
TAI #196: Quiet but Significant Agent Upgrades to Codex (Subagents) and Claude (Context)
Also, Gemini Embedding 2, NVIDIA Nemotron 3 Super, Yann LeCun's $1.03B AMI, Groundsource, Granite 4.01B Speech & more!



What happened this week in AI by Louie
OpenAI and Anthropic both shipped incremental upgrades this week that sound modest on paper but could reshape how serious developers actually work day to day. Elsewhere, Google released Gemini Embedding 2, its first natively multimodal embedding model; NVIDIA released Nemotron 3 Super; Google Research introduced Groundsource, turning global news into structured historical data and launching with a 2.6 million-record urban flash-flood dataset; Yann LeCun’s new startup AMI raised $1.03 billion at a $3.5 billion pre-money valuation to pursue world-model-heavy AI; and IBM shipped Granite 4.0 1B Speech for compact multilingual speech recognition, now ranked #1 on the OpenASR leaderboard.
For OpenAI, the key release was Codex subagents. Codex can now spawn specialized agents in parallel to explore, execute, or analyze work concurrently, while keeping the main thread focused on requirements, decisions, and final outputs. OpenAI’s docs frame this as a solution to “context pollution” and “context rot,” which is exactly right. One giant thread is fine until it turns into a digital junk drawer full of stack traces, half-failed tests, and exploratory dead ends.
OpenAI has essentially adopted the core product idea Anthropic pushed first with Claude Code and then more broadly with Cowork: separate the manager from the workers, keep the high-level thread clean, and let specialized agents chew through bounded tasks in parallel. This is a materially better operating model for real work, especially once tasks stop being cute demos and start involving actual codebases, logs, specs, and messy follow-ups. Once a workflow primitive proves itself in real work, the industry converges on it fast.
The Codex growth numbers indicate where OpenAI thinks the battle stands now. Fidji Simo said more than 1 million businesses run on OpenAI products, Codex is now at 2 million plus weekly active users (up nearly 4x since the start of the year), and API usage jumped 20% in the week after GPT-5.4 launched. OpenAI has also been expanding Frontier Alliances and pairing forward-deployed engineers with consulting firms to help enterprises actually deploy AI coworkers into real workflows.
Anthropic’s quiet but very meaningful move this week was making 1M context generally available for Opus 4.6 and Sonnet 4.6 at standard pricing: no long-context premium, full rate limits across the full window, and media limits expanded to 600 images or PDF pages. On MRCR v2 (8-needle) at 1M tokens, Opus 4.6 scores 78.3%, more than double GPT-5.4’s 36.6% and roughly triple Gemini 3.1 Pro’s 25.9%. Even Sonnet 4.6 hits 65.1% at the same context length. At 256K tokens, the field is tighter, with Opus 4.6 at 91.9%, Sonnet 4.6 at 90.6%, and GPT-5.4 at 79.3%, but as context scales up, the drop-off for competitors is steep. (Context Arena measured Gemini numbers on the same MRCR v2 benchmark, not Google’s self-report.)
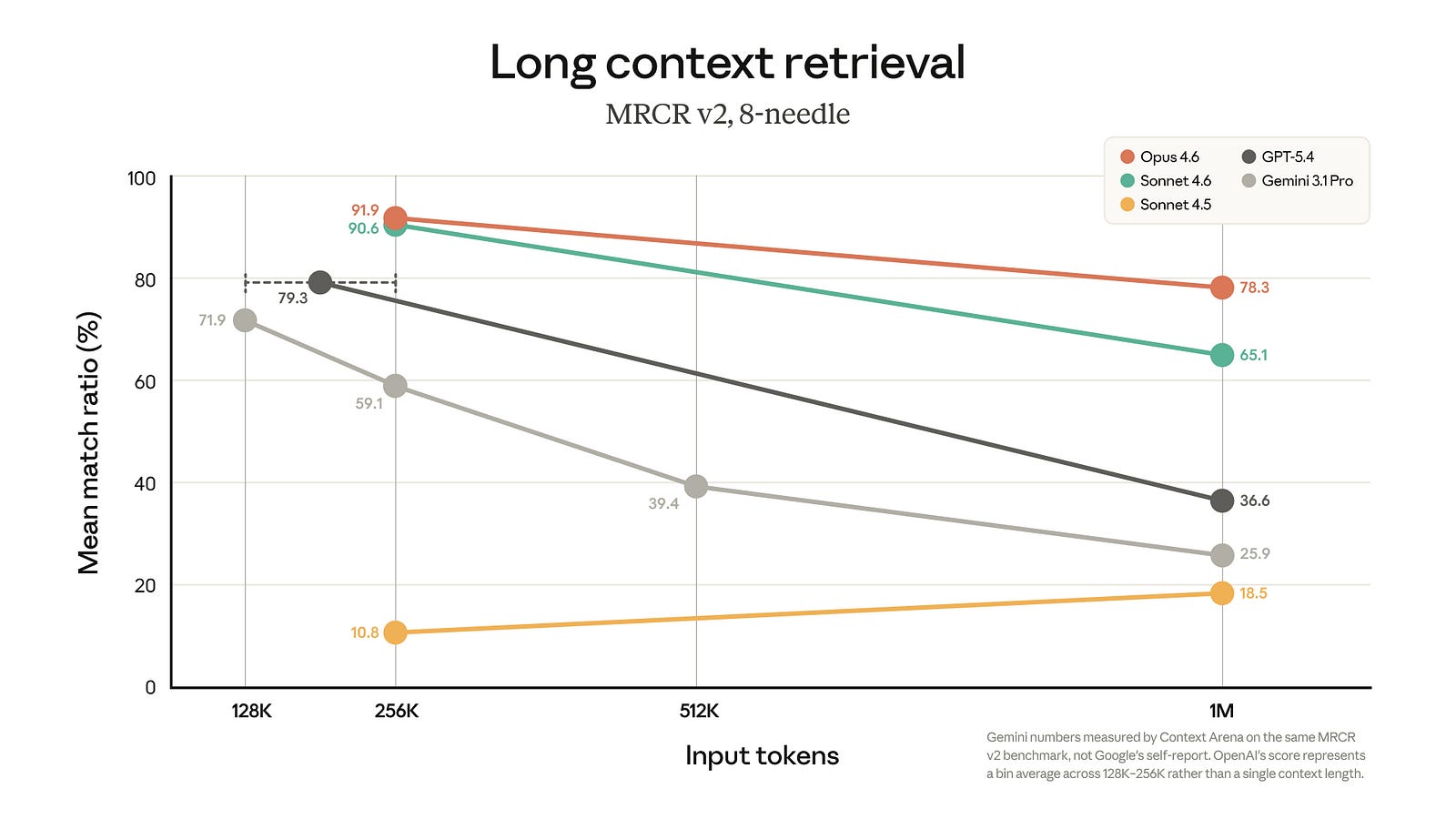
I did not have Anthropic pegged as the lab most likely to seize the long-context narrative in March, but here we are. For a while, long context felt like a Google Gemini story, and then, briefly, like an OpenAI comeback story. Anthropic may now have the strongest claim on the metric that actually matters for professional agentic work: not headline window size, but whether the model can still find the right thing after you bury it under a mountain of tokens.
That matters enormously for agentic coding and review. The hard sessions are not short snippets. They are the ugly, hours-long runs where the model has read a large diff, test output, monitoring logs, maybe a product doc, maybe a PDF, and still needs to remember why line 37 in a config file matters. A million tokens that actually hold up (and with no price premium for higher context usage) is a real unlock.
Anthropic also launched Code Review for Claude Code, a research preview system that deploys a team of agents to each pull request. The average review takes around 20 minutes and generally costs $15 to $25. On pull requests over 1,000 lines changed, 84% get findings averaging 7.5 issues, and less than 1% of findings are marked incorrect. Internally, Anthropic says the share of pull requests receiving substantive review comments rose from 16% to 54% after adopting the system.
That is impressive on its own, but it also reveals something about where the real constraint is shifting. We are getting to the point where a strong developer with good agents can generate code much faster than the surrounding review process can absorb it. You only get to bank AI productivity if the code is trustworthy enough to merge. Otherwise, you just manufacture more uncertainty at a higher speed.
And for now, humans still need to understand the code. Despite recent leaps, AI remains a jagged intelligence, tireless and elegant at parallel exploration, then suddenly blind to the one buried business rule that everyone on the team “just knows.” The best results still come from expert developers who nudge early, critique the plan, steer the agents mid-run, and know when the model has wandered off course.
There is a plausible future where this flips. Self-driving cars offer a template: at first, the human is the safety layer, maintaining full responsibility in driver-assist systems, but eventually, AI reliability improves, and the human starts to look like the unpredictable failure mode. Coding could follow a similar arc. If AI-written code eventually has fewer bugs than human-written code, and humans mostly add net bugs by tweaking systems they no longer fully understand, then full autonomy on some classes of software work will start to look rational. We are not there yet. Right now, the highest-return setup is expert human plus agent swarm.
Why should you care?
Once a workflow pattern becomes obviously useful, the industry converges on it fast. Claude Code and Cowork proved that splitting work into parallel threads beats forcing one bloated session to play every role at once. OpenAI now agrees. Long context, too: the labs all want it, but Anthropic’s 78.3% on MRCR v2 at 1M tokens versus GPT-5.4’s 36.6% is now a real gap for pushing agents to their limits. The fact that the expanded context is available without a price premium also suggests a more fundamental architectural or inference breakthrough. Due in part to there being no non-compete clauses in California (and high staff turnover between the labs), and the fact that many researchers across AI labs are good friends and attend the same parties, we can continue to expect these breakthroughs to quickly disperse across the leading model families (so long as the AI lab has enough compute to keep up!)
Meanwhile, Codex, with 2M+ weekly active users (nearly 4x since January), alongside a growing army of forward-deployed engineers, tells the full story of where we are. The models are strong enough to be useful everywhere, but alien enough that bridging the gap between raw capability and reliable daily workflow is now the main job. The developers who learn that bridging skill fastest will pull away from everyone still using AI as fancy autocomplete.
— Louie Peters — Towards AI Co-founder and CEO
This issue is brought to you thanks to SerpApi:

LLMs are powerful. But without fresh information, they can hallucinate or miss context.
SerpApi helps AI applications access real-time search data from search engines like Google, Bing, Amazon, and more via a simple API.
Get clean, structured JSON results and power AI agents, research tools, and data-driven applications without managing scrapers.
Start with 250 free credits/month by signing up at SerpApi today!
A Quick Look at AI Adoption at Empower
Much of the conversation around AI in the workplace focuses on frontier models and benchmark scores, but the more revealing signal is what’s happening inside real businesses right now. At Empower Technical Services, a leading UK technical services provider co-founded by our own Denis Piffaretti, teams across the C-suite, HR, and M&A are using AI today to stress-test executive analysis, surface gaps in employment contracts, and compress weeks of acquisition research into hours. What stands out isn’t any single use case, it’s the shared mindset: AI as a quality amplifier, not a corner-cutter. If you’re thinking about how to move your own organisation from AI curiosity to genuine day-to-day integration, this piece is worth a read.
Hottest News
1. Google Releases Gemini Embedding 2
Google launched Gemini Embedding 2, its first natively multimodal embedding model. Gemini Embedding 2 maps text, images, videos, audio, and PDFs into a single shared embedding space, so multimodal retrieval and classification no longer require separate embedding models for each modality. It supports up to 8,192 input tokens, up to 6 images per request, up to 120 seconds of video, and PDFs up to 6 pages, and it can take interleaved inputs (for example, image + text in the same request). Output vectors are produced by default with 3,072 dimensions, with recommended lower options of 1,536 or 768, using Matryoshka Representation Learning to trade off storage and quality. Google is offering it in public preview via the Gemini API and Vertex AI, and highlights support through common ecosystem tooling, including LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, and ChromaDB.
2. NVIDIA Releases Nemotron 3 Super
NVIDIA open-sourced Nemotron 3 Super, a 120B (12B active) long-context model built to reduce the “thinking tax” for agents. Nemotron 3 Super is a 120B total/12B active hybrid Mamba-Transformer MoE model with native 1M-token context, designed to keep multi-step agent workflows coherent without context blowups. NVIDIA positions the release around compute efficiency for complex multi-agent workloads (such as software development and cybersecurity triage) and reports 5×+ throughput over the prior Nemotron Super. The architecture combines a LatentMoE hybrid stack (Mamba-2 + MoE + attention) with multi-token prediction (MTP), and the model supports a configurable reasoning mode (toggleable via the chat template). The release is fully open, with datasets, recipes, and model weights published on Hugging Face and an official model card on NVIDIA’s platform.
3. Yann LeCun Raises $1 Billion to Build AI That Understands the Physical World
Yann LeCun’s new startup, Advanced Machine Intelligence (AMI), raised $1.03B to build “world model” AI. Reuters reports AMI raised $1.03 billion at a $3.5 billion pre-money valuation, and that the company is aiming for systems that can reason, plan, and understand the world, rather than relying solely on next-token (or next-pixel) prediction. LeCun has argued that this shift is required for broadly capable autonomous agents, and AMI’s near-term focus is on organizations operating complex systems, such as automotive, aerospace, biomedical, and pharmaceutical firms, with consumer applications (including robotics) positioned as later-stage.
4. Anthropic Releases Claude Code Review
Anthropic is introducing Claude Code Review, a multi-agent PR review system now in research preview for Team and Enterprise. Claude Code Review dispatches multiple agents when a pull request opens, has them search for bugs in parallel, cross-verify findings to reduce false positives, and then rank issues by severity. Anthropic reports internal results showing that on large PRs (1,000+ lines changed), 84% receive findings with an average of 7.5 issues, while smaller PRs (<50 lines) see findings 31% of the time with an average of 0.5 issues; fewer than 1% of surfaced findings are marked incorrect by engineers. Pricing is token-based, with typical reviews ranging from $15–$25, depending on PR size and complexity.
5. Google AI Introduces Groundsource
Google Research released Groundsource and a 2.6M-record global dataset of urban flash flood events extracted from news. Groundsource is a methodology that uses Gemini to convert unstructured global news into structured, verified historical disaster data. It analyzes news reports where flooding is a primary subject and then uses the Google Read Aloud user agent to isolate the primary text from 80 languages, which is then standardized into English via the Cloud Translation API. The first release is an open-access dataset of 2.6 million historical urban flash flood events spanning 150+ countries, built by identifying flood-related news reports and extracting event details and locations at scale.
6. IBM AI Releases Granite 4.0 1B Speech
IBM has released Granite 4.0 1B Speech, a compact speech-language model designed for multilingual automatic speech recognition (ASR) and bidirectional automatic speech translation (AST). With only half the parameters of its predecessor, granite-speech-3.3–2b, the model delivers higher English transcription accuracy, faster inference through speculative decoding, and expanded language support, now covering English, French, German, Spanish, Portuguese, and Japanese. The release adds Japanese ASR and keyword list biasing for more targeted transcription workflows. It supports deployment through Transformers, vLLM, and mlx-audio, including Apple Silicon environments. Granite 4.0 1B Speech ranked #1 on the OpenASR leaderboard.
Five 5-minute reads/videos to keep you learning
1. The KV Cache: The Invisible Engine Behind Every LLM Response
Without the KV Cache, LLMs would recompute attention for every previously seen token at each generation step, an O(T²) inefficiency that makes real-time responses impractical. This piece breaks down exactly how the cache works: storing Key and Value vectors per layer while discarding Query vectors, which are mathematically proven to be single-use. It walks through prefill vs. decode phases, the memory cost formula, and why that cost compounds across sequence length, batch size, and model scale. It also covers how production systems respond to GQA, quantization, PagedAttention, and sliding-window attention, each targeting a specific variable within the same core equation.
2. Context Pollution: Do LLMs Benefit From Their Own Words?
New research from MIT and IBM Research challenges a core assumption behind every major chatbot: that keeping full conversation history always improves model performance. The study introduced Assistant-Omitted prompting, stripping prior AI responses from each new message, and found that quality rarely dropped and sometimes improved. Over a third of real-world user messages were standalone questions requiring no prior context. More concerning, early model errors were found to quietly persist across conversation turns, a phenomenon the researchers termed context pollution. A lightweight classifier was proposed to adaptively manage context, cutting token usage by roughly 30% with minimal quality trade-off.
3. The New Nano Banana 2 + OCR + Claude Code = Powerful AI OCR PDF Editor
This guide walks you through a hands-on demo of Google’s newly released Imagen 3 and provides a practical guide to building an AI-powered PDF editor. Imagen 3 is combined with Claude for prompt refinement and Tesseract OCR for text layer reconstruction, forming an agentic pipeline that edits or inserts slides based on user instructions. The system processes multiple pages in parallel, preserves original layouts, and outputs fully searchable PDFs. Beyond the technical build, the author weighs Imagen 3 against Imagen Pro, noting meaningful gains in text accuracy, 4K support, web-referenced generation, and a significantly lower cost per image.
4. Information Topology in Multi-Agent Systems: as a Behavioral Parameter
Information flow between AI agents is often treated as an afterthought; this article argues it shouldn’t be. The author built a multi-agent orchestration platform using Python and the Strands SDK to run a controlled Prisoner’s Dilemma experiment, isolating information topology as the sole variable. Across three phases (blind, partial, and full transparency), the same agents, given identical instructions, exhibited measurably different behaviors. Partial information pushed a cooperative agent toward identity-driven decisions, while full transparency made it more calculated. The exploitative agent, however, remained unaffected throughout. The key takeaway here is that what an agent knows is as architecturally significant as what it’s told to do.
ReLU activation functions have long been the default choice in deep learning, but they carry a critical flaw, the dying neuron problem. When neurons receive consistently negative inputs during training, their gradients become zero, permanently halting learning and creating what the author calls a zombie network. Through a controlled PyTorch experiment on Fashion-MNIST, the article visually demonstrates this failure mode, showing 99.2% neuron death under standard ReLU, compared with healthy activation distributions with Leaky ReLU. It also evaluates practical alternatives such as Leaky ReLU, PReLU, ELU, Swish, and GELU.
Repositories & Tools
1. Superpowers is a software development workflow for coding agents, built on top of a set of composable “skills.”
2. Lightpanda is a headless browser for AI agents and automation.
3. Gstack is an open-source toolkit that packages Claude Code into 8 opinionated workflow skills backed by a persistent browser runtime.
4. OpenViking is an open-source context database designed specifically for AI Agents(such as OpenClaw).
5. OpenJarvis is an opinionated framework for local-first personal AI, built around shared primitives and a learning loop that improves models using local trace data.
6. Cognee is an open-source knowledge engine that lets you ingest data in any format and continuously learns to provide the right context for AI agents.
Top Papers of The Week
1. Neural Thickets: Task Experts Are Dense Around Pretrained Weights
This paper views the outcome of pretraining as a distribution over parameter vectors, whose support already contains task-specific experts. It shows that in small models, such expert solutions occupy a negligible fraction of the volume of this distribution, making their discovery reliant on structured optimization methods such as gradient descent. In contrast, in large, well-pretrained models, the density of task-experts increases dramatically, so that diverse, task-improving specialists populate a substantial fraction of the neighborhood around the pretrained weights. Building on this, the authors propose a trivially simple parallel post-training method: randomly sample N parameter perturbations, select the top K, and ensemble via majority voting. This approach matches the performance of PPO, GRPO, and ES on contemporary large-scale models without any gradient-based optimization.
2. Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
This paper investigates the effectiveness of using reasoning large language models as judges for reinforcement learning-based alignment in domains where output correctness cannot be directly verified. The authors discover that while reasoning judges outperform non-reasoning ones in preventing standard reward hacking, they inadvertently train policies to achieve high scores by generating sophisticated adversarial outputs that deceive evaluators.
This paper proposes Attention Residuals (AttnRes) as a drop-in replacement for standard residual accumulation. Instead of forcing every layer to consume the same uniformly mixed residual stream, AttnRes lets each layer aggregate earlier representations using softmax attention over depth. The core idea is simple: if attention improves sequence modeling by replacing fixed recurrence over time, a similar idea can be applied to a network’s depth dimension.
4. HY-WU: An Extensible Functional Neural Memory Framework
HY-WU (Weight Unleashing) proposes a fundamentally different approach to model adaptation: instead of overwriting shared weights at each update, a neural generator module stores functional memory and synthesizes instance-specific weight updates dynamically based on runtime conditions. The framework targets the core limitation of static inference: “a single parameter vector regardless of user intent,” enabling personalization and continual learning without catastrophic interference between objectives. Demonstrated on text-guided image editing in Part I of a multi-part series.
Quick Links
1. LangChain releases Deep Agents, an agent harness built on LangChain and the LangGraph runtime. It includes a built-in ‘write_todos’ tool for planning and task decomposition. It uses filesystem tools to manage large contexts and supports persistent memory across threads.
2. Zhipu AI introduces GLM-OCR, a compact 0.9B multimodal OCR model built with a 0.4B CogViT encoder and 0.5B GLM decoder. It uses Multi-Token Prediction (MTP) to improve decoding efficiency, achieving an average of 5.2 tokens per step and about 50% higher throughput. It scores 94.6 on OmniDocBench v1.5, 94.0 on OCRBench (Text), 96.5 on UniMERNet, 85.2 on PubTabNet, and 86.0 on TEDS_TEST.
Who’s Hiring in AI
Senior Research Engineer, Cloud AI Research @Google (Sunnyvale, CA, USA)
Applied AI Engineer II @Microsoft Corporation (Bangalore, India)
Master Principal Cloud Engineer — GPU & AI Infrastructure @Oracle (Shanghai, China)
Engineering Manager — Payments Platform @Coinbase (Multiple US Locations)
Senior AI Engineer @UPS (India)
Engineering Manager @Huckleberry Labs (Remote)
AI Engineer @Panopto (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.