
TAI #172:OpenAI's GDPval Shows AI Nearing Expert Parity on Real-World Work
Also, Claude Sonnet 4.5, Gemini 2.5 updates, META Code World Model, OpenAI's 250GW plans, and more.




What happened this week in AI by Louie
This week feels like a follow-up to last week’s discussion, as our attention was again drawn to both OpenAI’s escalating energy ambitions and additional studies on how AI is being utilized in the workplace. The drumbeat of progress continued with new releases, including Claude Sonnet 4.5, Google’s Gemini 2.5 Flash and Lite upgrades, and its Robotics 1.5 model, as well as a new Code World Model from Meta. OpenAI’s ambitions and hype were again on full display, with Sam Altman mentioning in an internal note that OpenAI will increase its AI compute electricity use 10x to 2GW in 2025. Not happy with 10GW last week, he now targets access to 250GW by 2033, a figure that would represent roughly half of the U.S. grid’s average demand today and imply a staggering $12.5 trillion in capital expenditure. As the industry looks toward a future of nation-scale AI investment, a new benchmark from OpenAI called GDPval provided the most in-depth look yet at what today’s models can already do for high-value knowledge work.
GDPval is a new evaluation that moves beyond academic tests and coding challenges to measure AI performance on economically valuable, real-world tasks. The benchmark includes 1,320 specialized tasks across 44 knowledge-work occupations, from lawyers and software developers to nurses and project managers, which collectively represent over $3 trillion in annual U.S. wages. Each task, designed by an industry professional with over 14 years of experience, is based on a real work product and took a human expert an average of seven hours to complete. In a blinded test, other experts from the same field then judge whether the AI’s output is better than, as good as, or worse than a deliverable produced by a human expert.
The results show that frontier models are rapidly closing the gap with human professionals. In just one year, the win/tie rate for the best models has jumped fourfold, from 12% with GPT-4o to nearly 48% with Claude Opus 4.1. While Claude 4.1 took the top spot, excelling in aesthetics and presentation, GPT-5 was close behind and showed superior performance on tasks requiring pure accuracy and instruction following. This means on a representative set of complex tasks for some of the highest-value jobs in the economy, the best AI model already has a coin-flip chance of matching or beating a human expert. Given that the new Claude Sonnet 4.5, released today, beats Opus 4.1 on most other benchmarks, we wouldn’t be surprised if LLMs have now surpassed the human parity mark on these tasks.
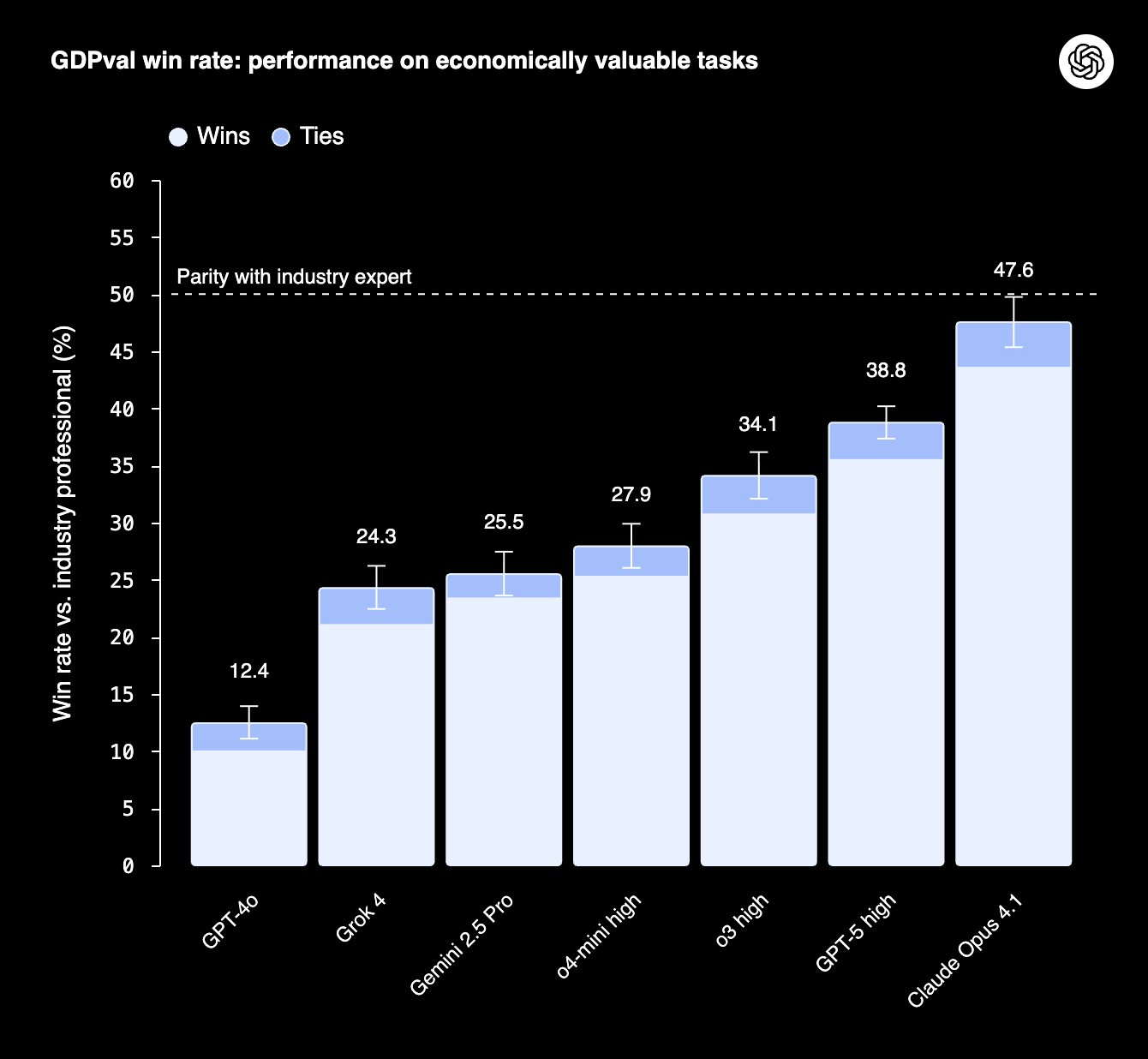
The models also performed these tasks roughly 100 times faster and 100 times cheaper than their human counterparts. Of course, that headline figure conveniently ignores the costs of human oversight, iteration, and integration required to use these models in a real-world workplace. The study also found that simple prompt improvements could boost win rates by another five percentage points, highlighting that performance gains are not just about bigger models but also smarter implementation. However, the study has clear limitations. GDPval is currently a “one-shot” evaluation; it doesn’t capture the iterative, collaborative nature of most real-world knowledge work, which involves feedback, revision, and navigating ambiguity.
Why should you care?
It’s very hard to square the incredible results of the GDPval study with the reality that most people are still struggling to get consistent value from AI on complex work. We looked at the ~220 task subset that OpenAI open-sourced, and they are indeed complex, representative pieces of work that would take an expert many hours to perform. There is no obvious flaw in the study; the flaw looks mostly to be in how most people are using these models.
The prompts used in OpenAI’s study provide a solid amount of detail and expert knowledge — tips, instructions, and warnings on things to watch for — and the models also made use of complex source documents. This is essentially prompting and context engineering 101, but we believe the vast majority of users still fall short on these fundamentals when attempting to utilize AI for high-value tasks. People are still not understanding that it is vital to pack as much of their own expertise into the model as they can; they should be trying to help the model succeed and not just trying to test how it does on its own. Beyond the technical “how,” there’s often a failure of imagination; many people simply don’t know how to begin assigning complex, multi-step work to an AI.
This is compounded by a persistent enterprise problem: access. Many workplaces don’t make it easy to use the best models with enterprise-tier security and privacy plans. The “bring your own model to work” phenomenon means many are still trying to tackle professional tasks with insecure and inferior free-tier models. The GDPval results are a profound signal that AI is ready for much more substantive work, but its economic impact is being throttled by a massive and growing competency gap. The time to master using AI for real work is now. The rapid, linear progress shown in this benchmark is the justification for the seemingly astronomical compute investments being planned. Early movers who invest in building the skills and custom workflows to leverage these capabilities will capture an enormous advantage.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Anthropic Introduces Claude Sonnet 4.5
Anthropic has released Claude Sonnet 4.5, an update focused on coding and agentic workflows. The model shows stronger performance on reasoning, mathematics, and long-horizon tasks. In internal tests, it maintained focus across sessions lasting more than 30 hours. On the OSWorld benchmark for computer use, Claude 4.5 reached 61.4%, compared to 42.2% for Sonnet 4. The release also introduces a VS Code extension, new API features for memory and context, and an Agent SDK. Pricing remains unchanged at $3 per million input tokens and $15 per million output tokens.
2. Nvidia Plans to Invest up to $100B in OpenAI
Nvidia plans to invest up to $100 billion in OpenAI, aiming to build massive data centers for training AI models. This move helps OpenAI diversify from its primary investor, Microsoft. Both companies signed a letter of intent to deploy Nvidia systems for AI infrastructure, with Nvidia acting as OpenAI’s preferred strategic partner for compute and networking.
3. OpenAI Launches ChatGPT Pulse
OpenAI introduced ChatGPT Pulse, a proactive feature that runs overnight to synthesize user chat history, saved memory, and optional connectors like Gmail and Google Calendar into personalized daily briefs delivered as scannable cards on mobile. Limited to Pro subscribers during preview due to high inference costs, this feature includes personalization via conversation-shared preferences, source citations similar to ChatGPT Search, and deliberate design to prevent infinite scrolling. It emphasizes safety checks, source citations, and opt-in data use, with thumbs up/down ratings for feedback.
4. Google DeepMind Releases Gemini Robotics 1.5
Google DeepMind releases Gemini Robotics 1.5, an agentic system comprising Gemini Robotics-ER 1.5 for high-level planning and reasoning, and Gemini Robotics 1.5 for execution, enabling multi-step tasks such as sorting recyclables through web search and human interaction. It achieves state-of-the-art performance on 15 benchmarks, including ERQA (embodied reasoning QA) and Point-Bench (manipulation), with transfer learning across robot embodiments without requiring specialization. Available in preview via Google AI Studio API, it uses natural language for interpretable reasoning sequences and supports tools like Google Search.
5. Microsoft Adds Anthropic’s AI to Copilot
Microsoft has integrated Anthropic’s Claude Sonnet 4.5 and Claude Opus 4.1 into Microsoft 365 Copilot, making them available alongside OpenAI’s models in the Researcher agent and Copilot Studio. Microsoft now lets users choose between OpenAI and Anthropic models within its Microsoft 365 Copilot and Copilot Studio environments.
6. Databricks Will Bake OpenAI Models Into Its Products
Databricks announced that enterprises can now run OpenAI’s GPT-5 models directly within its platform, with support for SQL, APIs, Model Serving, and Agent Bricks. The integration provides governance, monitoring, and security controls for enterprise deployments, enabling organizations to utilize GPT-5 on their own data without requiring additional setup. The move positions Databricks as a hub for building AI agents on enterprise data while maintaining compliance and visibility.
7. Alibaba To Offer Nvidia’s Physical AI Development Tools in Its AI Platform
Alibaba is integrating NVIDIA’s Physical AI software stack into its cloud platform, targeting applications in robotics, autonomous driving, and smart spaces such as factories and warehouses. The tools can generate 3D replicas of real-world environments to create synthetic training data for AI models. As part of the move, Alibaba is also expanding its infrastructure globally, with new data centers coming online in Brazil, France, and the Netherlands, and increasing its AI investments beyond its previous $50 billion target.
Five 5-minute reads/videos to keep you learning
1. Integrating CI/CD Pipelines to Machine Learning Applications
This guide shows how to automate deployment for machine learning applications using a serverless AWS Lambda setup. It walks through a GitHub Actions workflow that runs automated tests, scans for vulnerabilities with Snyk, and builds container images via AWS CodeBuild. After a manual review step, a separate workflow deploys the image to Lambda. The article includes detailed configurations for IAM roles, secure OIDC authentication between GitHub and AWS, and an optional Grafana setup for advanced monitoring.
2. Six Ways to Control Style and Content in Diffusion Models
This article explores six techniques for controlling image generation with diffusion models. It compares resource-intensive methods, such as Dreambooth, with lighter alternatives, including LoRA and IP-Adapters. It also explains how ControlNets provide precise structural guidance. The analysis also highlights trade-offs across the approaches, concluding that combining IP-Adapters for style with ControlNets for structure produces the most reliable results.
3. CSV Plot Agent with LangChain & Streamlit: Your Introduction to Data Agents
This tutorial demonstrates how to create a CSV Plot Agent that automates exploratory data analysis using natural language queries. Using LangChain, GPT-4o-mini, and Streamlit, the agent incorporates Python tools for validating data schemas, identifying missing values, and generating plots, including histograms and scatter plots. The walkthrough covers tool definition, model configuration, agent logic, and UI development with Streamlit.
4. ATOKEN: A Unified Tokenizer for Vision Finally Solves AI’s Biggest Problem
The article explains how ATOKEN is a unified visual tokenizer that handles images, videos, and 3D objects within a single neural architecture. ATOKEN overcomes the traditional need for separate systems for image generation, video processing, and 3D modeling, treating all visual content types in a shared coordinate space that enables models to learn across modalities. The article also highlights how ATOKEN enables perfect 4K image reconstruction, complex video understanding, and 3D model generation, all from a single model.
Repositories & Tools
1. Chrome DevTools MCP lets your coding agent (such as Gemini, Claude, Cursor, or Copilot) control and inspect a live Chrome browser.
2. ShinkaEvolve is a framework that combines LLMs with evolutionary algorithms to drive scientific discovery.
3. Qwen3Guard is a multilingual guardrail model series developed by the Qwen team at Alibaba Cloud.
Top Papers of The Week
1. Qwen3-Omni Technical Report
This paper presents Qwen3-Omni, a single multimodal model that maintains state-of-the-art performance across text, image, audio, and video without any degradation relative to its single-modal counterparts. Its Thinker-Talker MoE architecture integrates text, image, audio, and video processing across 119 languages. The model reduces latency with a causal ConvNet, and its submodels, including Qwen3-Omni-30B-A3B-Captioner, provide accurate captions for diverse audio inputs, publicly released under Apache 2.0 license.
2. Video Models Are Zero-Shot Learners and Reasoners
LLMs revolutionized language processing with zero-shot learning, and now this paper shows how Veo 3 is advancing video models towards a similar trajectory in vision. It can solve a broad variety of tasks it wasn’t explicitly trained for: segmenting objects, detecting edges, editing images, understanding physical properties, recognizing object affordances, simulating tool use, and more. Its visual reasoning skills indicate video models are becoming unified, generalist vision foundation models.
3. Teaching LLMs To Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
This paper presents an instruction-tuning framework, PDDL-Instruct, designed to enhance LLMs’ symbolic planning capabilities through logical chain-of-thought reasoning. By mixing structured reasoning with external verification, LLMs can learn real logical skills. The approach could help models handle planning, coding, and other complex multi-step problems.
4. GAIA: A Benchmark for General AI Assistants
This paper introduces GAIA, a benchmark of 466 real-world tasks. It proposes real-world questions that require a set of fundamental abilities, such as reasoning, multimodal handling, web browsing, and general tool-use proficiency. Instead of superhuman challenges, it focuses on tasks trivial for people but difficult for models, offering a clearer test of practical assistant capabilities.
5. VCRL: Variance-Based Curriculum Reinforcement Learning for Large Language Models
This paper introduces VCRL, a curriculum reinforcement learning framework for large language models, which adjusts training sample difficulty based on reward variance. This method, tested on five mathematical benchmarks and two models, outperforms existing RL approaches by aligning more closely with human learning processes, moving from easier to more challenging tasks.
6. Towards an AI-Augmented Textbook
This paper proposes “Learn Your Way,” an AI pipeline that personalizes textbook content by grade level and interests, then transforms it into multiple representations (immersive text, narrated slides, audio lessons, mind maps) with embedded formative assessment. In a randomized study involving 60 students, the system significantly improved both immediate and three-day retention scores compared to a standard digital reader.
Quick Links
1. Meta launches pro-AI PAC, called the American Technology Excellence Project, is the company’s latest effort to combat policies it sees as harmful to the development of AI. Axios reports that Republican veteran Brian Baker and Democratic consulting firm Hilltop Public Solutions will run Meta’s new super PAC. The focus on parental control arises amid growing concerns about child safety surrounding AI tools.
2. OpenAI introduces GDPval evaluation. GDPval assesses AI on 1320 real-world tasks from 44 GDP-contributing occupations, with expert graders comparing outputs to human work. Claude Opus 4.1 achieves nearly 50% accuracy, matching or exceeding that of experts, while GPT-5 excels in accuracy, with progress tripling in a single year.
Who’s Hiring in AI
Junior AI Engineer (LLM Development and Technical Writing) @Towards AI Inc (Remote)
Software Developer 4 @Oracle (Multiple US Locations)
Gen AI Engineer @Proximate Technologies Inc. (Plano, TX, USA)
AI/ML Engineer @Greenlight Financial Technology (Remote Friendly)
Senior AI Researcher @Charles Schwab (San Francisco, CA, USA)
IT Intern — AI & Emerging Technologies @Dominion Energy (Richmond, CA, USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Recent developments in European sports have expanded opportunities for competitive engagement, highlighting emerging platforms and strategies. Fans increasingly rely on https://nya.is/ to navigate Iceland football betting markets, exploring trends, odds, and tactical insights while following international leagues.
Online game publishing center such as https://cookieclickercity.io and many other online games.