
TAI #169: OpenAI's New Paper Sparks Discussion on Why AI Hallucinates
Also, Google's Veo 3 goes mainstream, Qwen's new frontier model, and OpenAI's AI-native film.




What happened this week in AI by Louie
The rapid pace of AI model releases continued this week, with Google in particular pushing new capabilities into the hands of developers. Its text-to-video model, Veo 3, is now generally available via API at a surprisingly affordable price — just $0.40 per second for the standard version and $0.15 for Veo 3 Fast, a significant reduction from previous pricing. With new support for 9:16 vertical and 1080p output, high-quality video generation for marketing materials and creative visualization is now something that can be automated and tested at scale. This comes as OpenAI is reportedly aiming to produce “Critterz,” a fully AI-generated animated film, in just nine months on a budget of less than $30 million, a fraction of the time and cost of a traditional animated feature. Away from video, Google also shipped EmbeddingGemma, a highly efficient 308M-parameter open embedding model that is best-in-class on the MTEB leaderboard and is designed for on-device RAG and semantic search.
Meanwhile, the competitive pressure at the frontier of closed models continues to intensify. Alibaba released Qwen3-Max-Preview, a new premium model with over 1 trillion parameters, available for now only via API (despite China’s general focus on open weights). Early benchmarks and user feedback suggest it is highly competitive, reinforcing the trend that state-of-the-art AI is no longer the exclusive domain of a handful of US AI labs.
While the pace of new model releases is breathtaking, the underlying challenge of making them consistently trustworthy remains. This week, OpenAI offered a rare and insightful look under the hood at the biggest obstacle to reliability: hallucinations. In a new paper titled “Why Language Models Hallucinate,” researchers provided a crisp statistical account of why models generate plausible but incorrect statements. The paper reduces text generation to a binary classification task called “Is-It-Valid” (IIV). It shows that a model’s generative error rate is lower-bounded by roughly twice its IIV misclassification rate. In plain English, if a model cannot reliably separate valid completions from invalid ones, it will inevitably generate errors. A key insight is the “singleton rate”: facts that appear only once in the training data, like an obscure birthday, are disproportionately vulnerable. The paper proves that for such arbitrary facts, the hallucination rate is at least the fraction of singletons in the data.
The paper argues that these statistical pressures are exacerbated by the way models are evaluated. An audit of mainstream benchmarks, such as GPQA and MMLU-Pro, reveals that they give no credit for uncertainty; an “I don’t know” response scores zero, the same as a wrong answer. Faced with these incentives, the provably optimal strategy for the model is never to abstain, but always to guess. Post-training techniques like RLHF can even worsen this, making models less calibrated and more confidently wrong. While the paper was praised for its formal framework, it also drew pushback. Some critics viewed it as a statement of the obvious: that, of course, models will guess if you penalize them for saying “I don’t know.”
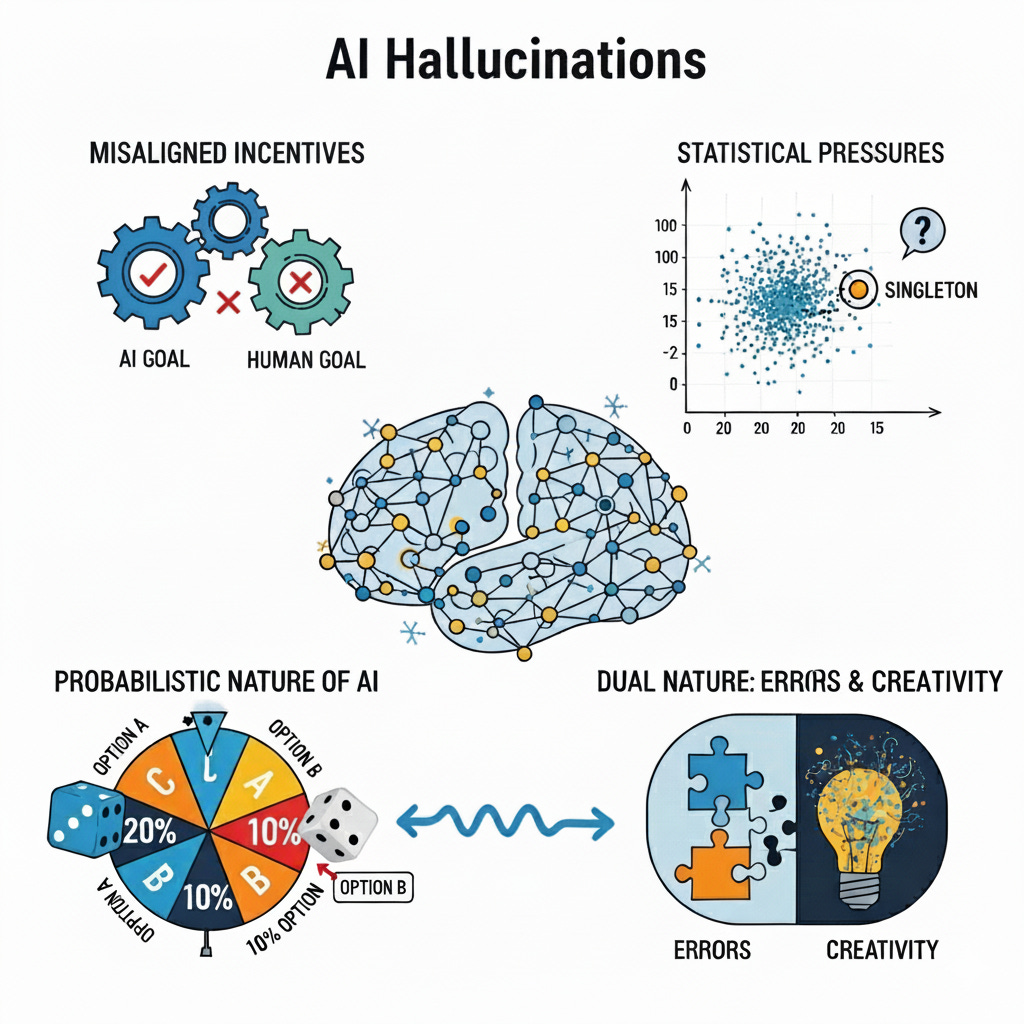
Why should you care?
The most important takeaway from OpenAI’s paper is that hallucinations are not a mysterious bug, but a predictable outcome of misaligned incentives. This is a compelling explanation, but it’s not the only one. Some argue that hallucinations are a more fundamental feature of the underlying architecture, an unavoidable consequence of probabilistic models that stitch patterns together without proper understanding or grounding in reality. There is also a compelling counterargument that the very mechanism that causes hallucinations, the confident blending of learned patterns, is also the source of their creativity. Eradicating every last hallucination might come at the cost of the serendipitous, novel outputs that make these models so powerful.
Regardless of the root cause, the practical implications for builders are the same: we cannot simply wait for the labs to release a perfectly “cured” model. The paper is a clear signal that building robust scaffolding around these models is not a temporary hack, but a core and necessary part of the job. This is why the work of building sophisticated systems with Retrieval-Augmented Generation (RAG), agentic workflows, and verification steps is so critical. However, these techniques are not a panacea. When retrieval fails or a task is intrinsically difficult, a model trained with binary scoring is still incentivized to bluff. The ultimate solution requires pairing smart system design with evaluation methods that reward a model for knowing what it doesn’t know.
Fortunately, the models themselves are also getting better. We’ve found that GPT-5 thinking has already made a significant leap forward in reducing hallucinations, and we expect to see similar progress from all the major labs. However, even as the baseline improves, the need for skilled developers who can design and implement these corrective systems will continue to grow.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Alibaba Just Released Qwen-Max-Preview
Alibaba’s Qwen team has introduced Qwen3-Max-Preview (Instruct), its largest model to date, with over one trillion parameters. It supports a 262k-token context window with caching, enabling extended document and session processing. Benchmarks show strong results, outperforming Qwen3–235B-A22B-2507 and competing with Claude Opus 4, Kimi K2, and DeepSeek-V3.1 on SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2, and LiveBench. The model is accessible via Qwen Chat, Alibaba Cloud API, OpenRouter, and Hugging Face’s AnyCoder tool.
2. Anthropic to Pay $1.5 Billion to Authors in Landmark AI Settlement
Anthropic has agreed to pay at least $1.5 billion plus interest to authors as part of a class-action settlement. Payments are expected to average about $3,000 per book or work, with roughly 500,000 works eligible. The settlement, which remains subject to court approval, will be reviewed at a hearing on September 8. The final payout may be higher depending on the number of claims.
3. Google AI Releases EmbeddingGemma
Google has launched EmbeddingGemma, a lightweight text embedding model optimized for on-device AI. At 308M parameters, it is designed for mobile and offline use. EmbeddingGemma applies Matryoshka Representation Learning (MRL), allowing embeddings to be truncated from 768 to 512, 256, or even 128 dimensions with minimal loss in quality. Trained across 100+ languages, it ranks highest on the Massive Text Embedding Benchmark (MTEB) among models under 500M parameters.
4. Google Finally Details Gemini Usage Limits
Google has clarified usage limits for Gemini Apps. Free accounts can access up to five prompts daily with Gemini 2.5 Pro, along with five Deep Research reports and 100 generated images. Paid tiers expand limits to 100 prompts with AI Pro and 500 prompts with AI Ultra, providing users with more flexibility based on their subscription level.
5. Mistral Released a New Set of MCP Connectors
Mistral has released 20+ MCP-powered connectors in its Le Chat platform, enabling users to search, summarize, and take actions across business-critical tools. The directory spans data, productivity, development, automation, commerce, and custom integrations. Users can also add their own connectors to extend coverage. The system runs in-browser, on mobile, or can be deployed on-premises or in the cloud.
6. OpenAI Announces AI-Powered Hiring Platform To Take On LinkedIn
OpenAI announced its upcoming OpenAI Jobs Platform, an AI-driven job matching service designed to connect businesses with AI-skilled talent. Set to launch in mid-2026, the platform utilizes AI to intelligently align employer needs with candidate strengths, including support for local businesses and government agencies. OpenAI will also roll out a certification program embedded in ChatGPT’s Study Mode, offering AI fluency credentials, from basic tool use to advanced prompt engineering, targeting 10 million Americans by 2030.
Google’s text-to-video model, Veo 3, has moved from a research preview to being generally available via API, making it a production-ready tool for developers. This release significantly lowers the cost of high-quality AI video, with the standard Veo 3 model dropping from $0.75 to $0.40 per second and the speed-optimized Veo 3 Fast model falling from $0.40 to just $0.15 per second. Combined with new support for vertical formats and 1080p HD output, these price cuts make AI-generated video an increasingly practical and affordable tool for a wide range of applications, from marketing content to creative pre-visualization.
Four 5-minute reads/videos to keep you learning
1. Test MCP Servers Across Leading LLMs — and Even Try “gpt-oss” + MCPs for Free
This article introduces a command-line tool for testing and comparing LLMs with MCP servers. Using a single JSON5 configuration file, users can evaluate performance, cost, and speed across providers like OpenAI, Google, and Anthropic, as well as open-source options such as gpt-oss. The tool makes it easy to run identical queries across multiple backends, offering a practical framework for side-by-side benchmarking.
2. Build an AI PDF Search Engine in a Weekend (Python, FAISS, RAG — Full Code)
This guide walks through building a local AI-powered PDF search engine with a full Python implementation. It covers PDF ingestion, context-aware text chunking, and embedding creation with sentence-transformers, indexed in FAISS with metadata managed by SQLite. The system retrieves answers using a RAG pipeline, combining an optional LLM for synthesis with a built-in extractive fallback. Complete code, including a Gradio web interface, is provided for hands-on experimentation.
In this three-part series, the author examines why many AI systems fail to scale from pilot to production, pointing to systemic bias as a central factor. Biases are grouped into three categories: persistence over time (survivorship bias), flawed methodology (selection bias), and human sources (algorithmic bias). Using a logistics case study, the series shows how these issues derail implementations. Recommended mitigation strategies include rigorous data governance, out-of-sample testing, fairness audits, and explainable AI practices to ensure systems deliver lasting value.
4. I Built a Local Clinical AI Agent from Scratch — Here’s How
This piece details the creation of a local clinical agent designed to enhance unstructured clinical notes. A local LLM is paired with three custom tools: an abnormal lab detector, a follow-up gap checker, and a diagnosis normalizer leveraging the Unified Medical Language System (UMLS). Together, these components generate discharge safety reports that flag risks such as out-of-range lab values or delayed follow-ups. The article highlights the role of normalization and precise prompt engineering in developing reliable support systems for healthcare.
Repositories & Tools
1. KiloCode is an open-source AI coding assistant for planning, building, and fixing code.
Top Papers of The Week
1. Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth
This paper introduces Drivelology, a linguistic phenomenon defined by syntactically coherent but pragmatically complex utterances. A benchmark of over 1,200 examples shows that current LLMs consistently struggle with this type of text, often misinterpreting it. The findings highlight a gap in pragmatic understanding and challenge the assumption that fluency equates to comprehension. The dataset and code are publicly released for further research.
This survey explores recent advances in LLM reasoning, with a focus on inference scaling, learning-to-reason, and integration into agentic systems. It discusses techniques at both the input level (prompt construction) and output level (candidate refinement), as well as algorithms and workflows, such as OpenAI Deep Research and Manus Agent, that aim to improve reasoning quality.
3. REFRAG: Rethinking RAG-based Decoding
The paper introduces REFRAG (REpresentation For RAG), a decoding framework that improves Retrieval-Augmented Generation efficiency. REFRAG extends LLM context windows by 16× and accelerates time-to-first-token (TTFT) by up to 30.85× without accuracy loss. It achieves this by compressing retrieved passages into fixed-size embeddings (e.g., 16 tokens), enabling the decoder to process compact representations rather than thousands of raw tokens.
4. Towards a Unified View of Large Language Model Post-Training
This paper proposes the Unified Policy Gradient Estimator (UPGE), showing that Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) can be expressed as instances of a single gradient formulation. Building on this framework, the authors introduce Hybrid Post-Training (HPT), which dynamically balances SFT for exploitation with RL for exploration. HPT demonstrates consistent improvements over strong baselines on multiple mathematical reasoning benchmarks.
5. The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
This survey examines the role of Agentic Reinforcement Learning (RL) in transforming LLMs from passive generators into autonomous agents. It outlines a taxonomy of agentic capabilities such as planning and perception, framed within temporally extended POMDPs. The paper compiles key open-source resources and highlights research directions for developing scalable agentic systems.
Quick Links
1. Switzerland launched an open-source model called Apertus as an alternative to proprietary models like OpenAI’s ChatGPT or Anthropic’s Claude. The model’s source code, training data, model weights, and detailed development process are available on HuggingFace. The model was trained on over 1,800 languages and is available in two sizes, with either 8 billion or 70 billion parameters.
2. OpenAI is venturing into Hollywood with Critterz, an animated feature fully powered by AI that’s set for a global theatrical release in 2026 following a premiere at Cannes. Produced in under nine months with a budget below $30 million, the film leverages OpenAI’s GPT-5 and aims to prove AI’s creative and commercial viability in film production.
Who’s Hiring in AI
Online Data Research @TELUS Digital (Remote/USA)
Technical Program Manager, Cloud AI @Google (Sunnyvale, CA, USA)
AI & Machine Learning Engineer @ABBVIE (Rungis, France)
Senior Python Software Developer @S&P Global (Hyderabad, India)
Graduate AI Engineer @Renesas (Columbia, MO, USA)
Intermediate Backend Engineer (Python), AI Framework @GitLab (Remote/Canada/Europe)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.