
TAI #179: Are We in an AI Bubble? How We Will Fund the AI Buildout.
Also, Grok 4.1 & GPT-5.1 upgrades, ERNIE-4.5-VL-28B-A3B-Thinking & more.




What happened this week in AI by Louie
While everyone eagerly awaits Gemini 3, this week delivered some quieter but meaningful point upgrades that actually make a big difference to daily workflows. xAI and OpenAI released Grok 4.1 and GPT-5.1, respectively, and both updates deliberately shifted focus away from recent obsessions with math, science, and code benchmarks toward writing quality, personality, and emotional intelligence. Grok 4.1 is noticeably warmer and more creative in long-form dialogue and now sits at the top of LMArena’s text arena. It also delivers strong gains on EQ-Bench and a new creative writing benchmark. GPT-5.1 Thinking now follows complex writing rule sets much more obediently and is much more steerable in writing style. It also more dynamically adapts its thinking tokens, saving time on easier tasks while thinking for much longer on harder ones.
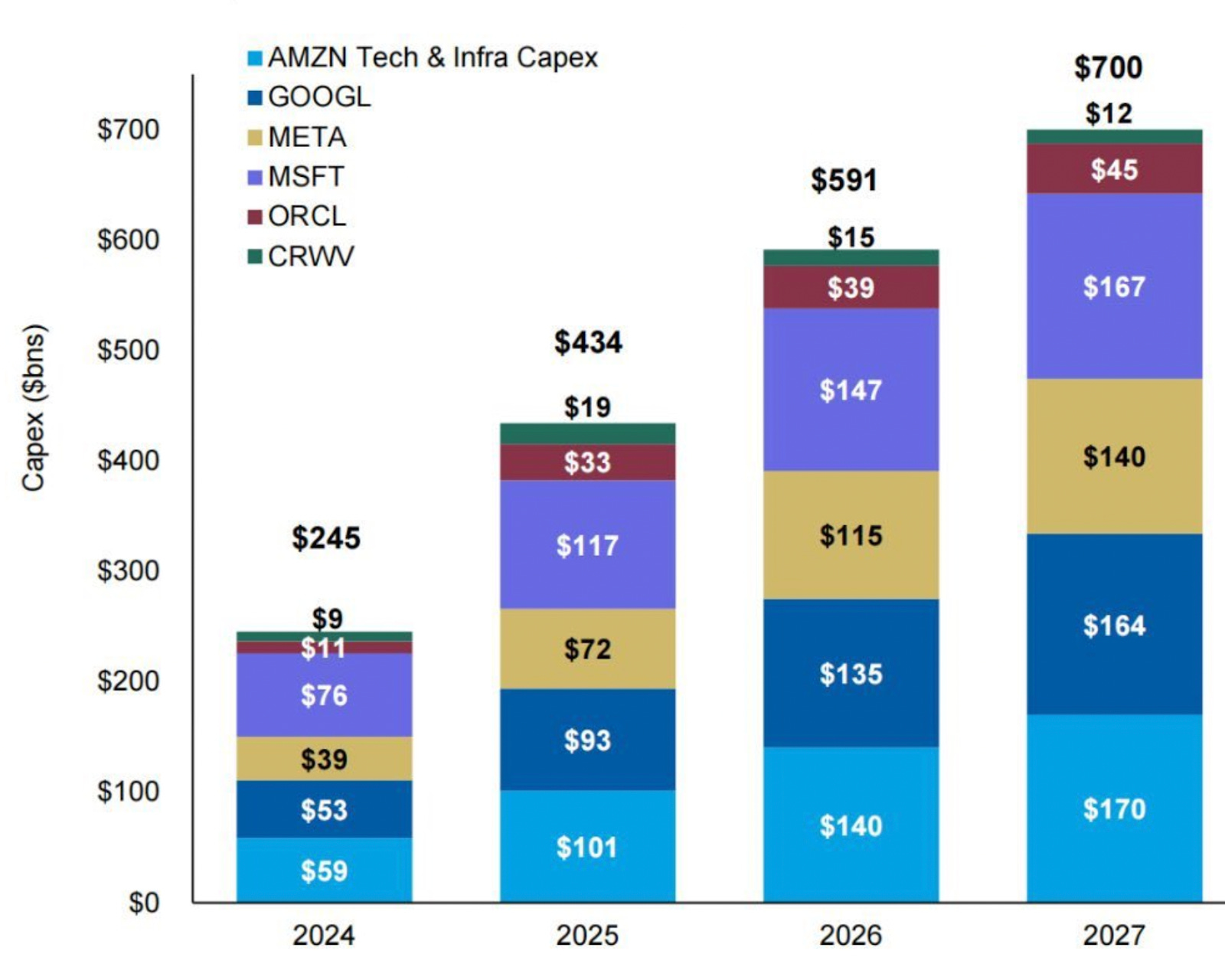
While the labs polish their models’ personalities, the real tension in the AI world lately is elsewhere. Sam Altman has now secured roughly $1.5 trillion in infrastructure commitments, targeting around 30 gigawatts of compute over the next eight years. Internally, he has floated an even more extreme goal of 250 gigawatts by 2033. These numbers, combined with Nvidia’s pledge to invest up to $100 billion in OpenAI, have triggered a new round of AI bubble talk. Many are now trying to answer two questions simultaneously: Are we collectively overbuilding AI infrastructure, and can OpenAI possibly fund its share of this buildout?
Similar to the “Deepseek moment” in January, I think the focus on Sam Altman’s $1.5 trillion plan is a red herring. Sam has been asking for trillions to fund the AI buildout for almost two years, but the important recent change is that Microsoft, Oracle, and Amazon have only now gathered sufficient evidence of AI’s economic value from their own internal projects to commit hundreds of billions in new capex to OpenAI’s buildout.
These companies have already pulled the trigger on building out the first stages of approximately $500 billion in new AI data centers for OpenAI, and it is they who have assumed the risk that OpenAI may not be able to fund its chip rental. This is unlike past bubbles, which were built entirely on speculative capital. These companies’ balance sheets serve as a significant buffer to protect the rest of the AI ecosystem and supply chain. They have not made this investment because they are blind to OpenAI’s payment risk; they have pulled the trigger because they are now confident in the value of AI and that they will find a use for these chips regardless. The decision-makers at Google, Meta, and Tesla/xAI are also scaling up rapidly, partly due to their own internal return on investment signals and because these founder-controlled empires are not going to let Sam run out ahead in the scaling race and hold the only call option on AGI.
The funding paths for this buildout are also more plausible than they appear. OpenAI likely already has sufficient cash secured (SoftBank is committed to close another $30 billion in December) and revenue momentum to fund its chip rental obligations for 2026. To scale up faster, it will need to close on new investment or new cloud partner deals. Sealing Nvidia’s $100 billion investment would be a helpful start, particularly if Nvidia also helps to guarantee debt to fund the data centers. The big tech AI funders also have ample capacity to invest in much more capex growth from here. AMD’s latest forecast suggests a $2.5 trillion industry-wide AI capex by 2030, up from current levels of approximately $500 billion, although most analysts still expect less than $1 trillion. The six tech companies most heavily investing in AI have $670 billion in EBITDA in 2025 and could hit $1.6 trillion in 2030, even without significant AI acceleration, if they sustain their recent growth rates. Given their mostly AA credit ratings and net cash positions, they could also raise over $3 trillion in debt in this time and remain conservatively leveraged. There is ample room for these companies alone to fund even the most ambitious 2030 targets, but they will also have help in the effort from large enterprises, sovereigns, data center colocation developers, bare metal neoclouds, minority JVs with private capital partners, energy companies, and AI labs with VC backers.
The bearish argument that all these GPUs will be retired in just two to three years as new chip generations are released also misses the mark. The reality is that 7–8 year old TPUs and GPUs can still achieve nearly 100% utilization. While the latest chips are optimized for the current highest-volume models, older generations often remain competitive for some models within the vast and growing variety of AI workloads. With very low marginal operating costs, these older chips can continue to run profitably for years.
Why should you care?
AI investment is beneficial for everyone in the ecosystem, as it accelerates the pace of progress, increases the availability of new capabilities, and creates opportunities for building and utilizing these models. I think we are still far from having enough GPUs for everyone. If we stop investing in AI compute too early, it is more likely that only the very wealthy will be able to afford to meet all their AI needs. Continuing this buildout for many more years yet makes it much more likely that we will reach a point where ample AI can be provided to everyone. If we do get ahead of ourselves with the build-out for some period, it is easy for companies to deploy GPUs by scaling up model size in their core business — e.g., larger recommender system models for Reels at Meta, or larger models for AI overviews in search. I don’t think GPUs will ever be sat idle.
Are we in an AI bubble? I don’t think so. I just don’t see it when the vast majority of people and companies are drastically underestimating both current AI capabilities and the pace of progress. The AI buildout is a rational, if aggressive, infrastructure project funded mainly through highly profitable, investment-grade firms with deep pockets and strategic motivations to win. The spending is grounded in simply extrapolating the proven return on investment these companies are already seeing to slower-moving companies, together with the steady march of models toward expert parity on economically valuable tasks, as shown by benchmarks like GDPval. The value is real, but currently it is being captured by a small minority of fast-moving power users and companies that invest in proper integration. The massive infrastructure investment ensures the pace of improvement will continue, but the winners will be those who learn to integrate today’s models and tools into real workflows, not those waiting on the sidelines for the next LLM release.
How long will this pace of AI spending continue? A big acceleration for 2026 already looks locked in, but as we approach 2027, justifying the next leg of investment will require more evidence that a broader group of companies and individuals are successfully adopting AI and that AI end-user revenue surpasses $100 billion. I am confident we will get there, and at Towards AI, we will be helping with this. We offer both complete AI Business Transformation services for companies and our AI Academy courses for individuals. Successfully scaling AI adoption will need the help of millions of AI engineers.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
OpenAI is rolling out GPT-5.1 in two modes: Instant (fast replies) and Thinking (deeper reasoning), plus new developer tools (apply_patch for structured code edits and a constrained shell tool) and finer-grained style controls. The update targets better instruction-following, warmer tone, and stronger coding/agentic workflows; it’s rolling out first to paid ChatGPT plans, with API endpoints for both variants and a system-card addendum covering updated safety evaluations. Older GPT-5 models stay available under “Legacy” during the transition.
xAI has released Grok 4.1, a new model designed to deliver more creative, emotionally aware, and coherent interactions. Grok 4.1 is now available on grok.com, X, and the mobile apps in two versions: a direct, faster “Non-Thinking” model (NT) and a “Thinking” model (T) that generates an internal reasoning trace before responding. The update targets fewer hallucinations and improved “EQ”, while maintaining high response speed.
3. Baidu Releases ERNIE-4.5-VL-28B-A3B-Thinking
Baidu has launched ERNIE-4.5-VL-28B-A3B-Thinking, a new AI model that incorporates image processing into its reasoning process. It activates ~3B parameters per token (28B total), pairs long-context vision+text with tool use, and ships with quickstarts for Transformers, vLLM, FastDeploy, and LoRA fine-tuning. The model card and Baidu’s post highlight stepwise reasoning on images/video (e.g., zoom-then-read, structured detection) and provide configs for deployment and post-training. Weights and usage instructions are live on Hugging Face.
World Labs, the startup founded by AI pioneer Fei-Fei Li, has released its generative world model, Marble, publicly available after a two-month beta with early users. Marble is a multimodal world model that turns text/images/video (and even room layouts) into editable, simulatable 3D scenes, with export to standard formats for downstream engines (Unity/Unreal). GA introduces an in-browser editor and freemium/paid tiers designed for spatial-AI applications, ranging from synthetic data to digital twins.
5. Google DeepMind Introduces SIMA 2
Google DeepMind shared a research preview of SIMA 2, a Gemini-powered agent that learns and follows natural-language instructions inside diverse 3D virtual worlds, moving beyond scripted “game bots” toward teammates that plan, generalize across tasks, and improve with experience. The research preview targets developers/academics; public coverage frames it as a step toward real-world assistants and, eventually, robotics.
6. OpenAI Pilots Group Chats in ChatGPT
OpenAI is testing group chats, allowing multiple people to collaborate in a single thread across web and mobile. Initially rolled out to Free/Go/Plus/Pro users in Japan, New Zealand, South Korea, and Taiwan. Responses are routed by GPT-5.1 Auto; OpenAI says feedback from this pilot will shape expansion to more regions and inform their plans.
7. Anthropic Disrupts AI-Led Espionage Campaign
Anthropic identified and halted a sophisticated AI-driven cyberattack attributed to a Chinese state-sponsored group, targeting tech firms, banks, chemical manufacturers, and government agencies. The campaign utilized Claude Code agents for 80–90% autonomous infiltration, marking the first documented large-scale AI espionage operation without significant human oversight. Mitigation involved enhanced agent safeguards and reporting to affected parties.
Five 5-minute reads/videos to keep you learning
This analysis explains the trade-offs between cost and performance for customizing generative AI applications. It outlines a spectrum of methods, starting with cost-effective prompt engineering and Retrieval-Augmented Generation (RAG) for incorporating external knowledge. For deeper adaptation, it discusses supervised fine-tuning for specific tasks and Continued Pre-Training (CPT) for expanding a model’s foundational understanding of new domains. It also suggests that the most sustainable strategy often involves using the smallest, most efficient model that meets accuracy, latency, and compliance targets.
2. Embeddings Made Easy: How to Teach Machines to Understand Images, Videos, and Audio
Transforming multimedia content, such as images, videos, and audio, into numerical representations, known as embeddings, is a crucial process for machine learning. This is achieved using specific models for each data type: Convolutional Neural Networks (CNNs) for images, 3D CNNs to capture motion in videos, and Mel spectrograms for audio. This article breaks down how they work. Beyond generation, it also explains the logic behind it to help you remember them.
3. This Puzzle Shows Just How Far LLMs Have Progressed in Little Over a Year
This article tested newer models on a geometric coding challenge previously given to GPT-4o in June 2024. The task was to create a Python script to find all squares on a cross-shaped grid. While the earlier model required two hours and over 40 prompts to solve, the newer Claude Sonnet 4.5 generated a correct and complete solution on its first try. This direct comparison highlights the significant progress in AI problem-solving and code generation capabilities over 16 months, showcasing a notable increase in efficiency and accuracy.
4. Visualizing Large-Scale Spiking Neural Networks
To better interpret the complex behavior of brain-inspired spiking neural networks (SNNs), the author presents a custom visualization method using NEST, which simulates a network of excitatory and inhibitory neurons. A Python class, `DynamicSpikingNNVisualizer`, generates real-time, animated views of this network’s activity. The output combines a 3D model where neurons glow upon firing, a raster plot of spikes, and a population activity meter, providing a comprehensive tool for analyzing SNN dynamics.
5. The Great AI Startup Illusion: What 73% of “Revolutionary” Companies Don’t Want You to Know
An analysis of 100 funded AI startups revealed that 73% significantly misrepresent their technology, functioning primarily as wrappers for third-party APIs from providers like OpenAI. Despite marketing claims of “proprietary AI,” many products are built on simple API calls or standard Retrieval-Augmented Generation (RAG) architectures. The author argues that the core issue is not the business model but the lack of transparency. The piece concludes that sustainable differentiation in the AI space comes from strong user experience and domain expertise, rather than deceptive claims about underlying technology, advocating for greater honesty within the industry.
Repositories & Tools
1. ADK is an open-source, code-first Python framework for building, evaluating, and deploying AI agents with flexibility and control.
2. Kilo Code is an open-source VS Code AI agent for planning, building, and fixing code.
3. Skyvern automates browser-based workflows using LLMs and computer vision.
4. MiniMax-M2-REAP-162B-A10B is a memory-efficient version of MiniMax-M2 designed for long-context coding agents.
5. JAX Privacy is a library for differentially private AI.
6. SDialog is an open-source toolkit for building, simulating, and evaluating LLM-based conversational agents.
Top Papers of The Week
1. TiDAR: Think in Diffusion, Talk in Autoregression
TiDAR bridges the quality and speed gap between diffusion and autoregressive models. By drafting tokens using diffusion and sampling outputs autoregressively, TiDAR achieves high throughput and quality. Evaluations show it surpasses speculative decoding and other diffusion models in efficiency, delivering 4.71x to 5.91x more tokens per second while maintaining autoregressive quality levels.
2. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
The authors introduce LeJEPA, a scalable self-supervised learning model based on JEPAs, optimizing embeddings to follow an isotropic Gaussian distribution. LeJEPA combines this with Sketched Isotropic Gaussian Regularization, offering benefits like a single trade-off hyperparameter and linear complexity. Validated across diverse datasets and architectures, it achieves 79% accuracy on imagenet-1k with ViT-H/14.
3. Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Researchers introduced Lumine, an open recipe for generalist agents in 3D open worlds. Lumine employs a vision-language model to unify perception, reasoning, and action, processing pixels to complete tasks efficiently. It achieves human-level efficiency in Genshin Impact and exhibits strong zero-shot cross-game performance in Wuthering Waves and Honkai: Star Rail, marking progress toward versatile agents.
4. SIMA 2 — an Agent That Plays, Reasons, and Learns With You in Virtual 3D Worlds
SIMA 2 is a Gemini-powered generalist agent that operates in commercial and AI-generated 3D games by “seeing” the screen and controlling a virtual keyboard and mouse, following natural-language, sketch, and emoji instructions. It goes beyond the original SIMA by setting its own goals, explaining its plans, generalising skills across games, and continuing to improve through self-play in both human-made and Genie-generated worlds.
Quick Links
1. OpenAI trains weight-sparse transformer models whose internal computations decompose into small, disentangled “circuits,” making it possible to isolate the subnetworks responsible for specific behaviors instead of reverse-engineering a dense tangle of weights. By scaling these sparse models, they show you can maintain strong capabilities while making internal mechanisms more transparent, pointing to a path for safer and more interpretable AI systems.
2. Generalist AI has unveiled GEN-θ, a family of embodied foundation models trained directly on high-fidelity raw physical interaction data instead of internet video or simulation. The system is designed to establish scaling laws for robotics, similar to those of LLMs for text, but now grounded in continuous sensorimotor streams from real robots operating in homes, warehouses, and workplaces.
Who’s Hiring in AI
AI Engineer & Corporate Trainer (French Bilingual) @Towards AI Inc (Remote)
Senior Software Engineer, AI Infra @NVIDIA (Tel Aviv, Israel)
Applied AI Engineer — Enterprise Solutions @Snorkel AI (Redwood City or San Francisco/US)
AI Researcher @Clariti Cloud Inc. (Remote/US)
Technical Support Intern — Hardware and Software Products @IBM (Remote)
Head of Engineering (Quench) @AI Fund (Remote/US)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Not sure why the "bubble" language keeps being mentioned
These infrastructure numbers are huge, but I think they highlight something deeper than bubble risk. AI evolves in full view, yet the definition of intelligence keeps shifting quietly underneath. Every time a model expands what it can do, we move the boundary of what we consider “real intelligence” and treat the breakthrough as incremental. These trillion-dollar buildouts aren’t just bets on future demand. They are signals that AI is gradually becoming part of the background fabric of the world, even as public narratives swing between hype and doubt. The visible story is about capex, but the quieter story is how the concept of intelligence itself is being rewritten as these systems scale.