
TAI #167: US and China's Open-Weight Divergence; Do You Really Need Open-Weight LLMs?
Also, DeepSeek-V3.1, Grok 2.5 open-sourced, Cohere Command A reasoning, and more!




What happened this week in AI by Louie
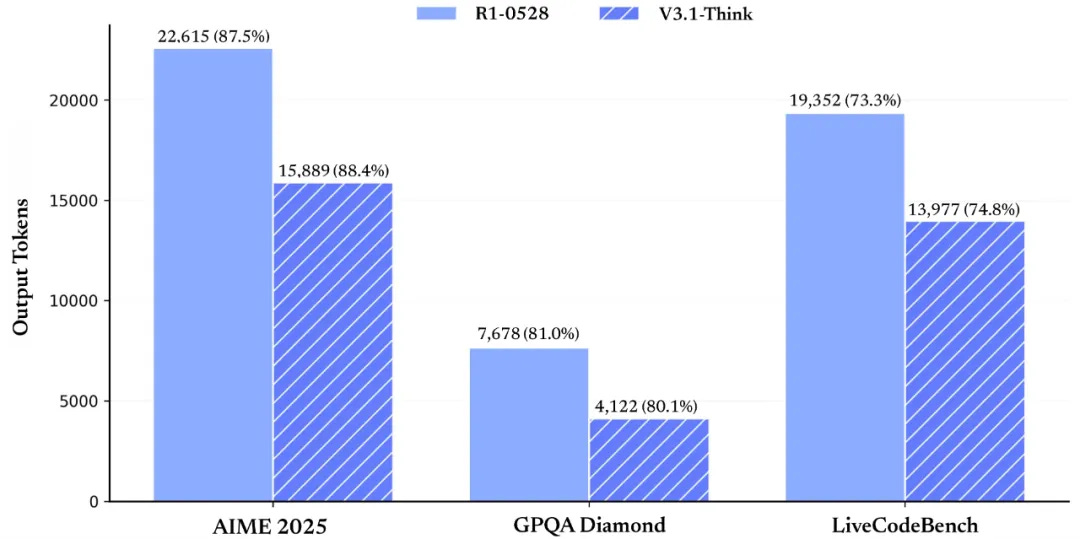
The open-weight LLM ecosystem saw another major release this week with DeepSeek-V3.1, an upgrade introducing a hybrid “Think/Non-Think” inference mode for better control over reasoning and latency. It also comes with stronger agentic and tool-use capabilities, reinforcing the trend of open models pushing aggressively into more complex, multi-step tasks. It maintains its 671B‑parameter Mixture of Experts architecture (37B active tokens). Similar to OpenAI’s progress with GPT-5 thinking over o3, a key V3.1 improvement is its token efficiency compared to R1. This release is part of a steady drumbeat from Chinese AI labs in open-weights. It follows hot on the heels of Alibaba’s Qwen 3 family (with MoE models up to 235B parameters), Moonshot AI’s huge Kimi K2 MoE (1-trillion-parameter, 32Bn active), also built for agentic workflow, and Zhipu AI’s strong GLM-4.5 (355bn parameters, 32bn active).
The trend is starkly illustrated by benchmarks and community leaderboards where open-weight rankings are now led by the likes of DeepSeek, Alibaba, Kimi, and Zhipu AI. In fact, in Design Arena, which evaluates models on complex design and reasoning tasks, the entire top 15 open-weight models all come from China. This dominance at the frontier of open-weight AI highlights a divergence between the world’s two major tech ecosystems. Chinese labs are routinely releasing their frontier-scale models with permissive licenses, often embracing large, sparse MoE architectures that trade inference complexity for greater capability.
In the US, the open-weight strategy from leading labs like OpenAI and Google looks very different. These AI labs only release the weights of models that are far behind the frontier. OpenAI recently released its first open-weight models since GPT‑2; its GPT-OSS 120B (MoE) & 20B models. It frames GPT-oss as open weights to run on your infrastructure, explicitly “coupled with the models available in our API,” allowing teams to dial in performance, cost, and latency per step. Deepmind’s Gemma 3 is marketed as “lightweight… designed to run on devices.” That’s the intended business model from these labs: offer small, efficient local models for use cases where privacy and latency are key; encourage escalation to frontier LLMs via API when the task complexity warrants. These recent releases are significantly smaller than the leading Chinese models and are designed to be easier to run on-premise or even on-device. They are explicitly positioned not as rivals to their frontier closed models, but as complements. xAI also contributed to the trend by finally releasing the model weights for Grok-2.5. However, the model now lags significantly behind the capabilities of Grok-4 and open models from China.
Meta’s Llama 4 Maverick MoE model (400Bn parameters with 17bn active) remains an exception in the US, as this is the company’s best model and is also large and difficult to inference. However, META’s failure to compete with Chinese models with Llama 4 has driven a huge shake-up of its team and strategy, and its future commitment to open weights is now unclear.
This all leaves many enterprises in a fix. For custom AI products to succeed and deliver real value, particularly in agentic workflows, raw intelligence is often the most critical factor. The productivity gains from a highly capable model that can reliably assist or automate complex human work far outweigh its inference or API costs. Yet, many companies find themselves trying to build with open-weight models that are a step or two behind the frontier in capability, context length, and reliability. This leads them down a rabbit hole of investment in fine-tuning, distillation, complex harnessing, and complex inference setups, trying to coax frontier performance out of a sub-frontier model. To add insult to injury, their overall inference costs are often much higher than the APIs due to the low utilization of their private GPUs compared to a major LLM API provider that can batch hundreds of requests per second 24/7. This is before even considering the geopolitical discomfort some Western companies may have using models trained in line with the Chinese government’s viewpoints.
Why should you care?
The current state of the open-weight ecosystem has created a genuine dilemma for enterprises, and I believe the default assumption that they must use open-weight models for security reasons has become a primary cause of failure for custom LLM developments. Companies spend huge development effort only to end up with a system that is still less capable than what is easily available in ChatGPT or Gemini.
This hesitancy to use the most powerful closed models is often based on assumptions that conflate the data policies of free consumer-tier chatbot plans (which can train on user data) with secure enterprise offerings. In reality, highly regulated companies like Moderna have all their employees using ChatGPT Enterprise, and the US government runs OpenAI models on Azure for tasks requiring national security clearance. A real problem is a low awareness of the custom enterprise security tiers available from Azure, Google Vertex, OpenAI, Cohere, and others, which offer dedicated endpoints, regional data hosting, and robust contractual privacy guarantees. However, these issues can permeate through the supply chain, and often customers also demand that their data is only used with local AI deployments.
This all forces companies down the open-weight path, where they face a difficult choice. The smaller, US-developed models are easier to run but often lack the raw intelligence needed for high-value agentic tasks. The more capable Chinese models, while closer to the frontier, are typically massive MoEs that are too difficult and expensive to serve in-house. Serving large MoEs requires expert parallelism and high‑bandwidth all‑to‑all routing. Kimi K2’s own docs recommend 16‑GPU H200/H20 clusters for 128K context. Hardware isn’t cheap: an 8× H200 HGX node often retails north of $400k.
For many, a hybrid approach is the most pragmatic path forward. This involves designing systems where less sensitive information and public data can be processed by frontier-intelligence LLMs via secure APIs, while truly private customer data is handled by smaller, local models or on isolated cloud endpoints with custom enterprise privacy guarantees from the model providers.
Choosing the right tool depends entirely on the use case:
Make sure to carefully consider what dedicated endpoints and security guarantees AI cloud providers can offer for their closed-source models and whether these truly can meet your customer and regulatory requirements.
If you need “frontier‑ish” open weights: start with Qwen3‑235B‑A22B (or Qwen3‑30B‑A3B if you need a smaller MoE) or DeepSeek‑V3.1. Consider Kimi K2 if your workloads are agent‑heavy and you can meet the 16‑GPU serving floor.
If you optimize for latency/privacy: Use gpt‑oss‑20B/120B for targeted reasoning and Gemma 3 for parsing and general chat usage. These are purpose‑built to run locally or on a single 80 GB GPU / device‑class hardware. Escalate to hosted frontier APIs for higher-level reasoning and less sensitive parts of your workflow. This design keeps costs predictable and minimizes infrastructure risk during early product cycles.
Building such a system is more complex, but it’s a far better strategy than being hamstrung by a blanket refusal to use the best tools for the job. Smaller open models still have a crucial role to play, but often they are best used for optimizing specific parts of a pipeline, not as the sole system intelligence. Many LLM projects will still fail to reach the reliability and capability needed for success without having the frontier models in the mix somewhere.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. DeepSeek Releases DeepSeek-V3.1
DeepSeek has launched DeepSeek-V3.1, its latest flagship language model. Building on the V3 architecture, it delivers major gains in reasoning, tool use, and coding performance. The model has 671B total parameters, with 37B active per token, and a 128k context window. It supports both “thinking” and “non-thinking” generation, switchable via chat templates. All model weights and code are available on Hugging Face and ModelScope under the MIT license.
2. Cohere Introduced Command A Reasoning
Cohere unveiled Command A Reasoning, a model designed for complex enterprise reasoning tasks. It runs on a single H100 or A100 GPU with a 128k context window, or scales up to 256k across multiple GPUs. Enterprises can also set token budgets to manage compute and costs. Released as a research model with open weights under a CC-BY-NC-4.0 license, Command A Reasoning reportedly outperforms gpt-oss-120b, DeepSeek-R1 0528, and Mistral Magistral Medium on benchmarks.
3. Anthropic Is Bundling Claude Code Into Claude for Enterprise
Anthropic is integrating Claude Code into its enterprise suite. Previously limited to individual accounts, the command-line coding tool can now be purchased as part of Claude for Enterprise. The move strengthens Anthropic’s position against enterprise-ready coding tools from Google and GitHub, which launched with corporate integrations from the outset.
4. xAI Has Open-Sourced Grok 2.5
Elon Musk’s xAI has open-sourced model weights used in Grok 2.5 on Hugging Face. Musk also confirmed plans to release Grok 3 as open source in about six months. AI engineer Tim Kellogg noted the Grok license is “custom with some anti-competitive terms.”
5. Elon Musk Reached Out to Mark Zuckerberg To Join His $97.4 Billion Bid for OpenAI
Court filings reveal Musk approached Mark Zuckerberg about joining his $97.4B bid for OpenAI, asking the Meta CEO to discuss potential financing arrangements before sending his letter of intent. Neither Zuckerberg nor Meta signed on.
6. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1
NVIDIA announced the Nemotron Nano 2 family of hybrid Mamba-Transformer reasoning models, alongside the Nemotron-Pretraining-Dataset-v1, which contains 6.6T tokens spanning web data, math, code, supervised fine-tuning, and multilingual Q&A. The release includes: Nemotron-Nano-9B-v2: aligned and pruned reasoning model, Nemotron-Nano-9B-v2-Base: pruned base model, and Nemotron-Nano-12B-v2-Base: base model prior to pruning or alignment.
7. OpenAI and Retro Biosciences Use Custom LLM for Biological Breakthrough
OpenAI and Retro Biosciences report a major advance in cellular reprogramming using a custom GPT-4b micro model. The system redesigned Yamanaka factors, genes used in cell rejuvenation, boosting reprogramming efficiency by 50x compared to prior methods. The model generated diverse, high-hit-rate variants that outperformed human-designed baselines, with validations confirmed across months of testing. Researchers also observed enhanced DNA damage repair, pointing to potential applications in rejuvenation. Built on GPT-4o architecture but trained on biology-specific data, the work highlights how domain-adapted LLMs can accelerate drug discovery and life sciences research.
Five 5-minute reads/videos to keep you learning
1. Fine-Tuning LLMs: From Zero to Hero with Python & Ollama
This step-by-step guide walks through fine-tuning a model using Python, Unsloth for faster training, and the Phi-3 Mini model on Google Colab. The workflow is illustrated with a practical example of extracting JSON from HTML. It covers dataset creation, applying LoRA for efficiency, and running the training process — making the case for lightweight, accessible fine-tuning methods.
2. Turn Any Text into Beautiful Interactive Maps: The Magic of AI-Powered Knowledge Graphs
This article introduces AI-Knowledge-Graph, an open-source tool that transforms text documents into interactive maps. Using language models, it processes input through text chunking, knowledge extraction, entity standardization, and relationship inference to reveal hidden connections. The piece also includes a guide for local installation and setup, showing how this approach can make complex relationships in documents more transparent and actionable.
3. Here’s Which Google AI Developer Tool To Use for Each Situation
Google released a guide to help developers select the best AI tool for their needs. Instead of surveying every product, the guide focuses on practical recommendations tailored to specific goals and workplace contexts, offering a clear framework for decision-making.
4. Your Wish, Granted: Meet Your On-Demand SQL Agent!
This article details how to build a SQL agent that translates plain-language queries into executable SQL. The workflow uses LangChain, a Groq-powered LLM such as Llama, and helper functions to provide contextual accuracy. A security-focused prompt enforces read-only access, ensuring safe data retrieval. The resulting agent enables self-service queries, reducing bottlenecks and improving organizational efficiency.
5. Few-Shot Optimization at Scale in DSPy
This article explores DSPy’s few-shot optimization framework for building self-learning AI systems. It explains how algorithms like BootstrapFewShot and KNNFewShot automate the selection of examples, replacing manual curation with data-driven methods. It also describes advanced strategies such as multi-stage optimization and custom metric engineering, highlighting a case study where a customer support bot improved accuracy from 68% to 92%. The focus is on systematic engineering practices that enable models to adapt continuously with user feedback.
Repositories & Tools
1. M3 Agent is a novel multimodal agent framework equipped with long-term memory.
2. DeepCode is an open-source AI-powered coding platform designed to automate software development by orchestrating a suite of specialized agents.
3. Puck is a modular, open-source visual editor for React.js.
4. Jupyter Agent 2 allows you to run code and analyze data using a Jupyter notebook interface.
Top Papers of The Week
1. Retrieval-Augmented Reasoning with Lean Language Models
This report introduces a lightweight language model framework that combines retrieval-augmented generation (RAG) with reasoning to handle complex, domain-specific queries in secure or resource-constrained environments. By fine-tuning lean Qwen2.5-Instruct models on synthetic reasoning traces and summarised documents, the system achieves near-frontier performance while remaining deployable locally.
2. Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing
Avengers-Pro, a test-time routing framework, optimizes performance efficiency by dynamically assigning queries to suitable models. By integrating multiple LLMs like GPT-5-medium and Gemini-2.5-pro, it outperforms GPT-5-medium by 7% in accuracy and achieves significant cost reductions. This approach consistently hits the Pareto frontier, maximizing accuracy at minimal costs.
The paper introduces DeepConf, a lightweight test-time method that leverages token-level confidence signals to filter low-quality reasoning traces, improving both accuracy and efficiency in ensemble reasoning. On challenging benchmarks like AIME 2025, DeepConf achieves up to 99.9% accuracy while cutting token generation by as much as 84.7%, making it a practical solution for scalable reasoning.
4. ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
This paper introduces ComputerRL, a framework designed to empower agents with the ability to navigate and manipulate complex digital workspaces. This innovation addresses a core challenge in AI agent development: the disconnect between computer agents and human-designed graphical user interfaces (GUIs). By integrating programmatic API calls with direct GUI interactions, ComputerRL enables more efficient and versatile desktop operations, marking a significant step toward autonomous computer use agents.
5. Memp: Exploring Agent Procedural Memory
This paper introduces Memp, a framework designed to give agents a lifelong, adaptable procedural memory. Memp transforms past trajectories into both detailed step-level instructions and higher-level scripts, while offering strategies for memory construction, retrieval, and updating. Unlike static approaches, it continuously refines knowledge through addition, validation, reflection, and discarding, ensuring relevance and efficiency. Tested on ALFWorld and TravelPlanner, Memp consistently improved accuracy, reduced unnecessary exploration, and optimized token use.
Quick Links
1. Google Cloud recently unveiled five specialized AI agents designed to streamline developer workflows, including BigQuery Data Agent, Notebook Agent, Looker Code Assistant, Database Migration Agent, and GitHub Agent.
2. Meta is partnering with Midjourney to license the startup’s AI image and video generation technology. The Midjourney partnership could help Meta develop products that compete with industry-leading AI image and video models, such as OpenAI’s Sora, Black Forest Lab’s Flux, and Google’s Veo.
Who’s Hiring in AI
Online Data Research @TELUS International (Part Time/Remote)
Algorithm Engineer, LLM (Safety First) — AI Safety @Binance (Remote)
AI Adoption Analyst (early-career) @Lockheed Martin (Littleton, CO, USA)
AI Model Tester (Functional Testing) @NTT DATA North America (Chennai, India)
GENAI CCAS Application Developer @Leidos (Remote/ USA)
Enterprise Account Executive- Atlanta @Aisera (Remote/USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.