Battery Day in 2020. Tesla presented the 4680 cell as a path to much lower battery costs and near-100x scale by 2030. The execution was painful: repeated delays in dry-electrode manufacturing, supplier pushback, and struggles at scale as late as 2023. Yet Tesla’s latest shareholder update says it is now producing 4680 dry-electrode cells with both anode and cathode in Austin, a real milestone after years of difficulty. The battery program shipped later and uglier than the slides implied, but it dragged Tesla and its suppliers up the curve. Terafab may serve a similar function even if the schedule slips badly, which I expect it will.
Google is fighting the same capacity war from a different angle, and energy is its primary lever. Alphabet acquired clean energy developer Intersect for $4.75 billion in December to gain direct access to power projects and data center infrastructure. Google has signed nuclear deals with Kairos Power for 500 MW of small modular reactors by 2035, a 25-year agreement with NextEra Energy to restart Iowa’s shuttered 615 MW Duane Arnold nuclear plant, a 200 MW deal with fusion firm Commonwealth Fusion Systems, and a strategic agreement with Elementl Power to develop three nuclear sites with at least 600 MW of capacity each. It has also been signing utility agreements to curtail up to 1 gigawatt of data-center power during peak periods. Ruth Porat said this week that the U.S. is not scaling up energy supply fast enough to support AI. Meanwhile, Meta signed a multi-billion-dollar deal to rent Google’s TPUs and was also discussing buying them outright, while Anthropic already has access to more than 1 gigawatt of Google TPU capacity.
Open weight models have been taking somewhat of a back seat to the breakthroughs in agentic capabilities at the closed AI labs the past few months, but I think open weights will still have a key role to play. Cursor released Composer 2, a coding model built on Moonshot AI’s Kimi K2.5 via an authorized commercial partnership through Fireworks AI. It scores 61.7 on Terminal-Bench 2.0 and 73.7 on SWE-bench Multilingual, up sharply from Composer 1.5, and is priced at $0.50 per million input tokens. Cursor did not initially disclose the Kimi base. A developer intercepted the API traffic and found the model ID in plain text. After millions of views, Cursor VP Lee Robinson acknowledged the open-source base, and co-founder Aman Sanger called the omission “a miss from the start.” The licensing story is clean; the disclosure story is not. But the product formula, take a strong open base, hammer it with domain-specific RL, wrap it in the best UX in the category, is very likely the template for application-layer competition over the next couple of years.
Why should you care?
The “AI bubble” framing keeps circulating and keeps missing the point. Bubbles feel overbuilt. Much of AI still feels under-supplied. Memory prices have tripled. TSMC is a bottleneck. Lasers and PCBs are in short supply. ASML’s EUV machines are booked out. Musk, Jensen, and Google are all signaling the same thing: there are not enough chips, power, or industrial capacity to support the scenarios the leading buyers seem willing to fund.
The ‘agent’ story makes this tension worse. Anthropic’s Cowork with computer use, Dispatch, and scheduled background tasks turns a single user into a persistent compute load. Every time an agent clicks through a browser, fills out a spreadsheet, or runs a recurring workflow, it burns far more tokens than a chat exchange does. Multiply that across millions of subscribers, then add Cursor’s long-horizon coding agents, OpenAI’s agent mode, and the broader wave of agentic products shipping every week, and you start to see why Jensen thinks $1 trillion is conservative. The revenue potential from agents is enormous, but the compute requirements per user are also enormous. Those two facts together explain the urgency behind Terafab, Google’s energy sprint, and Nvidia’s direct investments in its supplier base.
The gap between conviction at the top and hesitancy in the middle of the supply chain is a key dynamic in AI right now. The DRAM fabs, the PCB makers, the laser suppliers, and the power utilities are the ones whose investment pace will determine how fast AI actually scales. If the top-of-stack buyers are right, the hesitancy further down becomes the binding constraint. If they are wrong, Terafab will be a very expensive monument to overconfidence. The next two years will settle it. The people who get ahead will be the ones using the new tools before the supply catches up.
One final thought on the Terafab story: if you truly believe in recursive AI self-improvement without near-term dead ends, now is indeed the time to begin ambitious projects that wouldn’t have been possible previously. If AI can help simulate, iterate, and improve chip science and manufacturing, then those making the earliest and most aggressive moves to build an AI-first chip fab may indeed have a chance to leapfrog incumbents. This will also be the case in many other industries, and I expect many more pie-in-the-sky, ambitious projects to be launched soon by AI labs and true AI believers.
— Louie Peters — Towards AI Co-founder and CEO
This issue is brought to you thanks to SerpApi:

LLMs are powerful. But without fresh information, they can hallucinate or miss context.
SerpApi helps AI applications access real-time search data from search engines like Google, Bing, Amazon, and more via a simple API.
Get clean, structured JSON results and power AI agents, research tools, and data-driven applications without managing scrapers.
Start with 250 free credits/month by signing up at SerpApi today!
Hottest News
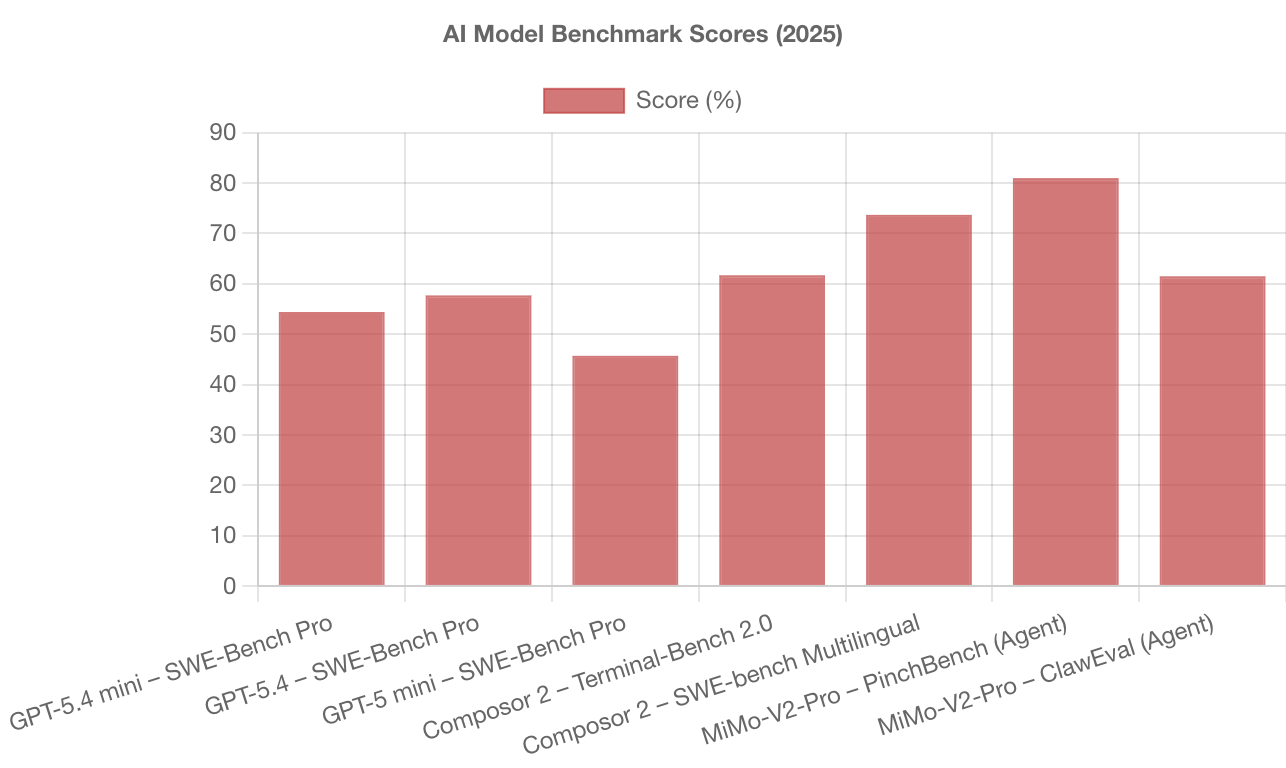
1. OpenAI Releases GPT-5.4 Mini and Nano
OpenAI released GPT-5.4 mini and GPT-5.4 nano, two smaller GPT-5.4 variants designed for high-throughput, latency-sensitive workloads such as coding assistants, sub-agents, and routine automation. GPT-5.4 mini is positioned as the default “workhorse” small model, faster than GPT-5 mini (OpenAI notes it runs over 2× faster) while improving coding, reasoning, multimodal understanding, and tool use. It lands close to the full GPT-5.4 model on several evals (for example, 54.4% on SWE-Bench Pro vs. 57.7% for GPT-5.4, and 45.7% for GPT-5 mini). In the API, mini supports text + image inputs, tool use/function calling, web search, file search, and computer use, with a 400K context window priced at $0.75/1M input tokens and $4.50/1M output tokens. GPT-5.4 nano is the smallest, lowest-cost option for simpler tasks like classification, ranking, extraction, and lightweight coding subagents; it’s API-only and priced at $0.20/1M input tokens and $1.25/1M output tokens. GPT-5.4 mini is also available across Codex surfaces and in ChatGPT, where it appears for Free/Go users via Thinking, with mini serving as a rate-limit fallback for GPT-5.4 Thinking on other plans.
2. Cursor Launches Composer 2, Coding Model Powered by Kimi-k2.5
Cursor released Composer 2, a frontier-level coding model priced at $0.50 per million input tokens, with a faster variant available. Built on Moonshot AI’s Kimi-k2.5 via continued pretraining and high-compute RL, it shows substantial benchmark improvements, including 61.7 on Terminal-Bench 2.0 and 73.7 on SWE-bench Multilingual. The model is available immediately in Cursor with usage included in individual plans. Kimi confirmed the authorized commercial partnership through Fireworks AI.
Mistral AI released Mistral Small 4, a unified open-source multimodal reasoning model, alongside Leanstral, an open-source code agent built for Lean 4 formal verification. Mistral Small 4 combines the roles of Mistral’s earlier specialist lines: reasoning, multimodal understanding, and agentic coding, into a single hybrid model tuned for general chat, coding, agent workflows, and deeper reasoning. Architecturally, it’s a Mixture-of-Experts system with 128 experts and 4 active per token, totaling 119B parameters, with roughly 6–6.5B parameters activated per token (about 8B including embedding and output layers), and it supports a 256K context window plus native text+image inputs. It also adds a configurable reasoning-effort control, allowing developers to trade off low-latency responses for more intensive reasoning. Mistral reports major efficiency gains versus Mistral Small 3, up to 40% lower end-to-end completion time in a latency-optimized setup and 3× higher requests-per-second in a throughput-optimized setup, and positions Small 4 (with reasoning enabled) as competitive on core reasoning/coding benchmarks while producing shorter outputs.
4. OpenAI and NVIDIA Sign $100B Infrastructure Partnership
OpenAI and NVIDIA announced a letter of intent for a strategic infrastructure partnership to deploy at least 10 gigawatts of NVIDIA systems to train and run OpenAI’s next generation of models. As deployments scale, NVIDIA plans to invest up to $100 billion in OpenAI progressively as each gigawatt is brought online, tying capital to delivered infrastructure. The companies set the first phase to come online in the second half of 2026, built on NVIDIA’s Vera Rubin platform. The partnership also includes joint roadmap work to co-optimize OpenAI’s model and infrastructure software with NVIDIA’s hardware and software stack.
5. Xiaomi Releases MiMo-V2-Pro
Xiaomi released MiMo-V2-Pro, its flagship foundation model built for real-world agentic workloads, positioning it as a “brain” for systems that orchestrate multi-step workflows and production engineering tasks. The model uses an efficient trillion-parameter MoE design with over 1T total parameters and 42B active parameters, scales long-context operation to a 1M-token window, and extends Xiaomi’s Hybrid Attention design by increasing the hybrid ratio from 5:1 to 7:1, with a lightweight multi-token prediction (MTP) layer to speed up generation. Xiaomi reports MiMo-V2-Pro ranks 8th worldwide and 2nd among Chinese LLMs on the Artificial Analysis Intelligence Index, and highlights stronger agent performance on OpenClaw-style evaluations (e.g., PinchBench avg. 81.0 and ClawEval 61.5, listed as #3 globally on both). The model was also publicly tested in stealth on OpenRouter under the name “Hunter Alpha,” where Xiaomi says it topped the daily call charts and surpassed 1T tokens in usage. The model is now available globally via Xiaomi’s developer portal MiMo Studio, Hugging Face, and its API platform.
6. NVIDIA Releases Nemotron-Cascade 2
NVIDIA released Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts model that activates only ~3B parameters per token, targeting high “intelligence density” for reasoning and agent workflows without the usual cost blowups. The flagship checkpoint is Nemotron-Cascade-2–30B-A3B, post-trained from Nemotron-3-Nano-30B-A3B-Base, and it runs in two operating modes, a thinking mode and a non-thinking (instruct) mode, selected through the chat template. NVIDIA reports that it is the second open-weight LLM (after DeepSeek-V3.2-Speciale-671B-A37B) to reach gold-medal–level performance across the 2025 IMO, IOI, and ICPC World Finals. The core training upgrade is multi-domain on-policy distillation throughout the Cascade RL pipeline, in which the best intermediate “teacher” for each domain provides token-level distillation signals to recover regressions and maintain gains across domains. NVIDIA also released the full collection of model checkpoints and training datasets alongside the paper.
7. Mamba-3: A New State Space Model Frontier
A team of researchers from Carnegie Mellon University (CMU), Princeton University, Together AI, and Cartesia AI has introduced Mamba-3. It is a new state space model (SSM) architecture designed for inference efficiency, shifting the focus from Mamba-2’s training-first design to faster prefill+decode performance in production. Mamba-3 upgrades the core SSM with a more expressive recurrence (via an exponential-trapezoidal discretization scheme), complex-valued state tracking, and an optional MIMO (multi-input, multi-output) variant that improves accuracy with minimal impact on decode latency. On Together’s reported latency tests for a ~1.5B model on a single H100-SXM 80GB, Mamba-3 (SISO) delivers the fastest prefill+decode times across sequence lengths, outperforming Mamba-2, Gated DeltaNet, and even a vLLM-served Llama-3.2–1B transformer baseline.
Five 5-minute reads/videos to keep you learning
1. Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents
This article walks you through the evolution of Claude Code’s skill system from simple markdown instructions to a full programmable agent platform with subagent execution, dynamic context injection, lifecycle hooks, and formal evaluation. It also covers a formal iterative evaluation loop for testing and improving skills over time, and points to an open Agent Skills standard designed to keep the format portable across AI tools.
2. Loss Landscapes: Part 1 (Part 2)
The loss landscape is a surface that maps model weights to loss values, ranging from smooth, convex bowls (simple models, with guaranteed global minima) to rugged, non-convex terrains riddled with local minima and saddle points. This article covers how gradient descent navigates loss landscapes and which tools help it succeed: weight decay to smooth chaotic landscapes, dropout for robustness, residual connections for deep-network stability, and batch/layer normalization to stabilize training dynamics.
3. Knowledge Distillation: How a Tiny Model Learned to Outsmart Its Giant Teacher
The article walks you through why large models carry dark knowledge in their probability distributions that hard labels destroy, and how temperature scaling amplifies those signals for smaller student models to absorb. It lays out the full derivation of the loss function, including the tau-squared compensation. The piece anchors the theory to DeepSeek-R1’s January 2025 result, in which a distilled student matched or beat its teacher, raising an unresolved question: Does compression reveal latent knowledge or generate entirely new capability?
4. Three Tasks, One Backbone: A Multi-Task Reranker That Tackles Search Challenges
In this article, the author trained a single cross-encoder on Amazon’s ESCI shopping dataset to handle three tasks simultaneously: graded relevance ranking, 4-class ESCI label classification, and binary substitute detection. Rather than training three separate models, the architecture routes a shared BERT backbone’s [CLS] embedding through three lightweight heads, each optimized with its own loss. The combined weighted loss prioritizes nDCG ranking while using classification and substitute detection as auxiliary regularizers.
5. NVIDIA State of AI Report 2026
NVIDIA’s comprehensive report examines how AI drives revenue across industries, covering enterprise adoption patterns, infrastructure scaling trends, and the shift toward agentic AI workflows. The report provides data-driven insights on computing demand, model deployment costs, and the economic impact of generative AI across manufacturing, healthcare, finance, and software development.
Repositories & Tools
1. LiteParse is a standalone OSS PDF parsing tool focused exclusively on fast and light parsing.
2. Deer Flow is an open-source super agent harness that orchestrates sub-agents, memory, and sandboxes to do almost anything.
3. PentAGI is a fully autonomous AI agent system capable of performing complex penetration testing tasks.
4. Colab MCP is Google’s MCP server for interacting with Colab.
Top Papers of The Week
1. Efficient Exploration at Scale
This paper introduces an online learning algorithm that improves the data efficiency of reinforcement learning from human feedback (RLHF). The algorithm incrementally updates reward and language models as choice data is received. The reward model is fit to the choice data, while the language model is updated by a variation of ‘reinforce’, with reinforcement signals provided by the reward model. With Gemma LLMs, this algorithm matches the performance of offline RLHF trained on 200K labels using fewer than 20K labels.
2. Memento-Skills: LLM Agents That Build Task-Specific Agents
This paper introduces Memento-Skills, a generalist, continually learnable LLM agent system that autonomously constructs, adapts, and improves task-specific agents through experience. The system is built on a memory-based reinforcement learning framework with stateful prompts, in which reusable skills (stored as structured markdown files) serve as a persistent, evolving memory. It achieves 26.2% and 116.2% relative accuracy improvements without updating LLM parameters.
3. Attention Residuals: Learned Layer Aggregation for LLMs
This paper proposes Attention Residuals (AttnRes), which replaces the fixed, uniform accumulation of residual connections in LLMs with softmax attention over preceding-layer outputs. This allows each layer to selectively aggregate earlier representations using learned, input-dependent weights. Tested on Kimi Linear (48B params, 3B activated, 1.4T tokens), AttnRes improves downstream performance and stabilizes output magnitudes and gradient distribution.
4. OpenSeeker: Fully Open-Source Search Agent Training Data
This paper introduces OpenSeeker, a fully open-source search agent (i.e., model and data) that achieves frontier-level performance through fact-grounded, scalable, controllable QA synthesis to generate complex, multi-hop reasoning tasks with controllable coverage and complexity, and denoised trajectory synthesis to employ a retrospective summarization mechanism. Trained on only 11.7K samples, it significantly outperforms the next-best open-source search agent and surpasses some commercial systems, such as Tongyi DeepResearch.
5. EvoClaw: Evaluating AI Agents on Continuous Software Evolution
This paper introduces EvoClaw, a novel benchmark, and the DeepCommit pipeline to evaluate AI agents on continuous, dependency-driven software evolution rather than isolated, one-off coding tasks. Evaluation of 12 frontier models across 4 agent frameworks reveals a critical vulnerability: overall performance scores drop significantly from >80% on isolated tasks to at most 38% in continuous settings.
Quick Links
1. Microsoft considers legal action over the $50 billion Amazon-OpenAI cloud deal that could violate its exclusive cloud agreement with the ChatGPT maker. The dispute centers on whether OpenAI can offer Frontier via AWS without violating the Microsoft partnership, which requires the startup’s models to be accessed through the Windows maker’s Azure cloud platform, the FT report said, citing sources.
2. NVIDIA released its Agent Toolkit, which provides open source models and software for enterprises and developers building autonomous, self-evolving AI agents. NVIDIA Agent Toolkit includes open models (NVIDIA Nemotron), open agents (NVIDIA AI-Q), open skills (NVIDIA cuOpt), and open runtimes (OpenShell). It also supports enterprise software platforms, such as Adobe, Atlassian, Box, Salesforce, etc.
Who’s Hiring in AI
LATAM Internship Program — Experience Design (UX/UI) @Salesforce (Sao Paulo, Brazil)
QA Engineering Lead, AI Native @Meta (Menlo Park, CA, USA)
Senior AI Engineer @Teradata (Hyderabad, India)
NLP Architect @Nutanix (San Jose, CA, USA)
Prompt Engineer @Highmark Health (Remote)
Machine Learning Product Summer Intern @Pacvue (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
The most interesting takeaway is that open-source projects often discover what users actually want, while companies turn those ideas into polished, enterprise-ready products. OpenClaw proved there was real demand for AI agents that can use computers, manage workflows, and automate complex tasks. Anthropic's focus on permissions, security, and enterprise controls shows that productization is much more than adding features https://fontgen.in/
This stress reaches its pinnacle as the level nears its conclusion since the player is increasingly afraid of failing.
https://geometrylite-2.io