
TAI #187: OpenAI's Health Push and the Real State of LLMs in Medicine
Also, Nvidia Alpamayo models, Rubin, Falcon H1R-7B & more.




What happened this week in AI by Louie
OpenAI made its biggest healthcare push this week with two launches: ChatGPT Health for consumers and OpenAI for Healthcare for enterprises. The consumer product lets users connect medical records and wellness apps so responses can be grounded in personal context. The enterprise product offers BAA support, institutional policy integrations, and clinical templates for hospitals and health systems. Anthropic followed days later with Claude for Healthcare, featuring similar HIPAA-ready positioning plus connectors for CMS databases, ICD-10 codes, and PubMed.
The timing makes sense. OpenAI claims over 230 million people already ask health questions on ChatGPT weekly. Rather than fighting this behavior, they are productizing it. But I think the framing of these launches obscures where LLMs actually add value in health today versus where they need careful deployment.
The clearest wins are administrative and language-heavy tasks: drafting discharge summaries, patient instructions, prior authorization narratives, insurance comparisons, and translating medical jargon into plain language. These are high-volume workflows where humans review outputs before anything touches a patient. The ambient documentation market has exploded over the past quarter, with Microsoft, the VA, Veradigm, RXNT, and Google Cloud all shipping or expanding Scribe products. Documentation is the obvious wedge because it is language-heavy and naturally human-in-the-loop.
Diagnosis is a more complex application, but it is more nuanced than the binary “safe or dangerous” framing suggests. I think LLMs can provide enormous value when used as brainstorming partners for human experts. The sweet spot is generating suggestions in volume that are quick for clinicians to review and filter using their own intuition. An LLM suggesting rare diseases or edge cases that a busy doctor might not immediately consider can be incredibly valuable. The expert can instantly recognize which suggestions are smart, which are apparent, and which are nonsense. This is very different from an LLM making autonomous diagnostic decisions or patients self-diagnosing without professional review. The risk is not in the brainstorming; it is in skipping the expert filter. ChatGPT has steered clear of diagnosis with the Health tool positioning, likely because it is too easy for people to skip this expert filter.
The privacy critique also has teeth. When individuals upload their own records to a consumer tool, HIPAA protections generally do not apply as they do within a covered entity. OpenAI’s compartmentalization and “no training on health chats” commitment are meaningful, but the U.S. lacks a comprehensive privacy law that would permanently lock in these protections. A 2024 analysis found 37% of ChatGPT health answers untrustworthy, with 4% providing dangerous information. Context from connected records helps, but it does not certify correctness.
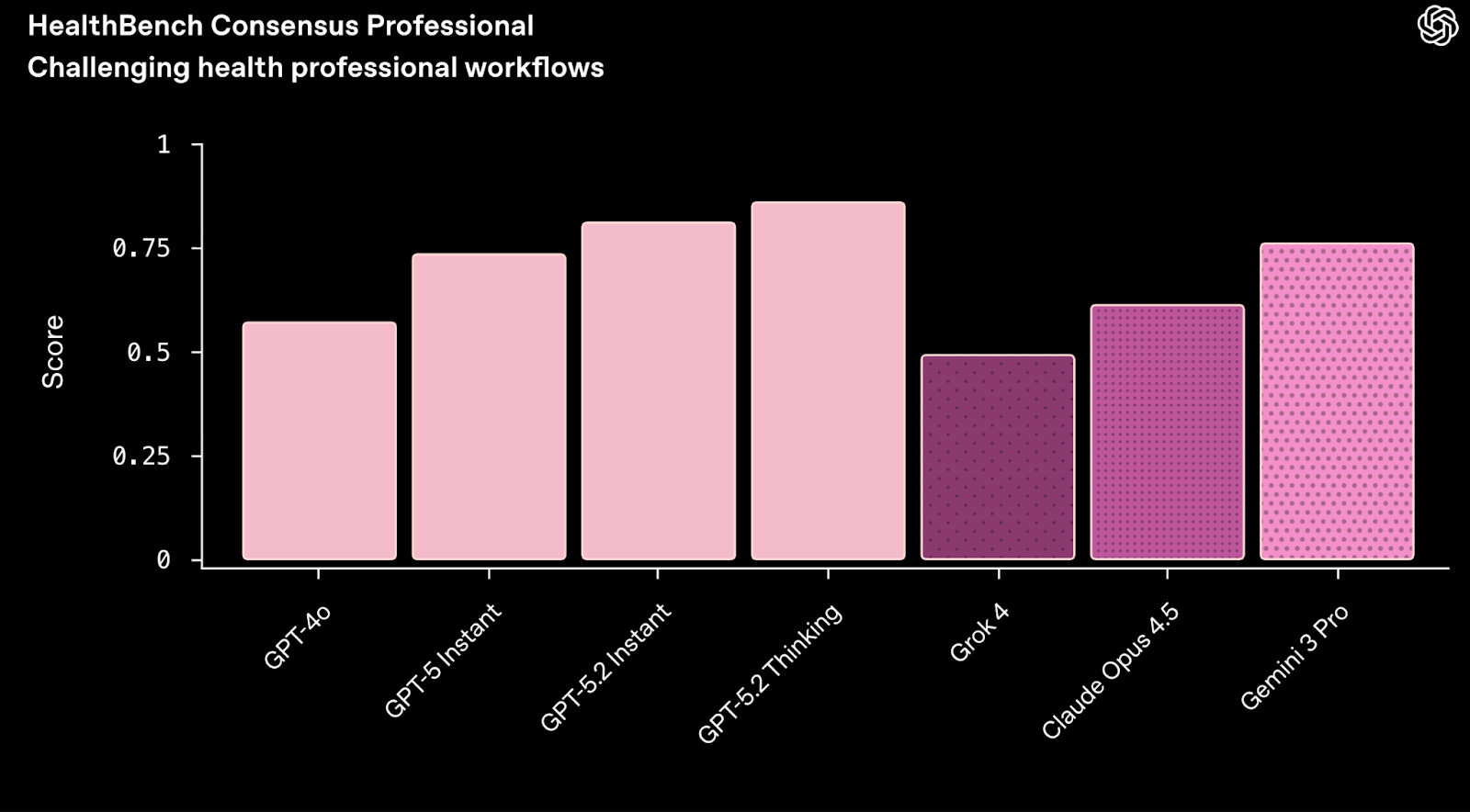
Due to this, I think most of the best AI health applications are likely going to be custom-built assistants for health experts where these safeguards can be ingrained — both for experts in the loop and privacy and security settings. The new OpenAI for Healthcare initiative should reduce friction in building and deploying these custom models. OpenAI models have been making solid progress on professional healthcare benchmarks, but I expect we will be seeing many more custom models for this industry in the future.
Why should you care?
The trajectory is not “LLMs replace clinicians.” The near-term future is more mundane: LLMs become the interface layer between messy data and the humans who make decisions. The competitive edge shifts from nicer phrasing to provable work, the ability to reconstruct what the system saw, what it retrieved, and why it responded that way. Deep integration will beat standalone brilliance.
I think the winning products will add friction in the right places: mandatory source views, explicit uncertainty, and refusal when context is missing. The safest interaction patterns need to be the easiest ones. For users, treat these tools as idea generators and preparation aids. They are genuinely helpful for surfacing possibilities you might not have considered and for helping you prepare for conversations with professionals. The key is to keep experts in the loop so they can do what they do best: separate the signal from the noise.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI Launched ChatGPT Health
OpenAI introduces ChatGPT Health, a dedicated health and wellness experience with connected records and app data. OpenAI launched ChatGPT Health as a separate in-product experience designed to securely combine ChatGPT with user health context, including the ability to connect medical records and wellness apps such as Apple Health, Function, and MyFitnessPal for tasks like understanding lab results, preparing for doctor appointments, and interpreting wearable data. OpenAI says Health adds layered protections on top of existing ChatGPT controls, including purpose-built encryption and isolation for health conversations, and it was developed with input from physicians globally. Access is rolling out via a waitlist; once approved, users can select “Health” from the ChatGPT sidebar to begin.
2. Google Is Testing a New Image AI, and It’s Going To Be Its Fastest Model
Google tests “Nano Banana 2 Flash,” a faster Gemini Flash image model. The report says Google is internally testing the model, expected to run faster and be more affordable than Nano Banana Pro, while remaining less capable than the top-end model. The model name was spotted in a leak shared on X, and the report places it within Google’s “Flash” lineup, which emphasizes speed. There’s no public launch or access path described yet beyond the indication that it is in testing.
NVIDIA announced the Alpamayo family of open models, tools, and datasets aimed at long-tail autonomous driving scenarios, centered on chain-of-thought vision-language-action (VLA) models backed by the NVIDIA Halos safety system. The initial release includes Alpamayo 1, a 10B-parameter reasoning VLA teacher model that uses video input to produce driving trajectories alongside reasoning traces, with open weights and open-source inference scripts; NVIDIA also released AlpaSim, an open-source end-to-end AV simulation framework on GitHub, and “Physical AI Open Datasets” with 1,700+ hours of driving data available on Hugging Face. Alpamayo 1 is available on Hugging Face, and NVIDIA describes it as a foundation developers can fine-tune and distill into smaller runtime models or use to build evaluators and auto-labeling systems.
4. NVIDIA Launches Rubin Platform
NVIDIA announced its Rubin platform, built around “extreme codesign” across six components: Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet to cut training time and reduce inference token cost. NVIDIA says Rubin can reduce inference token cost by up to 10× and train MoE models with 4× fewer GPUs than Blackwell. It also introduced an Inference Context Memory Storage Platform (powered by BlueField-4) to enable the sharing and reuse of KV-cache data for agentic workloads. The flagship rack-scale system, Vera Rubin NVL72, combines 72 Rubin GPUs and 36 Vera CPUs, and NVIDIA says Rubin is in full production with Rubin-based products available from partners in the second half of 2026.
5. TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model
Technology Innovation Institute (TII) introduced Falcon-H1R 7B, a decoder-only model that combines a hybrid Transformer–Mamba backbone with a two-stage training pipeline (cold-start SFT followed by GRPO reinforcement learning) and a test-time scaling method called Deep Think with Confidence (DeepConf) to boost reasoning while keeping token use lower. The release includes full checkpoints and quantized GGUF weights on Hugging Face, plus a hosted Falcon Chat experience and demo links for trying the model.
6. Cursor Introduces Dynamic Context Discovery
Cursor published a research note describing dynamic context discovery. Instead of stuffing a large static context prompt into every run, the agent starts with less and retrieves what it needs as it goes, reducing confusion and cutting token usage on long trajectories. Cursor outlines several concrete implementations, including converting long tool outputs into files, referencing chat history during summarization, supporting the Agent Skills open standard, loading only the MCP tools needed for a task, and treating integrated terminal sessions as files so agents can selectively pull relevant slices.
Five 5-minute reads/videos to keep you learning
1. Context Rot: The Silent Killer of AI Agents
This article examines context rot, a common issue in which AI agents lose effectiveness over long tasks as their context window fills with irrelevant information. It introduces context engineering as the practice of managing the information an AI model sees at any given moment. The piece details retrieval strategies, such as loading data upfront versus just-in-time. For more extended operations, it outlines techniques such as context compaction (summarizing history), structured note-taking to preserve key details, and the use of sub-agents for specialized functions.
2. Evolution of Vision Language Models and Multi-Modal Learning
To address the limitations of text-only AI, Vision-Language Models (VLMs) were developed to process both visual and textual information. This piece traces their evolution, starting with foundational models such as CLIP and GLIP and moving on to open-source systems such as LLaVA and the multilingual Qwen-VL. It also covers the trend toward smaller, efficient models for edge devices alongside powerful, natively multi-modal systems like Google’s Gemini. The discussion also outlines persistent challenges, including hallucinations and resource intensity, while highlighting future research focused on improved reasoning, interpretability, and domain-specific applications.
3. Fine-Tuning Large Language Models (LLMs) Without Catastrophic Forgetting
This piece provides a practical guide to fine-tuning large language models while avoiding catastrophic forgetting, the loss of general knowledge. It focuses on Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA and QLoRA. The core strategy is to freeze the original model’s weights and add small, trainable matrices to specific upper layers, particularly the attention mechanism. This allows the model to adapt to new domains without overwriting its foundational capabilities. The summary also touches on best practices, including learning rate schedules and using multiple, isolated LoRA adapters for different tasks to maintain performance across various domains.
4. Why AI Agents Fail Without Guardrails (And How to Fix It)
AI agents, capable of autonomous actions, pose significant risks, including data leaks and operational errors, without proper safety measures. This piece outlines the critical role of guardrails, checkpoints designed to monitor, block, or require human approval for agent actions. It distinguishes between fast, pattern-matching guards for PII detection and more advanced AI-based checks for contextual safety. The author provides practical implementation examples for PII redaction and human-in-the-loop workflows for high-risk operations.
5. From Perceptrons to Sigmoid Superstars: Building Smarter Neural Networks
This article provides a foundational overview of neural network development, starting with the basic perceptron as a linear classifier. It explains the critical shift to sigmoid neurons, whose smooth activation functions were necessary for enabling gradient-based learning techniques. The post then describes how these neurons are organized into layered feedforward architectures to model complex, nonlinear patterns. It also covers the Universal Approximation Theorem, which establishes the theoretical basis for why these networks are such powerful and widely used tools in artificial intelligence.
Repositories & Tools
1. Claude Flow is an AI orchestration platform that combines hive-mind swarm intelligence, persistent memory, and 100+ advanced MCP tools.
2. ChatDev is a zero-code multi-agent orchestration platform.
3. Ralph Claude Code is an implementation of Geoffrey Huntley’s technique for Claude Code that enables continuous autonomous development cycles.
4. Nemotron Speech ASR is a new open source transcription model for low-latency use cases like voice agents.
5. SETA is a toolkit and environment stack that focuses on reinforcement learning for terminal agents.
Top Papers of The Week
1. LTX-2: Efficient Joint Audio-Visual Foundation Model
LTX-2 introduces an open-source joint audio-visual foundation model that generates high-quality, temporally synchronized video and audio from text. The model uses an asymmetric dual-stream transformer with a 14B video stream and 5B audio stream, linked by bidirectional cross-attention and modality-aware classifier-free guidance, and achieves state-of-the-art open-source audiovisual quality with publicly released weights and code.
2. GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
The paper introduces Group reward-Decoupled Normalization Policy Optimization (GDPO) for multi-reward reinforcement learning with language models. The authors show that applying Group Relative Policy Optimization (GRPO) to combined rewards collapses distinct signals into identical advantages, harming convergence. GDPO decouples reward normalization, preserves relative differences, stabilizes training, and consistently outperforms GRPO on tool use, math, and coding across correctness and constraint metrics.
3. Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
This paper introduces Confucius Code Agent, an open-source AI software engineer built on the Confucius SDK, designed for industrial-scale software repositories and long-running sessions. Confucius SDK is an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results.
4. Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
Researchers propose Entropy-Adaptive Fine-Tuning (EAFT) to mitigate catastrophic forgetting in supervised fine-tuning of large language models. They identify “Confident Conflicts,” low-probability, low-entropy tokens where external supervision clashes with the model’s belief, causing harmful gradients. EAFT gates updates using token-level entropy, learning from uncertain tokens while suppressing conflicting ones, and matches SFT’s domain performance while preserving general capabilities across Qwen and GLM models.
Quick Links
1. Liquid AI releases LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused on device and edge deployments. The model family includes LFM2.5–1.2B-Base and LFM2.5–1.2B-Instruct, and extends to Japanese, vision-language, and audio-language variants. Pretraining for LFM2.5 extends from 10T to 28T tokens, and the Instruct model adds supervised fine-tuning, preference alignment, and large-scale multi-stage reinforcement learning, which push instruction following and tool-use quality beyond other 1B-class baselines.
Who’s Hiring in AI
AI Engineer & Corporate Trainer (French Bilingual) @Towards AI Inc (Remote/Canada)
Agentic AI Teacher @Amazon (Chennai, India)
AI Experience Specialist @Headway EdTech (Multiple US Locations)
AI Engineer Specialist @Digibee Inc. (Remote/Brazil)
SMTS, AI Research @Salesforce (Palo Alto, CA, USA)
Principal QA Engineer — AI & Cloud Services @Aveva (Bengaluru, India)
GenAI Python Systems Engineer — Senior Associate @PwC (Richmond, CA, USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
The AI job market is expanding rapidly, showing how deeply AI is becoming embedded across industries, while platforms like https://hotgames.io continue to reflect the broader digital shift toward instant, browser-based experiences and online entertainment.
Really interesting take on AI in health! Have you considered how ethical implications shape patient trust? It could be a game changer! https://geometrydash-online.io