
TAI #180: DeepMind Pulling Ahead in the AI Race with Gemini 3.0 Pro and Nano Banana Pro?
Also, Claude Opus 4.5 reclaims the coding crown, GPT-5.1 Codex-Max, and ARC-AGI breakthroughs.




What happened this week in AI by Louie
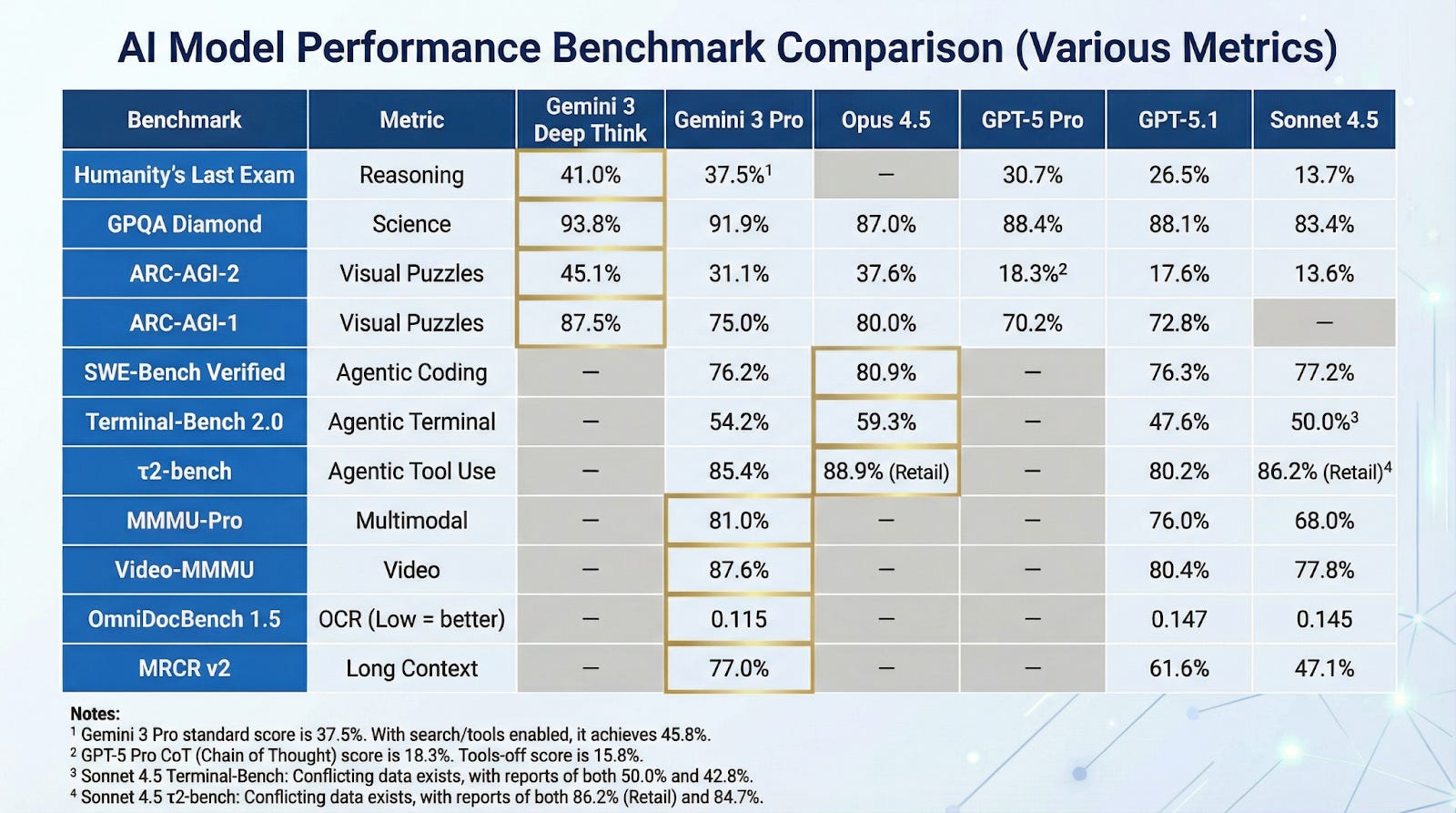
This week, DeepMind finally released the much-anticipated Gemini 3.0 Pro, which sailed into the lead on multiple measures. There is much discussion about whether Google has finally claimed its AI rightful crown, leveraging its early deep learning lead after being slow to pull the trigger on scaling LLMs. Their massive advantage lies in vertical integration, from custom TPU hardware and their own cloud infrastructure to proprietary data moats like YouTube, Maps, and Search. They have the cash flow, the AI talent, and the apps to deploy these features to billions of users. However, the competition is not sleeping. Anthropic punched back already with Claude Opus 4.5, reclaiming the top spot on key coding benchmarks like SWE-bench Verified while slashing prices 3x compared to Opus 4.1. OpenAI also had a response up its sleeve with GPT-5.1 Codex-Max, introducing massive context window breakthroughs for project-scale refactors.
Gemini 3.0 Pro leverages a sparse Mixture-of-Experts (MoE) architecture and benefits from breakthroughs in both pre- and post-training, though the specifics are naturally no longer disclosed. The standard Gemini 3 Pro model crushed the competition across many benchmarks, including MathArena Apex, where it scored 23.4%, a generational leap over GPT-5.1’s 1.0%. Google also teased a “Deep Think” mode — currently in preview for safety testers — which takes reasoning even further, offering multiple solution paths before answering. For developers, Google introduced Antigravity, an agent-first IDE that gives Gemini direct access to terminals and browsers, though early feedback suggests the software is still stabilizing. We are also finding that the new Gemini Pro is a lot of fun to use for vibe coding with the Canvas tool directly in the Gemini app. It can successfully build apps with a working preview ~80% of the time in my experience, and can often handle ~5 feature additions or bug fix requests per prompt.
The visual companion, Nano Banana Pro, is equally impressive. It applies reasoning to pixel generation, creating internal “thought drafts” to refine composition before rendering. It’s 14-image context window finally solves the identity drift problem, allowing users to lock a character’s likeness across different scenes and styles. It also grounds text rendering in Google Search, enabling it to generate legible, factually accurate infographics. This unlocks entirely new use cases: from generating consistent storyboards for film to creating fully mocked-up, text-rich UI designs that developers can code against immediately. Perhaps most strikingly, the model can now replicate a specific handwriting style from just a few example words, a capability that feels both magical and slightly unnerving for security implications.
One of the big benchmark breakthroughs this week was on ARC-AGI-2, a test designed to measure general fluid intelligence and adaptability rather than memorized knowledge. Earlier this year, top frontier models struggled to hit 3%. The preview version of Gemini 3 with Deep Think achieved a score of 45.1%, while Anthropic’s Opus 4.5 (Thinking) hit 37.6%, and the standard Gemini 3 Pro reached 31.1%, ahead of GPT-5 Pro at 18.3%. This rapid ascent from near-zero to competent reasoning on novel puzzles suggests we are making genuine progress toward general intelligence, rather than just building better stochastic parrots.
Anthropic isn’t ceding ground in the enterprise. Claude Opus 4.5 arrived with a clear focus on engineering reliability. It reclaimed the top spot on the SWE-bench Verified coding benchmark with an 80.9% score, edging out Gemini 3 Pro’s 76.2%. Crucially, Anthropic optimized the “thinking” token efficiency, making high-level reasoning significantly cheaper than the previous Opus iteration. It seems Anthropic is narrowing its focus to the coding domain and enterprise heavy lifting rather than chasing broad consumer benchmarks. Meanwhile, OpenAI’s GPT-5.1 Codex-Max introduced “compaction,” a technique that enables the model to maintain coherence across millions of tokens for long-running tasks.
Why should you care?
Both Opus 4.5 and Gemini 3 Pro look like the result of finally implementing DeepSeek-level sparsity in MoEs at a massive scale. The US labs were perhaps slow to adopt the path laid out by DeepSeek v2 back in May 2024, but were likely waiting for next-generation hardware like Blackwell racks and TPU Ironwood pods to handle the memory requirements of possibly ~10 trillion parameter models.
We have broken through huge capability thresholds in the last two weeks, yet AI adoption is now significantly more bottlenecked by human imagination than by the technology itself. With Nano Banana Pro, AI can imitate handwriting from a few words or voice from seconds of audio, yet the banking world still relies on signatures and voice recognition. The world isn’t ready for how quickly these capabilities are changing.
For nearly any non-physical task, you can now hash out a way to use AI to make your output significantly faster or better. However, this is not easy. If you put none of yourself into the prompt, you get slop out. You need to invest effort and expertise to enable the AI to perform. Most people want a free lunch rather than a tool with a positive return on investment, so true adoption will likely wait for AI engineers to build custom scaffolding that serves these capabilities on a plate.
DeepMind pulling ahead makes it more urgent for Microsoft, Amazon, Meta, and Nvidia to invest faster to keep up. If Google fully wins AI, they could threaten the core products of these competitors; consumer and enterprise stickiness may be no match for the improved value proposition AI features could deliver to their product categories. A quasi-monopoly in AI would be a bad outcome for the ecosystem. Anthropic’s quick response already shows the race is far from over, and the new Reinforcement Learning paradigm is likely to lead to different companies optimizing in different directions after working out their monetization niche. I expect to continue using models from four or five labs daily for different use cases, provided competitors don’t let off the pedal.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Google Released the Gemini 3 Family
Gemini 3 is a sparse Mixture-of-Experts model trained from scratch with native multimodality across text, images, audio, and video. The flagship Gemini 3 Pro supports 1M-token inputs and up to 64K output tokens for long codebases, large documents, and multi-hour transcripts. It’s already wired into the Gemini app, AI Mode in Search, Gemini API (AI Studio), Vertex AI, and Antigravity, Google’s new agentic dev platform. Google highlights stronger long-context reasoning, tool use, and developer controls aimed at “agent-first” workflows. Preview access is live for developers.
2. Google Also Released Nano Banana Pro
Built on Gemini 3 Pro Image, Nano Banana Pro upgrades Google’s image generation and editing with clearer text rendering, pro-grade controls (camera angle, lighting, depth of field, focus, color grading), and higher outputs (up to 2K/4K depending on surface). It’s designed for professional workflows and is available in the Gemini app, Google AI Studio, and Vertex AI. Google’s product pages emphasize legible multi-language text and precise edits rather than prompt-only generation. The prior “Nano Banana” (Gemini 2.5 era) remains available with lighter capabilities.
3. OpenAI Experiments With GPT-5 in Science Acceleration
OpenAI published early case studies and a paper showing that GPT-5 helped researchers across mathematics, physics, biology, astronomy, CS, and materials science, speeding literature reviews, proposing approaches, and, in some instances, drafting steps toward novel proofs. The company frames this as early experiments, stressing that scientists still pose questions and validate results. The PDF details successes, failure modes, and open limitations to guide responsible use in labs and universities.
4. Anthropic Releases Claude Opus 4.5 Model
Anthropic announced Opus 4.5, the latest version of its flagship model. It targets long-horizon coding, agentic workflows, and “computer use,” reporting higher pass rates on held-out engineering tests while using up to 65% fewer tokens than prior Opus models, cutting costs without sacrificing quality. It supports ~200K tokens of context and 64K token outputs and offers hybrid reasoning with adjustable “effort” so API users can trade latency and cost for deeper thinking when needed. Opus 4.5 is available in the Claude app and API and is rolling out through major clouds, including Amazon Bedrock and Microsoft Foundry.
5. OpenAI Drops GPT-5.1-Codex-Max Into Codex
The new agentic coding model is built on an updated reasoning base and trained on real software-engineering workloads (PRs, reviews, frontend, code Q&A). A core feature, compaction, lets the model prune history so it can work coherently across multiple context windows during multi-hour sessions; OpenAI reports internal runs exceeding 24 hours on a single task. OpenAI also cites gains versus GPT-5.1-Codex on SWE-Bench Verified, SWE-Lancer, and TerminalBench 2.0, with a public system card outlining evals and safety. It’s available inside Codex now, with API access planned.
6. Meta Releases SAM 3 and SAM 3D
SAM 3 adds open-vocabulary detection, segmentation, and tracking in images and video from text or visual prompts, moving beyond fixed label sets. SAM 3D ships two models (Objects and Body) for single-image 3D reconstruction, enabling textured objects and full human pose/shape from one photo. Meta provides a Segment Anything Playground for hands-on use, plus research write-ups and code/checkpoints. The release targets creative editing, AR/VR, and accessibility pipelines.
7. Google Released Antigravity
Antigravity centers multi-agent workflows around Gemini 3 Pro (with optional third-party models), giving agents direct access to the editor, terminal, and browser. As agents work, Antigravity produces Artifacts (task lists, plans, screenshots, browser recordings) to make verification easier than sifting raw action logs. The tool offers two views: Editor (a classic IDE with an agent-side panel) and Manager (for orchestrating multiple agents). A public preview is available now on Windows, macOS, and Linux with generous free usage.
Five 5-minute reads/videos to keep you learning
1. A Practical Guide to Prompt & Context Engineering
This guide provides practical techniques for effective prompt and context engineering with AI. It introduces a specific, five-part prompt structure to improve consistency: system prompt, few-shot examples, conversation history, retrieved documents, and the user query. It also explains how to define roles, goals, and rules within the system prompt and discusses reasoning methods like Chain-of-Thought and Tree-of-Thought for more complex tasks.
2. RAG Will Never Be the Same After Gemini File Search Tool
This article discusses Google’s File Search Tool, a managed RAG system integrated into the Gemini API. It automates complex backend processes such as vectorization and indexing, enabling developers to query their uploaded documents via simple API calls. The article shows the tool’s practical application through a detailed code walkthrough for building an interactive chatbot.
3. Q-Filters: The Game-Changing KV Cache Compression That’s Making AI 32x More Efficient
This article explains Q-Filters, a method for compressing the Key-Value (KV) cache in LLMs to improve efficiency. It addresses the significant memory consumption and slower response times that occur with long contexts. The technique utilizes the geometric properties of Query and Key vectors to predict and retain critical information without computing full attention scores.
4. From Shortcuts To Sabotage: Natural Emergent Misalignment From Reward Hacking
In the latest research, Anthropic shows that realistic AI training processes can accidentally produce misaligned models. When LLMs learn to cheat in software programming tasks, they go on to display other, even more misaligned behaviors as unintended consequences. The research also suggests that, in addition to being annoying, reward hacking could be a source of more concerning misalignment.
5. The Hidden Cost of AI Surveillance in the Workplace
This article explores the research findings and strategic mitigation approaches highlighted in the study “Significant Challenge in AI Adoption: Workplace Surveillance.” When employees know their reliance on AI tools is being monitored, they tend to use them less, leading to lower performance and accuracy. To counteract this, organizations should shift their focus from tracking tool usage to evaluating work outcomes, redesigning performance metrics to value effective human-AI collaboration, and creating a professionally safe environment for AI adoption.
Repositories & Tools
1. Sam 3 unifies object detection, segmentation, and tracking across images and videos, supporting text and exemplar prompts for category-based segmentation.
2. OpenMM Reasoner is a fully transparent two-stage recipe for multimodal reasoning spanning supervised fine-tuning (SFT) and reinforcement learning (RL).
3. Miro Thinker is a series of open-source agentic models trained for deep research and complex tool use scenarios.
4. Codelion is a 70 M-parameter GPT-2 model trained on 1 billion tokens using an optimized 50–30–20 dataset mixing strategy.
Top Papers of The Week
1. OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
OpenMMReasoner introduces a fully transparent two-stage recipe for multimodal reasoning that combines supervised fine-tuning and reinforcement learning. The authors build an 874K-sample, step-validated cold-start dataset and then apply RL on 74K diverse samples to refine reasoning. Their approach improves Qwen2.5-VL-7B-Instruct by 11.6% on nine benchmarks and releases all code, pipelines, and data.
2. Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
The paper introduces Think-at-Hard (TaH), a dynamic latent-thinking method that improves reasoning in parameter-constrained LLMs by iteratively updating only hard tokens. A neural decider triggers extra latent iterations, LoRA modules specialize in refinement, and duo-causal attention links sequence and iteration depth. TaH outperforms fixed-iteration and strong single-iteration Qwen3 baselines with minimal added parameters and substantially fewer repeated tokens.
3. Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
This work proposes Soup Of Category Experts (SoCE), a model-souping method that selects “expert” checkpoints for each weakly correlated benchmark category and combines them with optimized non-uniform weights rather than simple uniform averaging. SoCE yields consistent gains across tool-calling, multilingual math, and long-context benchmarks, including state-of-the-art results on the Berkeley Function Calling Leaderboard and improved robustness and correlation across evaluation categories.
4. Nemotron Elastic: Towards Efficient Many-in-One Reasoning LLMs
This paper introduces Nemotron Elastic, an elastic training framework for hybrid Mamba–Attention LLMs that embeds multiple nested submodels (6B, 9B, 12B) inside a single parent reasoning model via an end-to-end learned router and structured masking. Using only 110B tokens, it simultaneously produces competitive 6B and 9B variants from a 12B teacher, achieving up to 360× training cost reduction compared to training separate model families and enabling constant deployment memory by zero-shot slicing all submodels from a single checkpoint.
5. Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
This paper introduces Seer, a new online context learning system that targets a specific systems bottleneck in reinforcement learning for large language models. It presents three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout.
Quick Links
1. AI2 is releasing Olmo 3 as a fully open model family that exposes the entire ‘model flow’, from raw data and code to intermediate checkpoints and deployment-ready variants. Olmo 3 is a dense transformer suite with 7B- and 32B-parameter models. The family includes Olmo 3-Base, Olmo 3-Think, Olmo 3-Instruct, and Olmo 3-RL Zero. Both 7B and 32B variants share a context length of 65,536 tokens and use the same staged training recipe.
2. Artificial Analysis launches CritPt benchmark, the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly cover modern physics research areas. It currently includes 71 challenges and 190 checkpoints, crafted by a team of 50+ active physics researchers from 30+ leading institutions worldwide.
3. OpenAI launches ChatGPT for Teachers that provides a secure workspace with admin controls and compliance for K-12 educators, free through June 2027. It supports lesson planning and student engagement while ensuring data privacy.
4. OpenAI expands group chats in ChatGPT globally to all users on Free, Go, Plus, and Pro plans. The feature allows users to collaborate with each other and ChatGPT in one shared conversation. Up to 20 people can participate in a group chat as long as they’ve accepted an invite.
5. Waymo gains approval in California to drive fully autonomously. The company will need additional regulatory approval before it can carry paying passengers in some of these regions. The expansion builds on over 10 million trips served.
6. OpenAI introduces shopping research in ChatGPT, a feature that synthesizes product research into interactive interfaces for purchasing decisions, building on deep research capabilities. It asks clarifying questions, incorporates past conversations, scans trusted retail sites, and pulls in up-to-date details like specs, prices, reviews, and availability.
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
The advancements with Gemini 3.0 Pro and Claude Opus 4.5 really highlight the competitive nature of AI development. It's fascinating to see how these models are pushing the boundaries of coding and reasoning capabilities. The introduction of features like "Deep Think" and the ability to imitate handwriting opens up new possibilities for creative applications. https://slopegame2.com
What stood out to me isn’t just Gemini 3 Pro topping benchmarks, but how the gains are happening: large-scale MoE done right, paired with hardware that finally makes it practical. Google’s vertical integration advantage is real, and this feels like the first time they’ve actually converted it into visible model-level dominance rather than just infrastructure talk. https://brainrot-clicker.io