
TAI #181: DeepSeek's V3.2 "Speciale" Delivery Challenges the US Frontier;
Also, FLUX.2, Runway Gen-4.5, Anthropic's productivity gains study, & more!




What happened this week in AI by Louie
If the last few weeks were defined by the sheer scale of the US tech giants, with Google’s Gemini 3.0 claiming the throne and OpenAI’s GPT-5.1 refining its edge, this week belonged to the nimble specialists. DeepSeek just demonstrated that you don’t need Google’s compute budget to match Google’s reasoning benchmarks, if you’re willing to rethink attention from first principles. The headline act was DeepSeek v3.2, a new family of models that set a new ceiling for open-weight reasoning. We also saw great progress from small players in image and video generation from Black Forest Labs and Runway, respectively.
DeepSeek first dropped DeepSeekMath-V2, a specialist narrow model that acts as a “math prover” using a generator-verifier architecture. By training a verifier to critique the generator’s proofs and then scaling up the test‑time compute, it hit 118/120 on the Putnam 2024 competition and gold‑level performance on IMO 2025 and CMO 2024.
They followed this with the launch of DeepSeek-V3.2, a generalist “daily driver” model. It features a new architectural trick called DeepSeek Sparse Attention (DSA). DSA dynamically selects only the most relevant tokens to attend to (using a “lightning indexer”), reducing the computational complexity of processing long context from quadratic to near-linear. This allows V3.2 to handle 128k context windows with high efficiency, resulting in an API price cut of roughly 50% to 75% compared to the previous generation. The public API is listed at $0.28 per million input tokens and $0.42 per million output tokens.
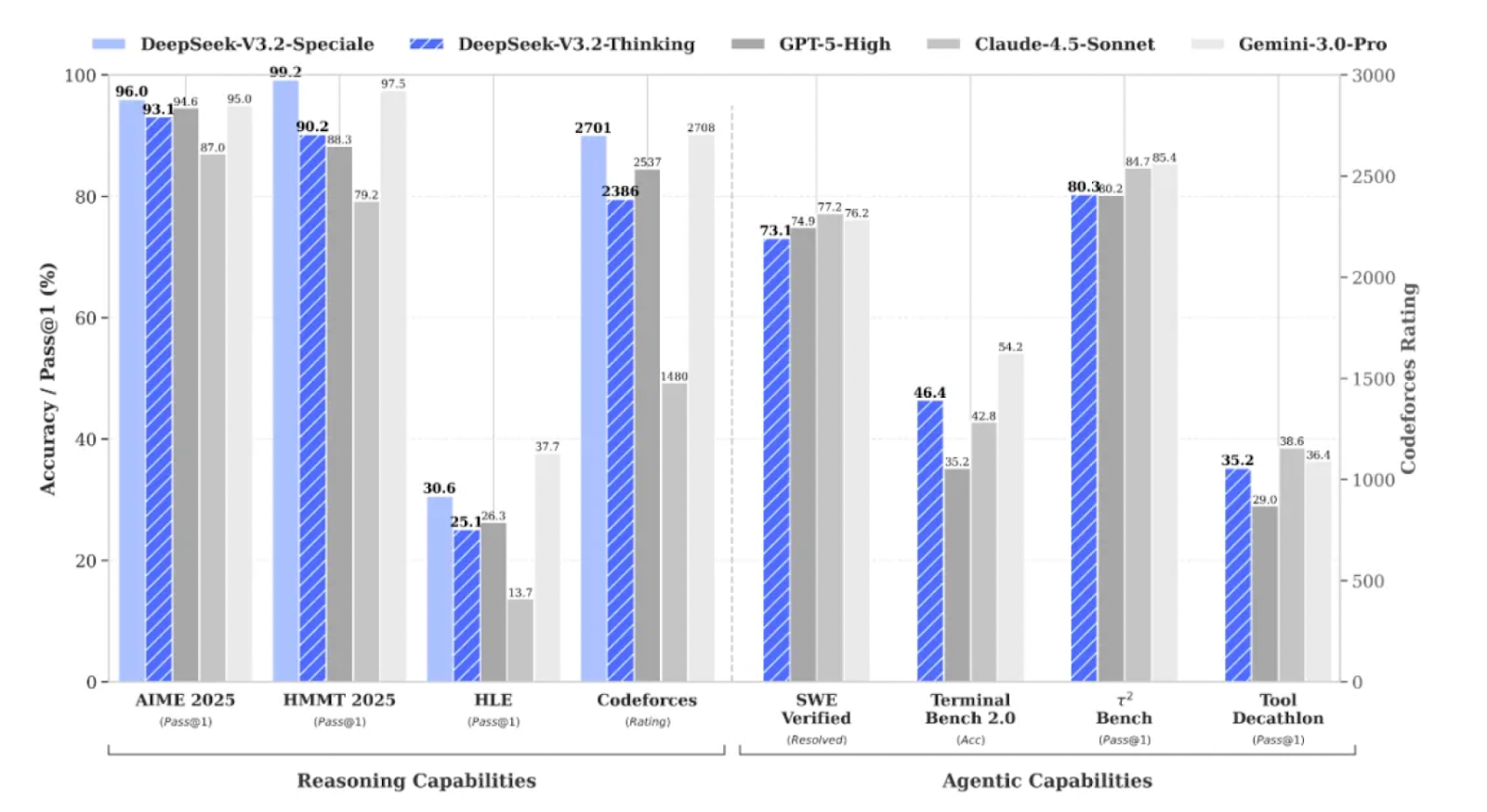
Perhaps more significantly, they also released DeepSeek-V3.2-Speciale. The “Speciale” high-compute reasoning model abandons tool use and focuses entirely on deep reinforcement learning chains, using an upgraded Group Relative Policy Optimization (GRPO) framework. The team implemented an “Unbiased KL Estimate” to fix estimation errors in previous RL methods. It also used “Off-Policy Sequence Masking” to stabilize training when the model diverges from its reference policy.
The result is a model that achieves gold-medal level performance in the International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). That said, for multimodal capabilities and broader exams like Humanity’s Last Exam, and coding suites like SWE‑bench Verified, Gemini 3 Pro, and Claude Opus 4.5, still hold a visible lead.
V3.2-Speciale’s performance also comes at a cost: Speciale requires nearly twice the output tokens to match Gemini 3.0 Pro’s quality on comparable tasks. Nevertheless, it creates a headache for US policymakers, who claim American AI dominance in pure reasoning tasks; the gap has closed significantly.
The open-weight ecosystem didn’t stop at text. Black Forest Labs released FLUX.2, a significant upgrade to its image generation family. The new model introduces a multi-reference engine capable of processing up to 10 input images to maintain character and style consistency, a massive pain point for professional workflows. While the “Pro” version competes with Google’s Nano Banana on photorealism and adherence, the release sparked some debate regarding the “openness” of its license for the developer weights.
Finally, Runway punched back in the video domain with Gen-4.5. This model, codenamed “Whisper Thunder,” specifically targets physics simulation and motion fidelity. Benchmarks suggest it outperforms Google’s Veo and OpenAI’s Sora on motion smoothness and prompt adherence, positioning it as a top-tier tool for creative professionals despite coming from a much smaller team.
Why should you care?
The narrative that the US giants are pulling away with an insurmountable lead in AI capabilities took a hit this week. DeepSeek is proving that algorithmic innovation, specifically in sparse attention and reinforcement learning, can substitute for raw brute-force compute. The introduction of DSA (DeepSeek Sparse Attention) is a legitimate architectural advance.
By compressing the attention mechanism, they are creating a blueprint (in public) for how we might eventually solve the “infinite context” problem without needing infinite memory.
We are also seeing a clear bifurcation in model design and an increased specialization from Deepseek on certain capabilities. We now have distinct “System 1” models (like the standard DeepSeek V3.2), which are optimized for speed, tool use, and low cost, and “System 2” models (like V3.2-Speciale), which are optimized for deep, slow, verified reasoning. The fact that an open-weight model family can now hit Gold Medal standards on the IMO suggests that the “moat” for proprietary models in pure reasoning tasks is shallower than some AI labs may have hoped!
The success of Runway and Black Forest Labs also reinforces this theme of specialization. While Google and OpenAI try to build “everything apps,” these smaller labs are competing by focusing intensely on specific modalities and workflows (physics-based video, consistent character generation).
For developers and enterprises, the economics are shifting fast. DeepSeek V3.2 offers near-frontier performance for a fraction of the cost of GPT-5.1 or Gemini 3.0. While data privacy and geopolitical concerns regarding Chinese endpoints remain valid hurdles for some Western enterprises, the sheer efficiency of these models makes them impossible to ignore. While Deepseek’s complex, sparse mixture-of-experts architecture has been challenging for third-party inference, many US inference providers are now offering solid API endpoints, and the architecture is also becoming an industry standard, with rumours that Mistral will release its next LLM in this format.
The pressure on OpenAI and Google to lower prices or release their own efficient distilled models will become intense. The AI ecosystem remains fiercely competitive, and the gap between the “AI giants” and smaller specialist labs and open ecosystems is narrower than it looked just last week.
— Louie Peters — Towards AI Co-founder and CEO
Last AI cohort of the year, with our biggest discount!
We’re opening the last AI cohort of the year, and it’s tied to our biggest discount so far: 40% off. The discount stays live only until the kick-off call on December 6.
Cohort kick-off: December 6
Discount: 40% off (code blackfriday auto-applied)
Ends: When the Dec 6 kick-off starts
If your 2026 goal is to move from AI-curious to AI engineer, this is the last cohort, and the best deal to do it with.
👉 Join the December 6 cohort at 40% off
Hottest News
1. DeepSeek AI Releases DeepSeekMath-V2
DeepSeek released DeepSeekMath-V2, an open weights LLM, optimized for natural language theorem proving with self-verification. The model is built on DeepSeek-V3.2-Exp-Base, runs as a 685B parameter mixture of experts, and is available on Hugging Face under an Apache 2.0 license. In evaluations, DeepSeekMath-V2 reaches gold-level scores on IMO 2025 and CMO 2024, and achieves 118 of 120 points on Putnam 2024 when used with scaled-test-time compute.
2. Black Forest Labs Releases FLUX.2
Black Forest Labs has released FLUX.2, its second-generation image generation and editing system. FLUX.2 targets real-world creative workflows, including marketing assets, product photography, design layouts, and complex infographics, with editing support up to 4 megapixels and strong control over layout, logos, and typography. It supports up to 10 visual references for consistent characters, products, and styles, and uses a latent flow architecture coupled with Mistral-3 24B. The family spans FLUX.2 [pro], [flex], [dev] open weights, and upcoming [klein].
3. Anthropic Estimates AI Productivity Gains
Anthropic analyzes 100,000 anonymized Claude chats to estimate task-level time savings and economy-wide effects, finding that tasks would take 1.4 hours without AI and that Claude reduces time by about 80% on average; extrapolated to the U.S. economy, that implies roughly 1.8% annual labor-productivity growth over the next decade (upper bound of recent estimates). By matching tasks to O*NET occupations and BLS wage data, the study estimates these tasks would otherwise cost $55 in human labor.
4. OpenAI Rolls Out Voice in Chat
OpenAI is updating the user interface of its popular AI chatbot so users can access ChatGPT Voice right in their chat, without having to switch to a separate mode. That means you’ll be able to converse with the chatbot and view its responses, including things like shared images, as you talk. This revamped voice mode is now the default and rolling out to all users across web and mobile apps. The update is designed to make voice a first-class interaction for everyday use and aligns with OpenAI’s push toward more natural, multimodal workflows for both consumers and enterprise users.
5. HarmonicMath’s Aristotle Solves Erdős #124
HarmonicMath’s Aristotle found the solution to #124 that has been open for 30 years. Moderators reported a positive solution, while clarifying that a stronger variant from the literature remains open. The bot generated this argument in about 6 hours, and the formal proof system Lean verified it in roughly 1 minute, confirming the result with machine-level certainty. This does not solve the harder, famous variant (which forbids using one and adds a gcd rule); that tougher version remains open.
6. OpenAI Loses Book Piracy Discovery Battle
OpenAI has lost a key discovery battle over internal communications related to the startup deleting two huge datasets of pirated books, a development that further tilts the scales in favor of authors suing the company. OpenAI now has to hand over internal chats about deleting two huge book datasets, which makes it easier for authors to argue willful copyright infringement and push for very high statutory damages per book.
Five 5-minute reads/videos to keep you learning
1. How to Use Frontier Vision LLMs: Qwen3-VL
The article examines the capabilities of Qwen3-VL and explains why Vision Language Models (VLMs) often outperform traditional OCR pipelines. By retaining visual context, such as identifying specific checked boxes, VLMs handle complex document understanding tasks that standard text extraction fails to handle. It also provides a technical walkthrough using the 4B model to perform OCR and extract metadata into structured JSON formats. The piece also discusses current limitations, including high resource demands and occasional inference errors.
2. ARC is a Vision Problem! (Paper Review)
This article reframes the challenge of the traditional symbolic view of the Abstraction and Reasoning Corpus (ARC) as a computer vision problem. It introduces VARC, a method leveraging Vision Transformers and Test-Time Training to treat input grids as images. By leveraging visual priors and data augmentation, the 18M-parameter model achieved performance competitive with that of LLMs.
3. Agents 2.0: From Shallow Loops to Deep Agents
This technical overview focuses on building AI agents that handle multi-step tasks without losing context. It compares “Shallow Agents,” which rely on simple reactive loops, with the emerging “Deep Agent” architecture designed for long-running processes. It also outlines four critical components: explicit planning, sub-agent delegation, persistent memory, and context engineering, that allow systems to maintain state outside the immediate context window.
4. Mastering Transformer Architecture: Handling Long Context with Positional Encoding (PE)
Transformers often struggle with sequences longer than their training data, limiting their effective context windows. This blog explored Positional Encoding (PE) as a solution, categorizing methods into Absolute, Relative, and Hybrid approaches. The author conducted a benchmark experiment, training a small Transformer on synthetic tasks to compare techniques like FAPE, LPE, and Rotary Positional Embeddings (RoPE). The results showed that RoPE provided superior extrapolation capabilities, maintaining accuracy on sequences significantly longer than those seen during training.
5. I Used a Graph To Automate Prompt Knowledge, and It Blew My Mind
Static knowledge retrieval often limits how well AI agents reason in specialized domains. The author explored EGO-Prompt, a method from Johns Hopkins that replaces fixed databases with dynamic Semantic Causal Graphs. By using a “text gradient” feedback loop, the system acts like a student learning from a mentor, automatically correcting its own logic and updating the graph when predictions fail. The post also includes a technical walkthrough for setting up this evolutionary framework in Python.
Repositories & Tools
1. LLM Council project runs a local ChatGPT-style web app that sends a user query through OpenRouter to multiple LLMs, gathers their initial answers, has them anonymously review and rank each other, then lets a designated chairman model compile a final response.
2. Awesome Nano Banana Pro is a list of image prompts sourced from X (Twitter), WeChat, Replicate, and top prompt engineers.
3. Gemini CLI brings Google’s Gemini model to the terminal for agentic coding, enabling multi-step planning, file edits, and shell commands.
4. Better Agents provides a CLI and project standard for building production-ready AI agents.
5. Open Deep Research offers a configurable, open-source deep research agent built on LangGraph that supports multiple LLM providers, search APIs, and MCP servers.
6. HunyuanOCR is an end-to-end OCR expert 1B parameter VLM powered by Hunyuan’s native multimodal architecture.
Top Papers of The Week
1. DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
The paper trains a self-verifiable LLM, DeepSeekMath-V2, for theorem proving by first building an accurate verifier and then using it as a reward model to teach a proof generator to detect and fix its own mistakes. The team scales verification compute and iteratively improves both verifier and generator, tightening the feedback loop over time. Reported results include gold-level scores on IMO 2025 and CMO 2024, and 118/120 on Putnam 2024.
2. ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
The authors introduce ToolOrchestra, a training method for small “orchestrator” models that decide which tools to call and when to call them. Using this recipe, they build Orchestrator (8B), which aligns tool choices to user intent and delivers higher accuracy at lower cost than prior agents. On HLE, Orchestrator scores 37.1%, edging GPT-5 at 35.1%, while being ~2.5× more efficient.
This paper presents Nemotron-Parse-1.1, an 885M encoder–decoder VLM for document OCR that jointly extracts Markdown/LaTeX text, tables, bounding boxes, semantic classes, and layout-aware reading order. It’s trained on a mix of synthetic corpora, public datasets, and NVpdftex-derived data to handle messy real-world pages. The model reports competitive or SOTA results on GOT, OmniDocBench, RD-TableBench, and multilingual OCR tests. Weights are open on Hugging Face, with optimized NIM deployments for high-throughput production pipelines.
4. Soft Adaptive Policy Optimization
The paper proposes SAPO, a group-based RL method that replaces hard ratio clipping with a smooth, temperature-controlled gate, yielding sequence-coherent yet token-adaptive updates. The approach is designed to tame high-variance off-policy tokens, especially in MoE settings, without sacrificing stability. Across math-reasoning tasks and Qwen3-VL training, SAPO improves training stability and boosts Pass@1 versus GRPO and GSPO under similar compute.
5. The Hive Mind is a Single Reinforcement Learning Agent
This work links collective decision-making by imitation to individual trial-and-error learning using the classic nest-hunting behavior of honey bees. By formalizing how simple local rules aggregate, the authors show that the colony’s distributed cognition is equivalent to a single online RL agent acting across many parallel environments. The perspective reframes swarms as unified learners rather than loose collectives. Practically, it points to RL-inspired mechanisms for scalable coordination and adaptability in artificial multi-agent systems.
Who’s Hiring in AI
AI Engineer & Corporate Trainer (French Bilingual) @Towards AI Inc (Remote)
Applied AI, Technical Lead, Forward Deployed AI Engineer @Mistral AI (New York, NY, USA)
Full Stack Software Developer @IBM (Krakow, Poland)
Associate Machine Learning Engineer @Spotify (New York, NY, USA)
AI Engineer (IT Security & Compliance) @Unlimit (Belgrade)
Senior AI Product Manager @Bloomreach (UK/Remote)
[AI LAB] Backend Engineer — Python @Qonto (Paris/Berlin/Milan/Barcelona)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Great roundup. Your coverage really highlights the breakthroughs and competitive dynamics in AI this week.
I talk about latest AI trends and insights. Do check out my Substack, I am sure you’ll find it very relevant and relatable