
TAI #178: Kimi K2 Thinking Steals the Open-Source Crown With a New Agentic Contender
Also, Qwen3-Max-Thinking, META Omnilingual ASR, TPUs in space, and more.




What happened this week in AI by Louie
The AI playing field was reshaped yet again this week with the release of Kimi K2 Thinking from Moonshot AI. This release feels like a big moment for pushing the scaling of agentic tool use further, and has taken the top spot in open-weight AI, now standing as a very strong challenger to the leading US labs.
Kimi K2 Thinking is designed from the ground up for agentic workflows. Moonshot reports K2 Thinking sustains 200–300 consecutive tool calls—surpassing prior agents that often degrade after ~30–50 steps. This allows it to reason coherently through complex, multi-step problems. In one demonstration, the model successfully solved a PhD-level mathematics problem through 23 interleaved reasoning and tool-calling steps.
We are big fans of agentic tool use and web search. Recently, I have started using Grok-4-fast for everyday quick-response searches (I’m quite surprised to count 50 separate threads from just the last week!) and ChatGPT-5-thinking or Pro for more complex queries. It is still hard to implement agentic search via API when building custom pipelines, however, as most LLM providers offer only simple, one-step web search endpoints. Grok-4 and its fast variant, however, package this entire loop with multiple tool calling steps into one API call, and we are starting to see some very strong results in our agent and workflow development projects with this agentic API. Given Kimi’s affordability and focus on many steps of tool use, we hope it too will be packaged into a similar multi-step agentic API.
K2 Thinking is built on a 1-trillion-parameter Mixture-of-Experts (MoE) architecture that activates a more manageable 32 billion parameters during inference. Moonshot AI also used Quantization-Aware Training (QAT) to release the model with native INT4 precision, which they claim doubles generation speed without a significant performance drop. The benchmark results are formidable. K2 Thinking achieved a state-of-the-art 44.9% on Humanity’s Last Exam (with tools) and 71.3% on SWE-Bench Verified. On Artificial Analysis’s Intelligence Index, K2 Thinking scores 67—#1 among open-weights and #2 overall behind GPT-5 at the time of writing.
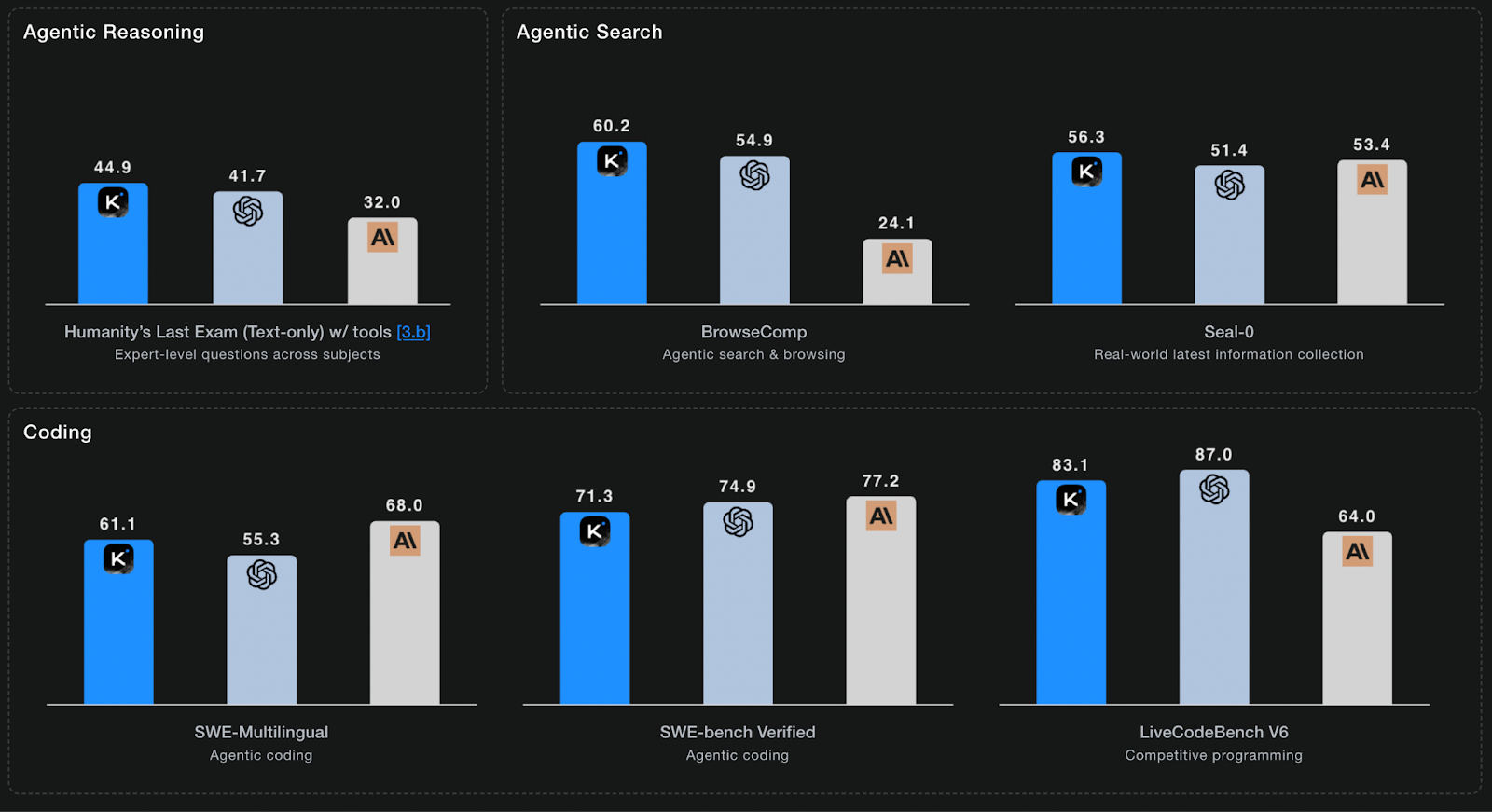
This performance does come with trade-offs we’ve observed firsthand. The model is notably verbose; in our own runs, it used roughly twice the number of tokens as GPT-5-thinking for the same tasks, which has implications for both cost and latency. The open weights, while available, are also substantial, weighing in at nearly 600GB, making self-hosting a resource-intensive endeavor that is out of reach for most hobbyists.
Beyond its technical prowess as an agent, Kimi K2 Thinking has quickly become a new favorite for creative and practical writing. Its style is often described as more natural and less formulaic, sometimes with a literary and emotional depth that most LLMs struggle to deliver.
Why should you care?
This release is a major win for the open-source community, intensifying the competitive pressure on closed US labs. This release also continues the trend of Chinese AI labs rapidly closing the capability gap. For builders, Kimi K2 Thinking is an exciting new tool. Its relatively low API pricing—$0.60 per million input tokens and $2.50 per million output—makes it an economically viable alternative for building sophisticated workflows. However, for some Western companies, the prospect of sending data to a China-based provider remains a significant security and compliance hurdle.
The model’s open weights offer a workaround, with a growing number of third-party inference providers offering endpoints. It’s already live on OpenRouter and Novita, which simplifies plugging K2 Thinking into existing stacks. The initial rollout has seen some of the usual first-week hiccups, however. We’ve noticed performance varies significantly between providers, with some endpoints exhibiting higher latency or hitting errors. Moonshot claims that this has caused some weaker performance in certain third-party benchmarks, which don’t utilize their official API. This is a common challenge with new, complex models as the ecosystem races to launch and then optimize inference.
Given the recent escalation in the AI investment race in the US, it is a welcome sign to still see open weights models competing at the frontier. We think there is a lot of room for the parallel open and closed source LLM ecosystems to both continue to thrive.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Moonshot AI Released Kimi K2 Thinking
Moonshot AI launched Kimi K2 Thinking, a 1T-parameter Mixture-of-Experts reasoning model with 32B active parameters, designed as a “thinking agent” that interleaves chain-of-thought with tool calls. It supports a 256K context window and can execute roughly 200–300 sequential tool calls, achieving state-of-the-art results on agentic benchmarks such as Humanity’s Last Exam (44.9%) and BrowseComp (60.2%), along with strong coding scores on SWE-Bench Verified and LiveCodeBench. The model relies heavily on test-time scaling—expanding both “thinking tokens” and tool turns—and utilizes native INT4 quantization for efficient inference, with access via Moonshot’s platform and open weights on Hugging Face.
2. Google TPUs Tested for Space-Based AI Compute
Google’s Project Suncatcher is exploring orbital data centers that pair solar power with Trillium TPUs, aiming to push large-scale ML workloads beyond Earth’s energy constraints. The company has run early radiation tests at particle accelerators, showing that TPUs can survive space-like radiation, while acknowledging remaining challenges around thermal management and long-term reliability. As part of a partnership with Planet Labs, prototype payloads are slated to launch in 2027, positioning space-based compute as a potential long-horizon complement to terrestrial data centers.
3. Google DeepMind Launches IMO-Bench for Math Reasoning
Google DeepMind introduced IMO-Bench, a math reasoning benchmark suite built around International Mathematical Olympiad–level problems and vetted by medalists, with three components: IMO-AnswerBench for short-answer accuracy, IMO-ProofBench for formal proof generation, and IMO-GradingBench for automated grading of long-form solutions. The framework is designed to support hybrid symbolic–neural approaches and gives a more realistic picture of “gold medal”–level performance than simpler benchmarks. DeepMind reports that its Gemini-based systems reach around 80% on AnswerBench and 65.7% on advanced ProofBench, beating non-Gemini baselines by sizeable margins and providing a new north-star metric for math-focused models and tools like AlphaProof.
4. Qwen3-Max-Thinking: Early Preview and Benchmark Achievements
Alibaba has released an early preview of Qwen3-Max-Thinking, a reasoning-enhanced variant of its 1T+ parameter Qwen3-Max model, which remains an intermediate checkpoint still in training. The model pairs a 262K-token context window with “thinking mode” and test-time compute scaling, and when combined with tool use, it has achieved 100% on challenging math benchmarks like AIME 2025 and HMMT in internal evaluations. Developers can try the preview through Qwen Chat and the Alibaba Cloud Model Studio API, with pricing starting around $1.2/M input and $6/M output tokens, and fuller benchmark coverage promised once the final version ships.
5. Sam Altman Outlines AI Progress Recommendations
OpenAI, led by CEO Sam Altman, published an “AI progress and recommendations” note that argues frontier systems already exceed top human performance on some intellectual competitions and could begin making small scientific discoveries as early as 2026. The document highlights how rapidly dropping compute costs and scaling laws are driving capability growth. It proposes five priorities: shared standards among frontier labs, stronger public oversight and accountability, an AI resilience ecosystem, ongoing measurement and reporting of impacts, and building products that empower individuals rather than just institutions.
6. Amazon Sends Legal Threats to Perplexity Over Agentic Browsing
Amazon has sent a cease-and-desist letter and filed suit against Perplexity over Comet, the startup’s agentic shopping browser that can log into Amazon accounts and make purchases on users’ behalf. Amazon claims Comet violates its terms of service and even computer-fraud statutes by disguising automated activity as human browsing, failing to identify itself as an AI agent, and allegedly degrading Amazon’s personalized shopping experience and security posture. Perplexity has pushed back in public statements and an open letter, arguing that Comet simply acts as a user proxy with credentials stored locally and accusing Amazon of “bullying” and trying to lock out third-party AI agents from its marketplace.
7. OpenAI Enables Query Interruptions
OpenAI rolled out a new ChatGPT feature that lets users interrupt long-running queries—especially GPT-5 Pro and Deep Research runs—and add new context without restarting or losing progress. By clicking an “Update” button in the sidebar, users can inject extra constraints, corrections, or details while the model is still “thinking,” and the system adjusts its ongoing reasoning accordingly.
8. Meta Releases Omnilingual ASR Models
Meta has launched Omnilingual ASR, an open-source automatic speech recognition suite that natively supports more than 1,600 languages, including approximately 500 low-resource languages that previously had no ASR coverage. This is achieved using a 7B-parameter wav2vec 2.0 encoder and several decoder families. Trained on roughly 4.3M hours of audio and released under the Apache 2.0 license, the models achieve character error rates below 10% for about 78% of supported languages and can generalize to over 5,000 languages via zero-shot in-context learning. The release includes the Omnilingual ASR Corpus for over 350 underserved languages and is positioned as a foundation for global transcription, translation, and accessibility tools developed by the broader community.
Five 5-minute reads/videos to keep you learning
1. Code Execution with MCP: Building More Efficient Agents
This blog examines how code execution can facilitate agents’ interaction with MCP servers more efficiently, enabling them to handle more tools while using fewer tokens. It demonstrates how to enhance the efficiency of AI agents by utilizing code execution to integrate with various tools, resulting in a 98.7% reduction in token usage from 150,000 to 2,000. Code execution enables on-demand tool loading, effective data filtering, and streamlined operations without excessive context occupation.
2. Context Engineering for Agents
AI agents rely on a limited “working memory,” or context window, making the management of this information critical for their performance. This article explains that poor context management can lead to issues such as context poisoning and distraction. It outlines four primary strategies to address this: writing context to external storage, such as scratchpads; selecting relevant data through retrieval; compressing information using summarization or trimming; and isolating context by dividing tasks among multiple agents or using sandboxed environments.
3. Building Intelligent RAG Systems: A Deep-Thinking Agentic Approach with LangGraph
Traditional Retrieval-Augmented Generation (RAG) systems often struggle with complex queries requiring multi-step reasoning. This article presents an advanced, agentic architecture using LangGraph to address these limitations. The system first decomposes a query into a research plan, then executes a multi-stage retrieval process that includes diverse search strategies, precision reranking, and web search integration. It incorporates self-critique loops to evaluate progress and determine when enough information has been gathered before synthesizing a final, cited answer.
4. Practical Design Patterns for Agentic Systems
This piece outlines a spectrum of “agentic systems” in which LLMs hold varying levels of control over application workflows. It details seven practical design patterns, starting with structured approaches such as controlled flows and utilizing an LLM as a router. More advanced patterns include parallelization for efficiency, a reflect-and-critique loop for iterative refinement, and incorporating a human-in-the-loop for validation. The discussion extends to tool-using agents and collaborative multi-agent architectures.
This article finds that LLMs often prioritize helpfulness over business compliance, leading to premature solutions such as immediate refunds. This piece outlines how architectural constraints, specifically a two-phase process for information gathering and then resolution, proved more effective than simple prompt engineering. To measure success, a dual evaluation framework was implemented, combining semantic similarity with an LLM-as-Judge model. This approach provided a more nuanced understanding of the agent’s performance, catching subtle errors that a single metric would have missed.
6. I Reverse-Engineered 200 AI Startups. 146 Are Selling You Repackaged ChatGPT and Claude with New UI
This article examines 200 funded AI startups and finds that 73% primarily repackage third-party APIs from providers such as OpenAI and Anthropic, despite claims of proprietary technology. By analyzing network traffic and code, the author found that many companies utilize simple system prompts or standard Retrieval-Augmented Generation (RAG) architectures, which are often marketed as unique innovations. The analysis highlights a significant gap between marketing and technical reality, arguing that the issue is not the use of APIs but the lack of transparency.
Repositories & Tools
1. Kosong is an LLM abstraction layer designed for modern AI agent applications.
2. ADK Go is an open-source, code-first Go toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control.
3. Gelato is a grounding model for GUI computer-use tasks, trained on an open-sourced 🖱️ Click-100k dataset.
Top Papers of The Week
1. Context Engineering 2.0: The Context of Context Engineering
This paper argues that while context engineering is often regarded as a recent innovation of the agent era, related practices can be traced back more than twenty years. It situates context engineering, provides a systematic definition, outlines its historical and conceptual landscape, and examines key design considerations for practice.
2. Towards Robust Mathematical Reasoning
This paper presents IMO-Bench, a suite of advanced reasoning benchmarks vetted by a panel of top specialists that specifically target the level of the International Mathematical Olympiad (IMO). IMO-AnswerBench first tests models on 400 diverse Olympiad problems with verifiable short answers, and IMO-Proof Bench evaluates proof-writing capabilities, which includes both basic and advanced IMO-level problems. Gemini Deep Think achieved 80.0% on IMO-AnswerBench and 65.7% on the advanced IMO-Proof Bench.
3. CodeClash: Benchmarking Goal-Oriented Software Engineering
This paper introduces CodeClash, a benchmark where LMs compete in multi-round tournaments to build the best codebase for achieving a competitive objective. It is designed in two phases, where agents first edit their code, and then their codebases compete head-to-head in a code arena that determines winners based on objectives such as score maximization, resource acquisition, or survival. It runs 1680 tournaments (25,200 rounds total) to evaluate 8 LMs across six arenas.
4. Scaling Agent Learning via Experience Synthesis
This paper introduces DreamGym, a unified framework designed to synthesize diverse experiences with scalability in mind, enabling effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. On non-RL-ready tasks, such as WebArena, DreamGym outperforms all baselines by over 30%.
5. Nested Learning: A New ML Paradigm for Continual Learning
This paper introduces Nested Learning, a new approach to machine learning that views models as a set of smaller, nested optimization problems, each with its own internal workflow, to mitigate or even altogether avoid the issue of “catastrophic forgetting”, where learning new tasks sacrifices proficiency on old tasks.
Who’s Hiring in AI
Senior Technical Writer, Developer Documentation @NVIDIA (Remote/US/Canada)
DevOps Engineer MTS @Salesforce (Atlanta, Georgia)
Collaborative Engineer, GitHub Copilot @Atmosera (Remote/APAC)
AI Outcomes Manager (ANZ) @Glean (Remote)
AI/ML Manager @LeoLabs (Remote)
AI Engineer @Koniag Government Services (Remote)
AI Engineer – Agents @CloudWalk (Remote)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.