
TAI #170: Why Are So Many of the AI Success Stories AI for Coding?
Also, OpenAI upgrades Codex, Qwen3-Next, ERNIE-4.5–21B-A3B-Thinking & more!




What happened this week in AI by Louie
This week, OpenAI released a significant upgrade to its coding platform with GPT-5-Codex, a specialized version of GPT-5 fine-tuned for agentic software engineering. This follows the release of GPT-5, which introduced a smart router to dynamically allocate compute resources based on task complexity. For coding, this approach makes a huge difference; Codex now feels snappy for small, interactive requests while being able to work persistently for over seven hours on complex tasks, such as large-scale refactorings.
The update unifies the Codex experience across the CLI, IDE, web, and GitHub, creating a seamless environment for developers. The performance gains are notable. On the full SWE-Bench Verified dataset, GPT-5-Codex achieves a 74.5% resolution rate, and on a custom code refactoring evaluation, it hits 51.3%, a significant jump from the base GPT-5’s 33.9%. It’s also far more token-efficient on simple tasks, using up to 94% fewer tokens, yet it will spend twice as long reasoning and iterating on the most complex problems.
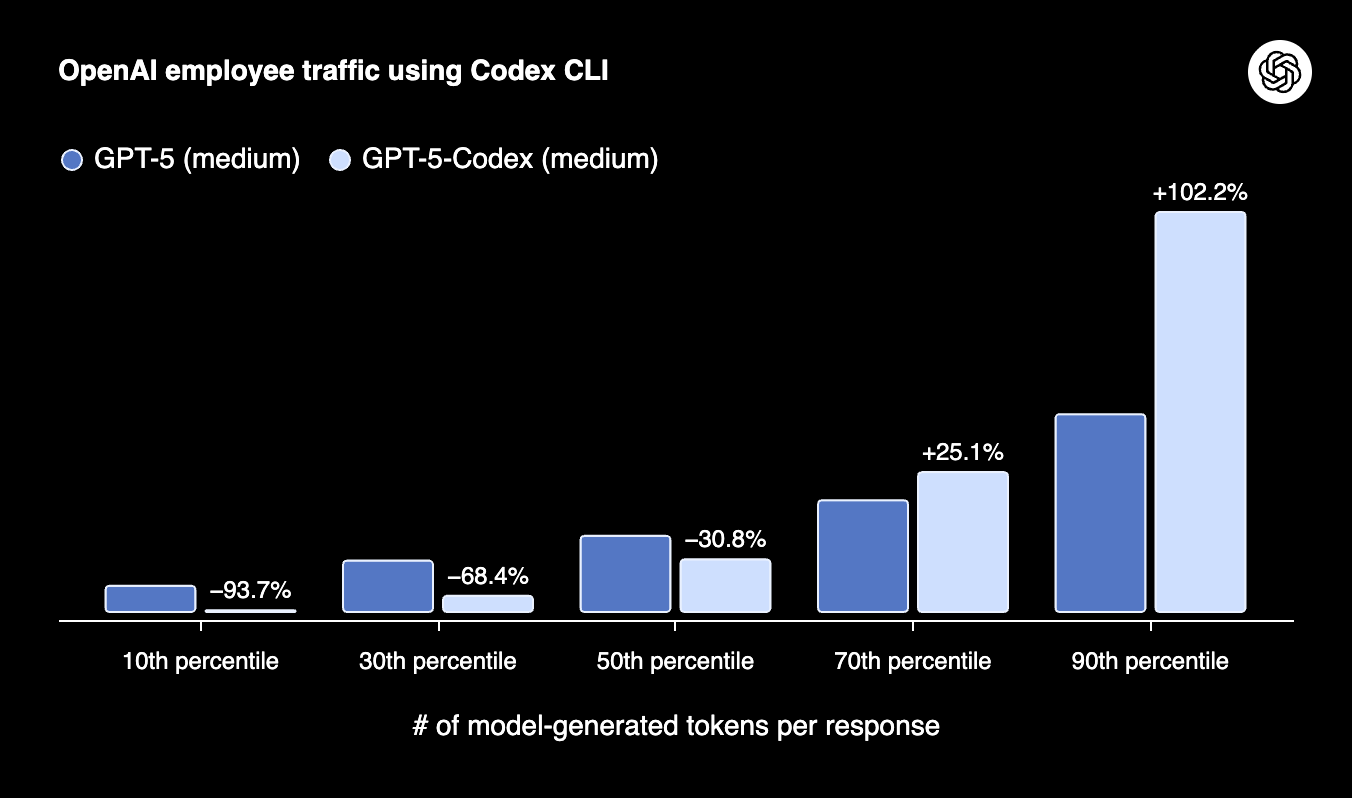
Codex’s impressive new capabilities have positioned it to challenge the established order in a fiercely competitive market. Over the past year, dominance in AI coding tools has shifted rapidly from GitHub Copilot to the AI-native IDE, Cursor, and most recently to Anthropic’s Claude Code. With Google’s coding agent Jules, Cognition’s Devin, and a new fast coding model from xAI also in the mix, OpenAI’s latest move with Codex is a direct and consequential challenge to the current leaders. Many open weight models are also now performing well for coding, and GLM 4.5 has been a very affordable recent favorite. We do, however, expect Anthropic to fight back with a Claude 4.5 update or Claude Code upgrade soon!
Why should you care?
True breakout adoption in AI has often been elusive, yet the coding vertical is a notable exception. Both Claude Code and Cursor surpassed a $500M revenue run rate this year in record time, while other coding-focused AI applications, such as Lovable, reached $100M ARR in just eight months.
Why has AI for coding become the first true success story, a rare area where a majority of workers now use AI tools, while 95% of other enterprise AI pilots overall stall? While I see five key foundational mistakes that cause AI project failure overall (more about that next week!) — the answer in this case is simple: the developers building these AI for code systems are also the end-users. This tight, intuitive feedback loop, where the creator deeply understands the user’s pain points, workflows, and quality standards, is a luxury developers don’t have when building systems for other industries. They can “vibe test” a new feature and instantly know if it works, without needing to commission complex evaluations at every design step and iteration.
This is the critical lesson for every other vertical. An AI product that achieves breakout adoption must be designed, or at least co-designed, by someone with deep domain expertise in the target market. Too many enterprise AI projects fail because they are led by the wrong profile; a traditional software veteran or machine learning scientist CTO without deep experience of the LLM stack often massively underweights the other skills and team members required for success. For LLM-first systems, the center of gravity is very different from traditional software. Product design and AI system design merge into a single discipline. The “brain” — the prompts, tools, retrieval strategies, evaluations, and guardrails — is the product.
You cannot hope to create a system that outperforms a foundation model’s internet knowledge on a specific task if you don’t inject any unique, human domain experience into its design. This goes deeper than simply buying labeled data from services like Scale AI or Surge; such integration is often too superficial to create a true moat. This is what is happening naturally in the AI-for-code space, but it’s the missing ingredient in AI pilots that fail to deliver results.
This is why the battle for the AI native IDE or coding agent is so intense and the resulting tools so powerful. For the AI labs, the stakes are even higher; many consider coding to be fundamental to the broader AI race. The lab that achieves superhuman coding capability first could use that to accelerate its own research, potentially creating a runaway leader in the quest for AGI. The coding wars are just getting started, and for developers, the spoils are getting richer with every battle.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI and Oracle Sign $300 Billion Computing Deal
OpenAI has signed a contract worth $300 billion over five years with Oracle to secure roughly 4.5 gigawatts of computing capacity. While OpenAI has long relied on Microsoft Azure, the deal signals a strategic diversification of its compute infrastructure. [WSJ]
2. Microsoft To Lessen Reliance on OpenAI by Buying AI From Rival Anthropic
Microsoft will integrate Anthropic’s models into Word, Excel, Outlook, and PowerPoint, according to The Information. The move reduces Microsoft’s sole reliance on OpenAI for its productivity suite. It comes as the company negotiates a new agreement with OpenAI following its planned restructuring, though reports suggest this is not intended as a negotiating tactic.
3. Alibaba Releases Qwen-Next: A Hyper-Optimal Model
Alibaba’s Qwen team has unveiled Qwen3-Next, a new architecture optimized for ultra-long context and large-parameter efficiency. It combines hybrid attention with a sparse MoE design, activating only 3B of 80B parameters during inference. Two versions are available: Qwen3-Next-80B-A3B-Instruct, which performs near the 235B flagship and excels at tasks up to 256k tokens, and Qwen3-Next-80B-A3B-Thinking, tuned for complex reasoning and outperforming mid-tier Qwen3 models as well as Gemini-2.5-Flash-Thinking.
4. MCP Team Launches the Preview Version of the ‘MCP Registry’
The MCP Registry has launched in preview, providing a global directory where companies such as GitHub and Atlassian can publish MCP servers. Enterprises can also run private sub-registries while inheriting the upstream API specification for interoperability. Managed by the MCP Registry working group, it is released under a permissive open-source license.
5. Google AI Releases VaultGemma: The Largest Differentially Private Model
Google AI Research and DeepMind introduced VaultGemma 1B, the largest open-weight LLM trained entirely with differential privacy (DP). Unlike approaches that apply DP only in fine-tuning, VaultGemma enforces full private pre-training. Trained on the same 13T-token dataset as Gemma 2, it has 1 billion parameters and a reduced sequence length of 1,024 tokens, which lowers compute costs and enables larger batch sizes under DP constraints.
Five 5-minute reads/videos to keep you learning
1. From Zero to Hero: Building Your First AI Agent with LangGraph
This guide walks through building production-ready AI agents with LangGraph, informed by lessons from early project failures. It distinguishes agents from traditional models through their ability to use memory, make decisions, and coordinate tools for multi-step problem solving. A tutorial demonstrates how to build an article analyzer that classifies content, extracts entities, summarizes, and generates insights. The piece also addresses debugging strategies, common pitfalls, and performance optimization to help developers create reliable applications.
2. From Prompts to Context: The AI Revolution That’s Changing Everything
This article contrasts prompt engineering with the more advanced practice of context engineering. By constructing dynamic environments around the model, context engineering improves accuracy, personalization, and reliability. It shifts AI from a clever chatbot into a production-ready tool capable of handling real business tasks.
3. Temporal Difference Learning: The Most Powerful RL Solution
This article explores Temporal Difference (TD) Learning, a reinforcement learning method that combines the strengths of Dynamic Programming and Monte Carlo. TD updates value estimates through bootstrapping while learning from experience. The piece also introduces SARSA, an on-policy TD control algorithm that updates Q-values using the sequence (S, A, R, S′, A′).
4. Control is All You Need: Why Most AI Systems & Agents Fail in the Real World, and How to Fix It
Arguing against the trend of fully autonomous agents, this article stresses that reliability requires grounding AI in established software engineering principles. Instead of inventing new paradigms, it recommends treating AI as a non-deterministic function call with strict input/output schemas. This ensures predictable behavior, structured results, and safer integration into production systems.
5. Defeating Nondeterminism in LLM Inference
This post examines why inference results can differ even at temperature 0. While floating-point precision and concurrency are often blamed, the real issue is batch dependence: kernels that aren’t batch-invariant cause reduction orders to vary depending on simultaneous requests or token counts. The article highlights how this undermines reproducibility in LLM inference.
Repositories & Tools
1. GenKit is an open-source framework for building full-stack AI-powered applications, built and used in production by Google’s Firebase.
2. Memori is an open-source memory engine for LLMs, AI agents & multi-agent systems.
3. MLX LM is a Python package for generating text and fine-tuning LLMs on Apple silicon with MLX.
4. Paper2Agent is a multi-agent AI system that automatically transforms research papers into interactive AI agents.
Top Papers of The Week
1. A Survey of Reinforcement Learning for Large Reasoning Models
The survey examines recent advancements in using Reinforcement Learning (RL) to enhance reasoning in large language models, focusing on complex tasks such as mathematics and coding. With challenges in scaling, especially following DeepSeek-R1’s release, the paper explores foundational components, core problems, and strategies to drive RL’s scalability towards Artificial SuperIntelligence (ASI) in reasoning models.
2. Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
This paper introduces SAPO, a decentralized RL post-training algorithm that optimizes language models by enabling compute nodes to share rollouts asynchronously. It avoids common RL bottlenecks and achieves cumulative reward gains of up to 94% in experiments. Tests with diverse hardware and models from the Gensyn community demonstrate SAPO’s scalability without assumptions about latency or hardware uniformity.
3. Why Language Models Hallucinate
This paper argues that language models hallucinate because training and evaluation prioritize guessing over expressing uncertainty, resulting in errors similar to those in failed binary classification. Such models, optimized to excel in tests, benefit from guessing, which boosts test results. Addressing this issue requires revising current benchmarks to steer AI development towards more reliable systems.
4. K2-Think: A Parameter-Efficient Reasoning System
K2 Think is a 32B-parameter open reasoning system for advanced AI reasoning. It pairs long-chain-of-thought supervised fine-tuning with reinforcement learning from verifiable rewards, agentic planning, test-time scaling, and inference optimizations (speculative decoding and wafer-scale hardware). K2 Think is built by post-training an open-weight Qwen2.5–32B base model and adding a lightweight test-time compute scaffold.
5. Universal Deep Research: Bring Your Own Model and Strategy
This paper introduces Universal Deep Research (UDR), an open-source system (in preview) that decouples strategy from model. It allows users to design, edit, and run their own deep research workflows without retraining or fine-tuning any LLM. UDR takes two inputs: the research strategy (a step-by-step workflow) and the research prompt (including the topic and output requirements). This separation of orchestration vs. reasoning improves efficiency and reduces GPU cost.
Quick Links
1. Baidu AI Research team released ERNIE-4.5–21B-A3B-Thinking, a new reasoning-focused LLM designed around efficiency, long-context reasoning, and tool integration. It is built on a Mixture-of-Experts backbone. Instead of activating all 21B parameters, the router selects a subset of experts, resulting in 3B active parameters per token.
2. California bill SB 243 passed both the State Assembly and Senate with bipartisan support and now heads to Governor Gavin Newsom’s desk. The bill specifically aims to prevent companion chatbots, which the legislation defines as AI systems that provide adaptive, human-like responses and are capable of meeting a user’s social needs from engaging in conversations around suicidal ideation, self-harm, or sexually explicit content.
Who’s Hiring in AI
Junior AI Engineer (LLM Development and Technical Writing) @Towards AI Inc (Remote)
Senior AI Server Engineer — BigBox @Meta (Multiple US Locations)
AI Scientist @Metropolitan Commercial Bank (New York, USA)
A.I. Engineering Intern (Colombia) @Sezzle (Colombia/Remote)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
This talk about AI in coding was really interesting to me. It makes me think of my own experiences with programming. It's interesting to observe how many success stories come from AI making hard things easier https://geometryonline.io
Why are there so many different LLM versions existing at the same time? Example: today was just released “codex” variant, which improved the code generation. Why has not that specific improvement merged into the current “root” version of that same tool?