
TAI #192: AI Enters the Scientific Discovery Loop
Also, Gemini 3 Deep Think, First Proof challenge, OpenClaw goes to a foundation, Z.ai GLM-5, MiniMax M2.5 & more.



What happened this week in AI by Louie
This week, LLMs crossed from tools into participants in scientific discovery. OpenAI released a preprint, “Single-minus gluon tree amplitudes are nonzero,” in which GPT-5.2 Pro helped conjecture a new formula in particle physics. Standard textbook reasoning has typically implied that a particular gluon-scattering configuration (one negative-helicity gluon and the rest positive-helicity) should have zero amplitude at tree level. GPT-5.2 Pro identified a specific exception: in a precisely defined momentum-space region called the half-collinear regime, the usual argument no longer applies, and the amplitude becomes nonzero. Physicists from the Institute for Advanced Study, Harvard, Cambridge, and Vanderbilt computed base cases up to n = 6 by hand, producing superexponentially complex expressions. GPT-5.2 Pro simplified them, spotted a pattern, and proposed a closed-form formula for all n. A scaffolded internal model then spent 12 hours producing a formal proof, which humans verified against the Berends–Giele recursion relation, and the team reports the result has already been extended to gravitons.
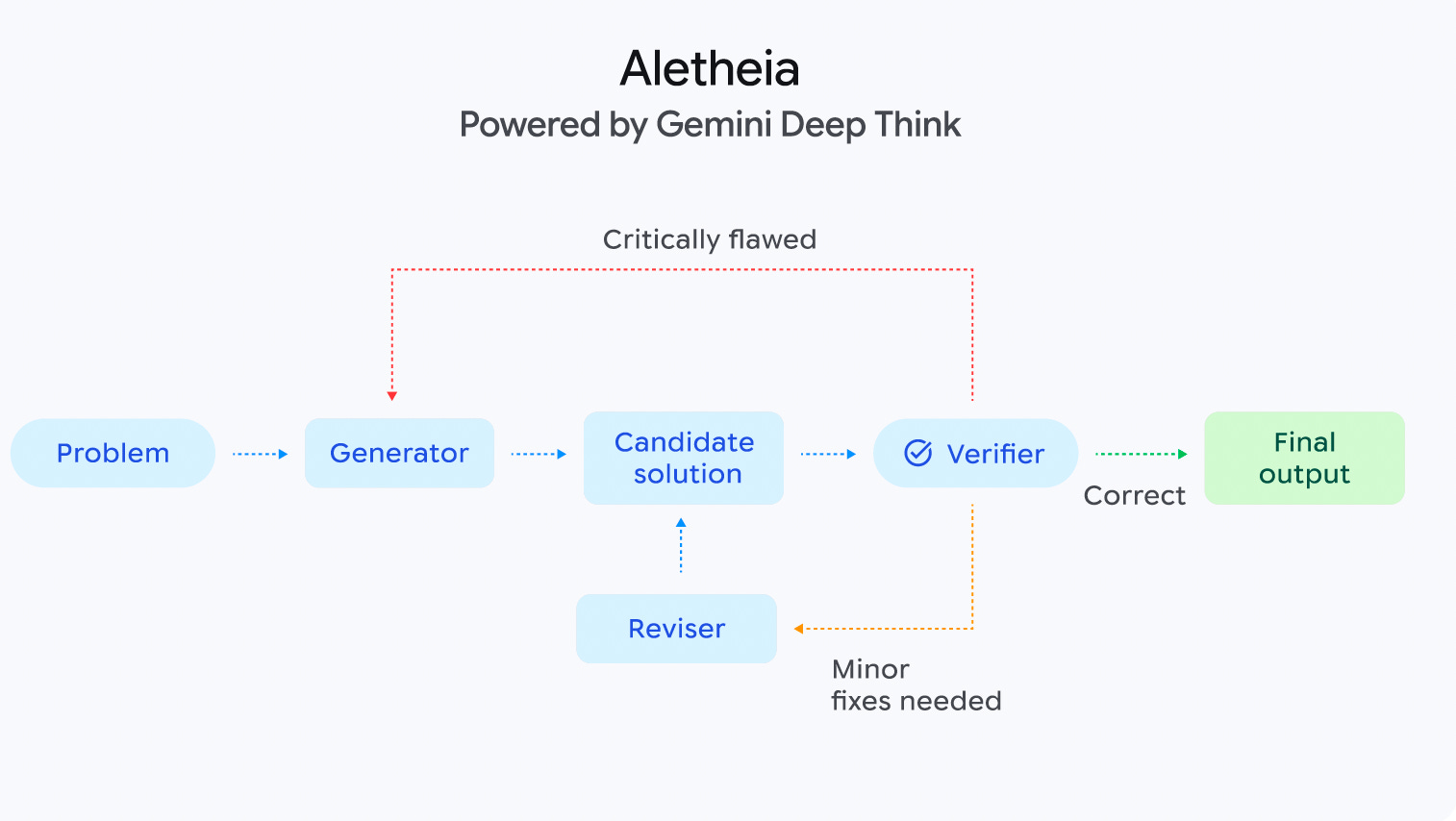
Google also shipped a major upgrade to Gemini 3 Deep Think, aimed at research and engineering workloads. Reported results include 84.6% on ARC-AGI-2 (ARC Prize Foundation verified; humans average ~60%), 48.4% on Humanity’s Last Exam without tools, and 3455 Elo on Codeforces (Legendary Grandmaster). DeepMind introduced Aletheia, a math research agent built around a generator–verifier–reviser loop, and reported 91.9% on IMO-ProofBench Advanced (prior best: 65.7%). Aletheia autonomously produced a publishable paper on eigenweights in arithmetic geometry with no human intervention. Separately, mathematician Lisa Carbone at Rutgers used Deep Think to identify a subtle logical flaw in a peer-reviewed paper that human reviewers had missed.
At the same time, the First Proof challenge served as a counterbalance. On February 5, eleven mathematicians released ten unpublished research-level problems. OpenAI’s Jakub Pachocki wrote that an internal model, supported by “expert feedback” from mathematicians, had solutions with “a high chance of being correct” for six of ten. Experts quickly identified gaps. The First Proof team’s verdict on February 14 was that only 2 of 10 AI-generated solutions were correct across all submissions (Problems 9 and 10). The broader pattern was consistent: many proofs were confident and well-structured, but incorrect. The heavy human guidance used in OpenAI’s sprint also makes it difficult to isolate model capability from human steering.
On the model release side, Chinese labs delivered two notable open-weight launches. Z.ai released GLM-5, a 744B Mixture-of-Experts model with 40B active parameters, trained entirely on Huawei Ascend chips (no NVIDIA dependency). It supports 200K context via DeepSeek Sparse Attention, reports 77.8% on SWE-Bench Verified (#1 among open-weight models), and ships under an MIT license. MiniMax launched M2.5, a 230B MoE model with 10B active parameters, reporting 80.2% on SWE-Bench Verified (matching Claude Opus 4.6 and exceeding GPT-5.2) at roughly 1/20th the cost. MiniMax attributes training to Forge, an agent-native RL framework built on 200,000+ real-world environments, and says M2.5 now handles 30% of internal company tasks, with 80% of new code generated by the model.
On the agent front, OpenAI hired Peter Steinberger, creator of OpenClaw (145,000+ GitHub stars in three months), and is pushing the project into an independent open-source foundation. Steinberger chose OpenAI over a competing offer from Meta. Google shipped an early preview of WebMCP, a proposed W3C standard co-developed with Microsoft that lets websites publish structured tool contracts so agents can interact through JSON schemas rather than screenshots, reducing computational overhead by 67%. Together, OpenClaw aims to standardize the agent side, while WebMCP targets standardization on the website side.
Why should you care?
Three results from this week point to the same underlying shift. GPT-5.2 Pro conjectured a physics formula that humans then verified. Aletheia produced a publishable math paper by running an end-to-end solve–verify–revise loop. Deep Think flagged a logical flaw in a peer-reviewed paper that human reviewers missed. In each case, the value came from more than generation: it came from coupling generation with disciplined checking that can confirm, refine, or reject the output.
First Proof is the clearest signal we have for where that coupling still breaks down. The challenge created something close to a controlled test: ten novel problems, limited contamination risk, and transparent grading. Models generated convincing proofs for every problem, but only two survived expert scrutiny. That is a real signal — these are research-level lemmas that would take a human mathematician days to prove, and the models achieved meaningful traction on them in a week. The gap is in reliability, not capability. Aletheia closes that gap by making verification structural rather than optional, running an internal critic that flags flaws before a human ever sees the output.
I think verification infrastructure is going to be the moat for AI-assisted research. The model that generates the best conjectures is useful. The system that generates conjectures and reliably tells you which ones are correct is transformative. DeepMind is building that system for math. The open question is who builds it for biology, chemistry, and materials science, where verification means running experiments rather than checking proofs.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI Releases a Research Preview of GPT-5.3-Codex-Spark
OpenAI is shipping GPT-5.3-Codex-Spark, a smaller counterpart to GPT-5.3-Codex and the first model explicitly built for real-time coding. It’s designed for interactive development where latency is a first-class constraint, pairing a 128K context window with a text-only interface. The speed-up comes from running on the Cerebras Wafer-Scale Engine 3 (WSE-3). The trade-off is clear in the benchmark results: Spark scores lower than the flagship model on SWE-Bench Pro and Terminal-Bench 2.0.
2. Google Released a Major Upgrade to Gemini 3 Deep Think
Google announced a major update to Gemini 3 Deep Think, specifically built to accelerate modern science, research, and engineering. Reported scores include 84.6% on ARC-AGI-2, 48.4% on Humanity’s Last Exam, 50.5% on CMT-Benchmark, and a 3455 Elo result on Codeforces. Google also reports gold-medal–level performance in the written portions of the 2025 International Physics and Chemistry Olympiads. The updated Deep Think is available in the Gemini app for Google AI Ultra subscribers, and through the Gemini API for select researchers, engineers, and enterprises.
Z.ai launched GLM-5, a 744B-parameter Mixture-of-Experts model with 40B active parameters, built for complex systems engineering and longer-running agent workflows. It integrates DeepSeek Sparse Attention (DSA) to lower deployment cost while retaining long-context capacity. Pretraining expands from 23T to 28.5T tokens, and post-training uses slime, an asynchronous RL infrastructure intended to improve training throughput and efficiency. On Vending Bench 2, a benchmark for long-term operational capability, GLM-5 ranks #1 among open-source models.
4. Moonshot AI Launches Kimi Claw
Moonshot AI brought the OpenClaw framework directly into the browser with Kimi Claw, now native to kimi.com as a persistent, always-on workspace that doesn’t require local hardware setup. It includes ClawHub, a library of 5,000+ community skills for composing and chaining functions into larger agent workflows. The platform also provides 40GB of cloud storage, supporting larger datasets and deep context for RAG-style systems. A Bring Your Own Claw option lets teams connect third-party OpenClaw deployments or bridge agents into external surfaces such as Telegram group chats.
MiniMax launched MiniMax-M2.5, a foundation model for coding, search, tool use, and office workflows, with an emphasis on reducing runtime costs for production agents. MiniMax reports 80.2% on SWE-Bench Verified, 51.3% on Multi-SWE-Bench, and 76.3% on BrowseComp with context management. Training covers 10+ languages and more than 200,000 real-world environments. The release introduces Forge, an agent-native RL framework, alongside a process reward mechanism designed to monitor and steer generation quality end-to-end, while continuing the CISPO approach for stabilizing large-scale MoE training. The release introduces two variants: M2.5 and M2.5-Lightning, with the same capabilities but different speed profiles.
6. Google AI Introduces the WebMCP (Early Preview)
Google began an early preview of WebMCP, a standard for exposing structured tools so browser agents can take actions more reliably than screenshot-driven “vision clicking.” WebMCP proposes two APIs: a Declarative API for standard actions defined in HTML forms, and an Imperative API for more complex interactions that require JavaScript execution. By using structured JSON schemas, WebMCP reports a 67% reduction in computational overhead and a task accuracy of approximately 98%. Access is currently limited to an early preview sign-up.
Five 5-minute reads/videos to keep you learning
1. Multimodal Large Language Models: Architectures, Training, and Real-World Applications
This article provides a technical overview of Multimodal Large Language Models (MLLMs) and distinguishes between modular architectures and monolithic designs. It explains how alignment and fusion layers bridge the gap between specialized encoders and LLM backbones and further details a three-stage training pipeline: modality alignment, joint pretraining, and instruction tuning. Finally, it examines practical applications in document understanding, visual question answering, and autonomous GUI agents.
2. Stop Building Over-Engineered AI Agents: How I Built a BigQuery Analyst with Just a Markdown File
This article examines the transition from over-engineered AI agents to a streamlined, decoupled architecture. By moving away from complex Python-heavy frameworks like LangChain, the author demonstrates how to build a reliable BigQuery analyst using a simple Markdown file for business logic and the Model Context Protocol (MCP) for data connectivity. It outlines a shift from hard-coding agents to teaching Skills (portable packages of procedural knowledge). It also details the implementation of a marketing data analyst, where the AI uses a Markdown-based brain to handle messy data, map business metrics, and generate precise SQL.
3. I Gave an AI Agent Shell Access. It Took 12 Seconds to Exploit
Analyzing the security risks of AI agents, the author demonstrates that an MCP server was compromised in just 12 seconds via a supply-chain attack. The piece reveals that even with command whitelists in place, malicious npm packages can exfiltrate sensitive credentials and environment variables. To mitigate these risks, the article provides a technical guide on containerizing servers with Docker to isolate the host system from compromised dependencies and also shares a comprehensive security checklist for production environments.
4. RAG — Retrieval Full Matrix Evaluation
The article presents a professional evaluation matrix designed to optimize retrieval model selection. It breaks down the system into two critical phases: offline indexing and real-time search, prioritizing latency and query throughput for the end-user experience. It also provides a technical framework for measuring semantic quality through Recall@K and assessing hardware efficiency based on model size and vector dimensionality.
5. Physics-Informed Neural Networks for Inverse PDE Problems
The blog explores Physics-Informed Neural Networks (PINNs), a specialized class of deep learning models that treat physical laws (like the Heat Equation) as a cheat sheet to improve predictions. Unlike traditional neural networks that rely solely on data, PINNs use automatic differentiation to ensure their outputs satisfy specific Partial Differential Equations (PDEs). The author demonstrates this by solving an inverse PDE problem: using temperature data from a simulated 1-meter rod to back-calculate the material’s thermal diffusivity (kappa) and the heat source (q). Using the DeepXDE library with a TensorFlow backend, the PINN successfully approximates these constants by minimizing a physics-based loss function.
Repositories & Tools
1. Moonshine is an AI toolkit for developers building real-time voice applications.
2. Protenix is built for high-accuracy biomolecular structure prediction.
3. RowBoat is an AI coworker that can turn work into a knowledge graph and act on it.
4. Zvec is an in-process vector database that targets edge and on-device retrieval workloads.
5. AIOS Core is an AI-orchestrated system for full-stack development.
Top Papers of The Week
1. Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
The paper introduces Composition-RL, a method that composes multiple verifiable problems into new prompts to better exploit pass-rate-1 data in Reinforcement Learning with Verifiable Rewards. Composition-RL boosts reasoning performance for 4B–30B models, improves cross-domain RL by mixing domains, and gains further accuracy with a curriculum that gradually increases compositional depth.
2. Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
This paper introduces Step 3.5 Flash, a sparse Mixture-of-Experts model that couples a 196B-parameter foundation with 11B active parameters to deliver frontier-level agentic intelligence efficiently. The model uses interleaved 3:1 sliding-window/full-attention and MTP-3 to reduce multi-round interaction cost, and a scalable RL framework with verifiable and preference signals to achieve GPT‑5.2 xHigh–comparable performance on math, coding, and tool-use benchmarks.
3. Simultaneous Speech-to-Speech Translation Without Aligned Data
This paper proposes Hibiki-Zero, which eliminates the need for word-level alignments entirely. It simplifies the training pipeline and enables seamless scaling to diverse languages with varying grammatical structures, removing the bottleneck of designing language-specific alignment heuristics. Hibiki-Zero achieves state-of-the-art performance in translation accuracy, latency, voice transfer, and naturalness across five X-to-English tasks.
This paper introduces OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework for LLM pre-training that prioritizes better tokens over more tokens. The method scores examples by projecting optimizer-shaped updates onto a target direction using an in-distribution proxy, with Ghost, CountSketch, and Boltzmann sampling. OPUS boosts GPT-2 and Qwen3 training efficiency, outperforming larger-token baselines with minimal compute overhead.
5. Less is Enough: Synthesizing Diverse Data in the Feature Space of LLMs
The authors introduce Feature Activation Coverage, a feature-space metric that directly measures post-training data diversity in large language models, surpassing text-based metrics. They then present FAC Synthesis, which uses a sparse autoencoder to detect missing features in seed data and generate synthetic samples, improving data diversity, downstream performance, and cross-model knowledge transfer across LLaMA, Mistral, and Qwen.
Quick Links
1. Cursor introduces Composer 1.5, an upgraded agentic coding model that scales reinforcement learning 20x beyond Composer 1 and even exceeds the base model’s pretraining compute. Composer 1.5 uses thinking tokens to reason about codebases, adapts thinking depth to task difficulty, and employs self-summarization to handle long contexts, delivering predictable, stronger coding performance for interactive, real-world use.
2. Google DeepMind introduces Aletheia, a specialized AI agent designed to bridge the gap between competition-level math and professional research. It is powered by an advanced version of Gemini Deep Think and an agentic loop consisting of a Generator, Verifier, and Reviser.
3. Exa AI introduces Exa Instant, a search model designed to provide the world’s web data to AI agents in under 200ms. Unlike many search APIs that simply ‘wrap’ Google or Bing (adding 700ms+ of overhead), Exa Instant is built on a proprietary, end-to-end neural search engine. It uses a custom transformer-based architecture to index and retrieve web data, offering up to 15x faster performance than existing alternatives.
Who’s Hiring in AI
Senior Outbound Product Manager, Generative AI, Cloud AI @Google (London/Zürich/Warsaw)
Product Manager, Generative AI Data @NVIDIA (Remote/USA)
Principal AI Scientist @Microsoft Corporation (Amsterdam, Netherlands)
AI Engineer @Leidos (Remote/USA)
Senior Software Engineer (AI Platform — AI Acceleration) @Coinbase (Multiple US Locations)
LLM Engineer (Onshore — US) @Insight Global (Boston, MA, USA)
Gen AI Engineer @Cognizant (Bangalore, India)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
This article beautifully captures the transformative potential of AI in scientific research! I'm excited to see how these advancements will accelerate discoveries. Thank you for such insightful analysis! https://run3-online.io
Fascinating to see AI entering scientific discovery, this changes the pace of research entirely.