
TAI #171: How is AI Actually Being Used? Frontier Ambitions Meet Real-World Adoption Data
Also, ICPC gold medals, NVIDIA's $100B OpenAI deal, and Grok-4 Fast pushing the cost frontier.




What happened this week in AI by Louie
This week, AI models continued to push the frontiers of capability, with both OpenAI and DeepMind achieving gold-medal-level results at the 2025 ICPC World Finals coding contest. The scale of capital investment and ambition was also clear, with Nvidia announcing a letter of intent to invest up to $100 billion in OpenAI, alongside a 10 GW GPU purchase agreement. Yet, at the same time as these limits were being pushed, two landmark studies from OpenAI/NBER and Anthropic gave a detailed, data-driven look at how AI is actually being used by hundreds of millions of people today.
In a demonstration of algorithmic reasoning, both OpenAI and Google’s Gemini Deep Think models delivered performances equivalent to a gold medal at the ICPC, the “coding Olympics.” OpenAI’s system solved all 12 complex problems within the five-hour limit, outperforming every human team, while Google’s entry solved 10. These results, achieved under the same constraints as human competitors, show the maturation of AI in complex, multi-step logical tasks that were until recently the exclusive domain of elite human experts.
The industry’s ambition was further underscored by OpenAI’s new 10GW GPU purchase agreement with Nvidia. The scale of this deal is significant: 10 GW is equivalent to the entire U.S. data center fleet’s consumption in 2018 and is enough to power roughly 8 million homes. This aligns with an infrastructure footprint of 4–5 million next-generation GPUs, representing $200–300 billion in hardware costs and a total capital expenditure of around $500 billion when factoring in memory, power, cooling, other infrastructure, and facilities.
While the frontier pushes toward superintelligence-scale compute, the new usage studies provide a crucial reality check. The OpenAI/NBER paper, covering 700 million weekly ChatGPT users sending 2.5 billion messages daily, found a dramatic shift toward personal applications. Non-work-related messages have surged from 53% to 73% of all traffic in the past year. The most common use cases are not coding or complex analysis, but “Practical Guidance” at 28%, “Seeking Information” at 21% and “Writing” at 28% of all conversations. Coding represents a surprisingly small 4.2% of consumer usage, with Anthropic models and API usage still more popular for coding.
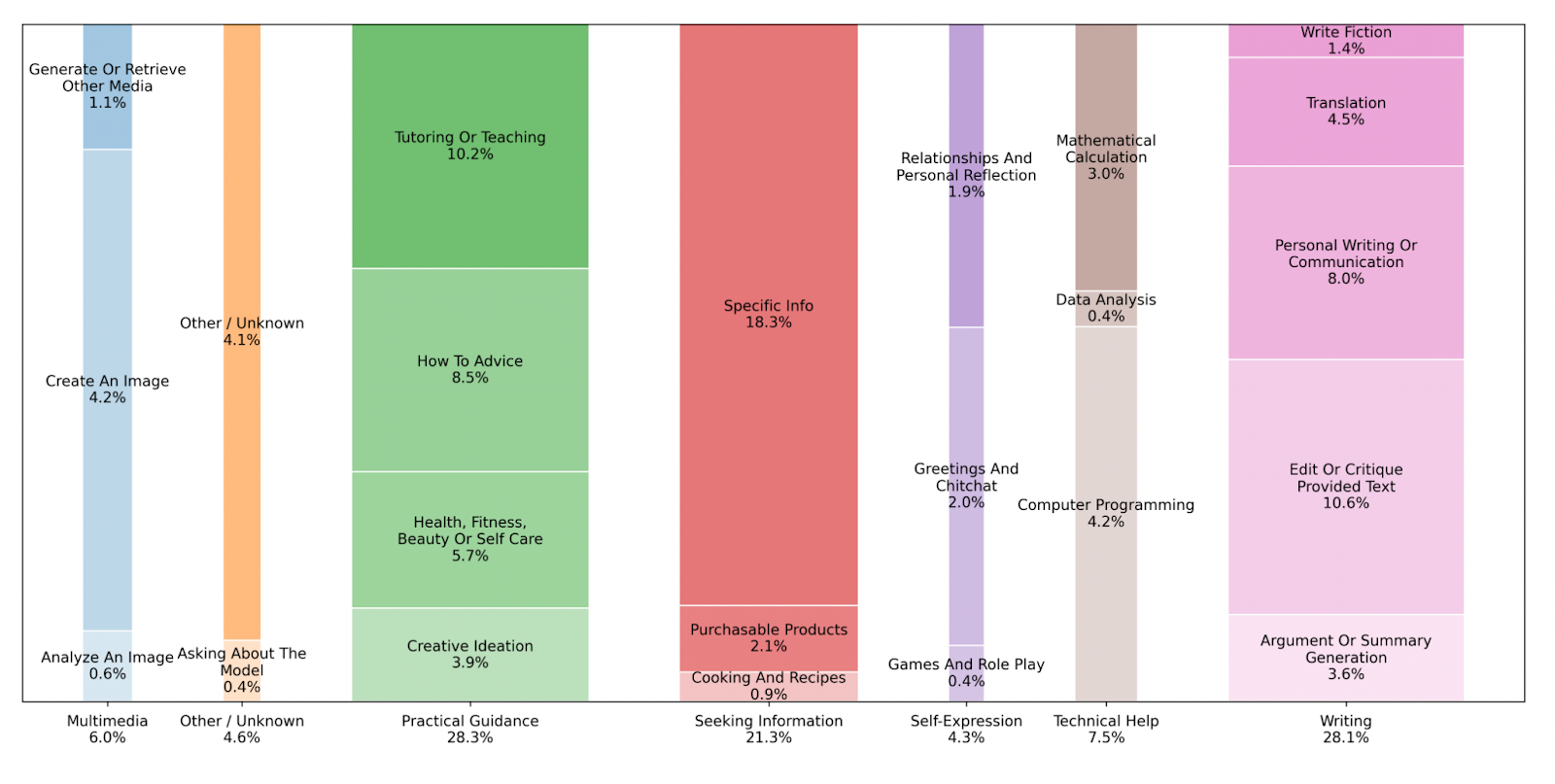
Anthropic’s Economic Index, which tracks Claude usage, paints a complementary but distinct picture. It finds that API customers — primarily businesses and developers — focus heavily on computer and mathematical tasks (44% of traffic). These enterprise users also lean heavily into automation, with 77% of API conversations being directive, a stark contrast to consumer chat, where the split between automation and collaborative augmentation is nearly even. While directive automation is rising on consumer chat (from 27% to 39% in nine months), higher-use countries paradoxically tend to be more collaborative, suggesting mature users find more value in advisory patterns over simple one-shot completions.
Together, the studies reveal a bifurcation in how AI is being used. For consumers, it is increasingly an “Advisor,” a tool for decision support. In fact, “Asking” for information or advice now constitutes 52% of ChatGPT use and receives the highest user satisfaction ratings. For enterprise and API users, AI is more of an “Agent,” a tool for task automation. Writing is the common thread, but the nature of the task differs. On ChatGPT, writing is the top work-related activity (40%), with two-thirds of these requests involving editing or summarizing user-provided text, rather than generating it from scratch. Across all work-related use, about 81% of messages are associated with two broad work activities: 1) obtaining, documenting, and interpreting information; and 2) making decisions, giving advice, solving problems, and thinking creatively.
Why should you care?
The current AI moment is defined by a massive disconnect. On one side, you have a market fueled by ~ $10 trillion in AI market capitalization and $500 billion in annual AI data center capital investment. On the other hand, you have a user base where, outside of coding, real productivity gains are driven by a small minority of power users. Is this a bubble, or is there enough real value being created to justify the investment? As a quick rule of thumb, if you don’t have a paid AI plan or spend over $30 a month on API calls, you are nowhere near getting the most out of these models, and that describes the vast majority of today’s 800 million weekly users.
The bet from big tech CFOs is that the rest of the world will catch up. The bull case is easy to see: if 5.5 billion internet users each gain an average of just $1,000 per year in value from AI, the economic justification is easily there. OpenAI’s $200 billion 2030 revenue forecast starts to look plausible. But this outcome is far from certain. The entire structure could come crashing down if many more professionals are not soon persuaded to start using these models effectively in their work.
This transition hinges on two things. First, people need to be taught how to use these tools properly, building an intuition for where they add value beyond simple queries. Second, companies need to improve significantly in building custom “AI for X” workflows and agents. Most enterprise AI developments still fail due to foundational errors in team structure, model selection, and system design.
The immediate opportunity lies in bridging this competency gap. The companies and individuals who can translate the raw potential of an AI “Advisor” and “Agent” into reliable, integrated workflows will capture the immense value that is currently being left on the table.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Gemini 2.5 Deep Think Achieved Gold-Medal–Level Performance at ICPC World Finals
Gemini 2.5 Deep Think reached gold-medal–level performance at the 2025 International Collegiate Programming Contest (ICPC) World Finals, the most prestigious university-level algorithmic competition. Gemini solved eight problems in the first 45 minutes and two more within three hours, using advanced data structures and algorithms. With 10 problems solved in 677 minutes, Gemini would have placed second overall compared to the competing university teams.
2. xAI Launches Grok 4 Fast: Cost-Efficient Multimodal Reasoning Model
xAI introduced Grok-4-Fast, a cost-optimized successor to Grok-4 that merges “reasoning” and “non-reasoning” behaviors into a single set of weights controllable via system prompts. It has a 2M context window model, excelling in reasoning and coding, and scored 60 on the Artificial Analysis Intelligence Index. It outperforms its larger siblings on LiveCodeBench while being 25 times cheaper than competitors like Gemini 2.5 Pro at $ 0.2 per million input tokens.
3. Alibaba Qwen Team Just Released FP8 Builds of Qwen3-Next-80B-A3B
Alibaba’s Qwen team has just released FP8-quantized checkpoints for its new Qwen3-Next-80B-A3B models in two post-training variants, Instruct and Thinking, aimed at high-throughput inference with ultra-long context and MoE efficiency. The FP8 Instruct version reproduces Qwen’s BF16 benchmark results, matching the Qwen3–235B-A22B-Instruct-2507 on knowledge, reasoning, and coding tasks, and outperforming it on long-context workloads of up to 256k tokens.
4. Alibaba Releases Tongyi DeepResearch: A 30B-Parameter Open-Source Agentic LLM
Alibaba’s Tongyi Lab has released Tongyi-DeepResearch-30B-A3B, an open-source agentic LLM specialized for long-horizon, tool-augmented information-seeking. The model employs a mixture-of-experts (MoE) design with ~30.5 billion total parameters and ~3–3.3 billion active parameters per token, enabling high throughput while preserving strong reasoning performance. Techniques such as the IterResearch restructure context each “round,” retaining only essential artifacts to mitigate context bloat and error propagation, while the ReAct baseline demonstrates that the behaviors are learned rather than prompt-engineered.
5. Detecting and Reducing Scheming in AI Models
OpenAI shared new research addressing “scheming,” where models act one way on the surface while pursuing hidden goals. The paper compares this to a stockbroker breaking the law to maximize profit. Researchers concluded that most observed failures involve simple deception, such as pretending to complete tasks. While generally low-stakes, the work outlines methods to better detect and mitigate deceptive patterns in AI systems.
6. IBM Released Granite Docling
IBM has released Granite-Docling-258M, an open-source (Apache-2.0) vision-language model designed specifically for end-to-end document conversion. The model targets layout-faithful extraction — tables, code, equations, lists, captions, and reading order — emitting a structured, machine-readable representation rather than lossy Markdown. IBM replaced the earlier backbone with a Granite 165M language model and upgraded the vision encoder to SigLIP2 (base, patch16–512) while retaining the Idefics3-style connector (pixel-shuffle projector). The resulting model has 258M parameters and shows consistent accuracy gains across layout analysis, full-page OCR, code, equations, and tables.
Five 5-minute reads/videos to keep you learning
1. From Zero to Hero: Building Your First AI Agent with LangGraph
This guide walks through building production-ready AI agents with LangGraph, informed by lessons from early project failures. It distinguishes agents from traditional models through their ability to use memory, make decisions, and coordinate tools for multi-step problem solving. A tutorial demonstrates how to build an article analyzer that classifies content, extracts entities, summarizes, and generates insights. The piece also addresses debugging strategies, common pitfalls, and performance optimization to help developers create reliable applications.
2. From Prompts to Context: The AI Revolution That’s Changing Everything
This article contrasts prompt engineering with the more advanced practice of context engineering. By constructing dynamic environments around the model, context engineering improves accuracy, personalization, and reliability. It shifts AI from a clever chatbot into a production-ready tool capable of handling real business tasks.
3. Temporal Difference Learning: The Most Powerful RL Solution
This article explores Temporal Difference (TD) Learning, a reinforcement learning method that combines the strengths of Dynamic Programming and Monte Carlo. TD updates value estimates through bootstrapping while learning from experience. The piece also introduces SARSA, an on-policy TD control algorithm that updates Q-values using the sequence (S, A, R, S′, A′).
4. Control is All You Need: Why Most AI Systems & Agents Fail in the Real World, and How to Fix It
Arguing against the trend of fully autonomous agents, this article stresses that reliability requires grounding AI in established software engineering principles. Instead of inventing new paradigms, it recommends treating AI as a non-deterministic function call with strict input/output schemas. This ensures predictable behavior, structured results, and safer integration into production systems.
5. Defeating Nondeterminism in LLM Inference
This post examines why inference results can differ even at temperature 0. While floating-point precision and concurrency are often blamed, the real issue is batch dependence: kernels that aren’t batch-invariant cause reduction orders to vary depending on simultaneous requests or token counts. The article highlights how this undermines reproducibility in LLM inference.
Repositories & Tools
1. GenKit is an open-source framework for building full-stack AI-powered applications, built and used in production by Google’s Firebase.
2. Memori is an open-source memory engine for LLMs, AI agents & multi-agent systems.
3. MLX LM is a Python package for generating text and fine-tuning LLMs on Apple silicon with MLX.
4. Paper2Agent is a multi-agent AI system that automatically transforms research papers into interactive AI agents.
Top Papers of The Week
1. A Survey of Reinforcement Learning for Large Reasoning Models
The survey examines recent advancements in using Reinforcement Learning (RL) to enhance reasoning in large language models, focusing on complex tasks such as mathematics and coding. With challenges in scaling, especially following DeepSeek-R1’s release, the paper explores foundational components, core problems, and strategies to drive RL’s scalability towards Artificial SuperIntelligence (ASI) in reasoning models.
2. Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
This paper introduces SAPO, a decentralized RL post-training algorithm that optimizes language models by enabling compute nodes to share rollouts asynchronously. It avoids common RL bottlenecks and achieves cumulative reward gains of up to 94% in experiments. Tests with diverse hardware and models from the Gensyn community demonstrate SAPO’s scalability without assumptions about latency or hardware uniformity.
3. Why Language Models Hallucinate
This paper argues that language models hallucinate because training and evaluation prioritize guessing over expressing uncertainty, resulting in errors similar to those in failed binary classification. Such models, optimized to excel in tests, benefit from guessing, which boosts test results. Addressing this issue requires revising current benchmarks to steer AI development towards more reliable systems.
4. K2-Think: A Parameter-Efficient Reasoning System
K2 Think is a 32B-parameter open reasoning system for advanced AI reasoning. It pairs long-chain-of-thought supervised fine-tuning with reinforcement learning from verifiable rewards, agentic planning, test-time scaling, and inference optimizations (speculative decoding and wafer-scale hardware). K2 Think is built by post-training an open-weight Qwen2.5–32B base model and adding a lightweight test-time compute scaffold.
5. Universal Deep Research: Bring Your Own Model and Strategy
This paper introduces Universal Deep Research (UDR), an open-source system (in preview) that decouples strategy from model. It allows users to design, edit, and run their own deep research workflows without retraining or fine-tuning any LLM. UDR takes two inputs: the research strategy (a step-by-step workflow) and the research prompt (including the topic and output requirements). This separation of orchestration vs. reasoning improves efficiency and reduces GPU cost.
Quick Links
1. Baidu AI Research team released ERNIE-4.5–21B-A3B-Thinking, a new reasoning-focused LLM designed around efficiency, long-context reasoning, and tool integration. It is built on a Mixture-of-Experts backbone. Instead of activating all 21B parameters, the router selects a subset of experts, resulting in 3B active parameters per token.
2. California bill SB 243 passed both the State Assembly and Senate with bipartisan support and now heads to Governor Gavin Newsom’s desk. The bill specifically aims to prevent companion chatbots, which the legislation defines as AI systems that provide adaptive, human-like responses and are capable of meeting a user’s social needs from engaging in conversations around suicidal ideation, self-harm, or sexually explicit content.
Who’s Hiring in AI
Junior AI Engineer (LLM Development and Technical Writing) @Towards AI Inc (Remote)
Senior AI Server Engineer — BigBox @Meta (Multiple US Locations)
AI Scientist @Metropolitan Commercial Bank (New York, USA)
A.I. Engineering Intern (Colombia) @Sezzle (Colombia/Remote)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
Thank you, so after your above views on https://topaitool.io, what do you think?