
TAI #174: Gemini 2.5 Computer Use Hits SotA but Not Yet an Unlock for Production Agents
Also, Gemini Enterprise, xAI Imagine 0.9, Agentic Context Engineering & more.




What happened this week in AI by Louie
After a frenetic period of product announcements, this week felt much slower on the release front. Following OpenAI’s DevDay deluge, Google offered its response with a slew of new enterprise features and new models. The standout was a new Gemini 2.5 Pro model for “Computer Use,” which looks to be a significant step forward in a surprisingly difficult domain for AI. While rumors swirl that Gemini 3.0 is approaching release, Google is clearly not waiting for the next-generation base model.
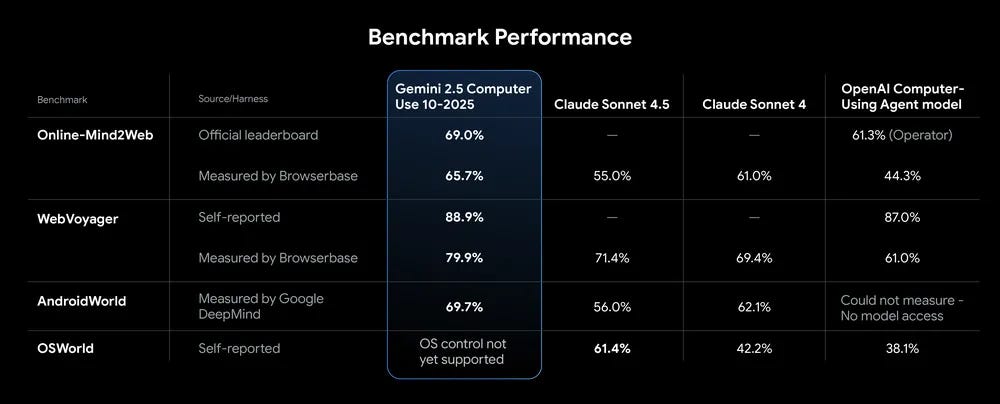
The new Gemini 2.5 Computer Use model is an agent designed to interact with user interfaces, primarily web browsers. It operates in a loop: it “sees” a screenshot, reasons about the user’s goal, and outputs an action like a click or text entry for a tool like Browserbase or Playwright to execute. On the WebVoyager benchmark, it achieved 79.9% accuracy (as measured by Browserbase), surpassing published scores for competing models. While computer use capability could be a huge unlock for many AI use cases, this still doesn’t yet look like the production-ready breakthrough we’ve been waiting for. In our initial tests, we continue to experience difficulties accessing numerous data sources and encountering failures when navigating non-standard layout websites and search filters.
More generally, the open web, unlike the sandboxed world of code, is an actively adversarial environment. Modern websites are designed to keep bots out. Authentication has moved to passkeys and device-bound credentials that headless browsers can’t fake, while services like Cloudflare deploy sophisticated bot detection and challenges. This challenge is compounded by the growing fragmentation of the web’s data moats. Google itself recently limits Search Engine Results Pages (SERPs)
to 10 per page, complicating things for any AI relying on its index (which includes OpenAI), which, until recently, were able to access 100 results. At the same time, YouTube’s data serves as an exclusive training ground and context engineering asset for Gemini, much like X access provides a unique advantage for Grok. Computer use agents have the potential to navigate this by using your own logins for paywalled sources like scientific journals or investment data, but it remains to be seen whether websites will simply block traffic from known AI lab agents.
Beyond the new agent, Google also unveiled Gemini Enterprise, a comprehensive platform that feels like a partial answer to OpenAI’s new AgentKit and Apps in ChatGPT. It unifies six components into a single “front door for AI in the workplace”: Google’s latest models, a no-code workbench for orchestrating agents, a task force of pre-built Google agents, secure connectors to company data, and a central governance framework. The platform also comes with new multimodal agents, such as Google Vids for turning presentations into videos with AI-generated scripts and voiceovers, and real-time speech translation in Google Meet. Like OpenAI, Google is also trying to build the winning platform and ecosystem for its models and boasts over 100,000 partners.
Why should you care?
Last week, we discussed OpenAI’s clear strategy: use massive scale in compute, active users, and an integrated developer platform to build a durable moat. This week, Google showed it’s ready to compete and indeed is already processing 1.3 Quadrillion tokens a month with Gemini (albeit many of them likely through AI search summaries not requested by users). By offering a no-code workbench, pre-built agents, and deep integrations, Google is now making more effort to solve a core problem holding back enterprise adoption: the complexity of stitching everything together.
The progress on the Computer Use agent is also significant. AI that can not just reason but click, type, and navigate across real apps could unlock agents that can file an expense report from receipts, onboard a new hire across a dozen SaaS tools, or run weekly back-office routines that currently involve hours of tab-juggling. That’s the promise. But for all the talk of AGI, the inability of models to reliably do this has been a practical and somewhat embarrassing limitation. This is far harder than it looks, and the Achilles’ heel for this entire class of agents may be the web itself, which is actively fighting back against automation.
The competition in AI is shifting to who can provide the most powerful, reliable, and integrated platform for building and deploying agents that can perform real work. And as data becomes increasingly siloed, the choice of which model to use in your AI pipeline may depend as much on what proprietary data it can access — be it YouTube, Google Search, or X — as its raw intelligence. While OpenAI made a big splash with its developer-focused tools and compute ambitions, Google is countering by starting to take advantage of its existing proprietary data and products to build a deeply integrated, enterprise-first vision. The game is on.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI’s Sora Has Already Hit More Than 1 Million Downloads
OpenAI’s Sora app reached 1 million downloads in under five days, surpassing ChatGPT’s initial performance despite being invite-only. Launching on September 30, 2025, in the U.S. and Canada, Sora hit 627,000 downloads in its first week, with a high of 107,800 daily iOS downloads. Already, the Sora app has sparked backlash after users began generating copyrighted characters in circumstances far from brand-friendly, leading OpenAI to give those copyright holders more control over their content.
2. Google Released Gemini 2.5 Computer Use
Google DeepMind has released the Gemini 2.5 Computer Use model, a specialized version of its Gemini 2.5 Pro AI that can interact with user interfaces. The model is available in preview via the Gemini API through Google AI Studio and Vertex AI Studio. The model enables AI agents to perform tasks by directly interacting with graphical interfaces, including filling forms, clicking buttons, scrolling, and operating behind logins. Developers access the model through the computer-use tool, which operates in a loop. Inputs include the user request, a screenshot of the environment, and a history of recent actions. The model generates responses in the form of UI actions, which are executed by client-side code. The loop continues with updated screenshots and context until the task is completed or terminated.
3. xAI Releases Imagine v0.9 Video Model
xAI announced Imagine v0.9, a major update to its Grok “Imagine” text-and-image-to-video family that, for the first time in its pipeline, generates synchronized audio inside produced video clips. This upgraded video generation model supports converting static images directly into dynamic videos and seamlessly integrates background music, dialogue, and even singing elements, allowing ordinary users to easily “direct” professional-level short films.
4. OpenAI Is Trying To Clamp Down on ‘Bias’ in ChatGPT
OpenAI published a research note outlining a new evaluation for political bias in ChatGPT, built from ~500 prompts spanning 100 topics and five “axes” of bias, and reported that its newest GPT-5 models reduce measured political bias by about 30% versus prior models (e.g., GPT-4o), with bias showing up mainly on emotionally charged prompts; OpenAI says fewer than 0.01% of production responses exhibit political bias and plans to keep iterating on measurement and mitigations.
5. Google Launches Extensions System for Its Command-Line Coding Tool
Google introduced “Gemini CLI Extensions,” a plug-in framework that lets developers connect the open-source Gemini CLI agent to external services (e.g., design tools, payments, databases) and customize terminal workflows; launch partners include Stripe and Figma, and the system is positioned as installable, pre-packaged integrations that expand code generation, debugging, and automation without leaving the command line.
6. Anthropic and IBM Announce Strategic Partnership
IBM and Anthropic unveiled a deal to bring Anthropic’s Claude models into IBM’s software portfolio, starting with an IBM IDE in private preview, to target enterprise development use cases with built-in governance, security, and cost controls; the companies frame the tie-up as advancing “enterprise-ready” AI, with IBM emphasizing measurable productivity gains for clients and broader integration across its stack.
Five 5-minute reads/videos to keep you learning
1. SpikingBrain: Rethinking Attention with Neuromorphic Firepower
To address the computational inefficiency of Transformers with long-context inputs, the SpikingBrain method adapts pre-trained models for enhanced performance. This article guides you through the conversion steps, two hybridisation strategies (serial for 7B and parallel + MoE for 76B), the spiking scheme (integer counts at training time, spike trains at inference), and provides a look at performance trade-offs and open questions.
2. Speculative Decoding for Much Faster LLMs
This article explains speculative decoding, a method for accelerating LLM inference by two to three times without compromising output quality. The technique uses a small “draft” model to propose multiple tokens, which are then verified in a single parallel pass by the larger “target” model. The article covers the core algorithm, discusses variants like self-speculation, and highlights its real-world impact.
3. How AI Models Can Share Hidden Thoughts, Not Just Final Answers
Researchers introduced Mixture of Thoughts (MoT), a method that enables different AI models to collaborate by sharing intermediate reasoning, rather than just final outputs. The article walks you through the architecture, training strategy, inference, benchmark performance, and practical applications.
4. AI Meets Personal Finance: Building a Smart Expense Analyzer with LangGraph
This blog outlines the development of a Smart Expense Analyzer for personal finance management using LangGraph and a Llama model. It walks you through creating an agent that can process bank statements privately on a user’s machine, employing a multi-agent system for specific tasks. The system includes a Streamlit interface for visualizations and a chat agent for direct inquiries.
5. GANs: How AI Creates Images from Noise
This article explains Generative Adversarial Networks (GANs) by comparing them to a prankster (the generator) and a friend who learns to spot the pranks (the discriminator). It details how these two neural networks compete, with the generator creating realistic outputs from random noise and the discriminator trying to distinguish them from real data. It also covers applications like image generation and discusses challenges such as training instability and mode collapse.
Repositories & Tools
1. Claude Code is an agentic coding tool that understands, explains, and executes code through natural language commands.
2. ROMA is a meta-agent framework to build high-performance multi-agent systems.
3. Spring AI Alibaba is an agentic AI framework for building chatbots, workflows, and multi-agent applications.
4. Google Ads API MCP server gives teams a standards-based, read-only path for LLM agents to run GAQL queries against Ads accounts without bespoke SDK wiring.
5. LFM2–8B-A1B is a new generation of hybrid models specifically designed for edge AI and on-device deployment.
Top Papers of The Week
1. Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
This paper introduces ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost.
2. Agent Learning via Early Experience
Researchers introduce a middle-ground paradigm called early experience for language agents, using agent-generated interaction data to improve learning. They study implicit world modeling and self-reflection, enhancing effectiveness and out-of-domain generalization across diverse environments. Early experience shows promise for bridging imitation learning and experience-driven agents, offering a foundation for subsequent reinforcement learning in environments with verifiable rewards.
3. Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
This paper presents Puffin, a unified camera-centric multimodal model that extends spatial awareness along the camera dimension, integrating language regression and diffusion-based generation for spatial intelligence. It was trained on a 4-million triplet dataset, aligning visual cues with photographic terminology. It outperforms specialized models in cross-view tasks, such as spatial imagination, and plans to release code, models, and the dataset pipeline for research advancement.
4. Less is More: Recursive Reasoning with Tiny Networks
The paper introduces Tiny Recursive Model (TRM), which uses a single 7M parameter, 2-layer network to outperform many LLMs in puzzle tasks like ARC-AGI. TRM achieves 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2, showcasing its potential for practical, recursive reasoning with minimal computational resources.
5. Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy
This study evaluates how varying levels of prompt politeness affect model accuracy on multiple-choice questions. It was conducted using a dataset of 50 base questions spanning mathematics, science, and history, each rewritten into five tone variants: Very Polite, Polite, Neutral, Rude, and Very Rude, yielding 250 unique prompts. Impolite prompts consistently outperformed polite ones, with accuracy ranging from 80.8% for Very Polite prompts to 84.8% for Very Rude prompts.
Who’s Hiring in AI
Software Engineer, Product @Meta (Multiple US Locations)
Cyber AI/ML Intern @Leidos (Remote/USA)
Intern — AI Enablement and Technology Transformation @Lumen (Remote/USA)
AI Research Engineer / Orlando, FL @Lockheed Martin (Orlando, FL, USA)
Senior Software Developer, AI Services @Range (Toronto, Canada)
Principal Enterprise AI Engineer @Riot Games (Los Angeles, CA, USA)
AI Engineer @Kyndryl (Bangalore, India)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.