
TAI #165: GPT-5's Mixed Reception
Also, OpenAI's open weight GPT-Oss-120B and GPT-Oss-20B, Claude Opus 4.1, and Deepmind Genie 3.




What happened this week in AI by Louie
After months of intense hype and speculation, OpenAI finally released GPT-5, arguably the most anticipated AI model launch of the year. Perhaps, they set themselves up for a fall, and the model has had a mixed reception. The rollout itself was also messy. The new router system malfunctioned on launch day, and the initial user backlash led OpenAI to backtrack on removing legacy models and increase Plus tier usage limits for the “thinking” mode.
Rather than a singular, monolithic model, GPT-5 is a unified system: a smart, fast default model, a deeper reasoning model (“GPT-5 thinking”), and a real-time router that automatically decides which to use. In ChatGPT, this router is now the default model. Independent benchmarks from Artificial Analysis confirm that GPT-5 (High), the most capable configuration, sets a new state of the art, but not by the revolutionary margin many expected. It scores a 68 on their intelligence index, a hair above Grok 4 and OpenAI’s own o3 (both at 67). Via the API, the new four tiers of “reasoning effort” configurations — high, medium, low, and minimal — create a 23x difference in token usage and cost. While GPT-5 High is a new intelligence leader, GPT-5 Minimal performs at a similar level to GPT-4.1 but is far more token-efficient.
The highlights from GPT-5 for me are the dramatic reductions in hallucinations, major improvements in long-context reasoning, and a jump in real-world coding ability. However, we are yet to see if it is enough to challenge Anthropic’s coding API dominance. Another positive is progress on token efficiency; GPT-5’s improved SWE-bench scores, for instance, were achieved with fewer output tokens than o3. OpenAI also claims to have used new techniques to improve writing quality in the “thinking” version of the model; I am yet to unlock much evidence of this myself, but this would be another welcome change.
This release feels like an odd one out in the GPT lineage. A generational leap, like from GPT-3 to GPT-4, has historically involved a ~100x increase in training compute. GPT-5, however, is very unlikely to have used 100x more compute than GPT-4. It is likely also a smaller model than GPT-4.5, evidenced by its much lower API pricing. In many ways, the groundwork for GPT-5 was already laid by the o1 and o3 reasoning models, where capability gains emerged earlier than expected, perhaps making GPT-5 itself anticlimactic.
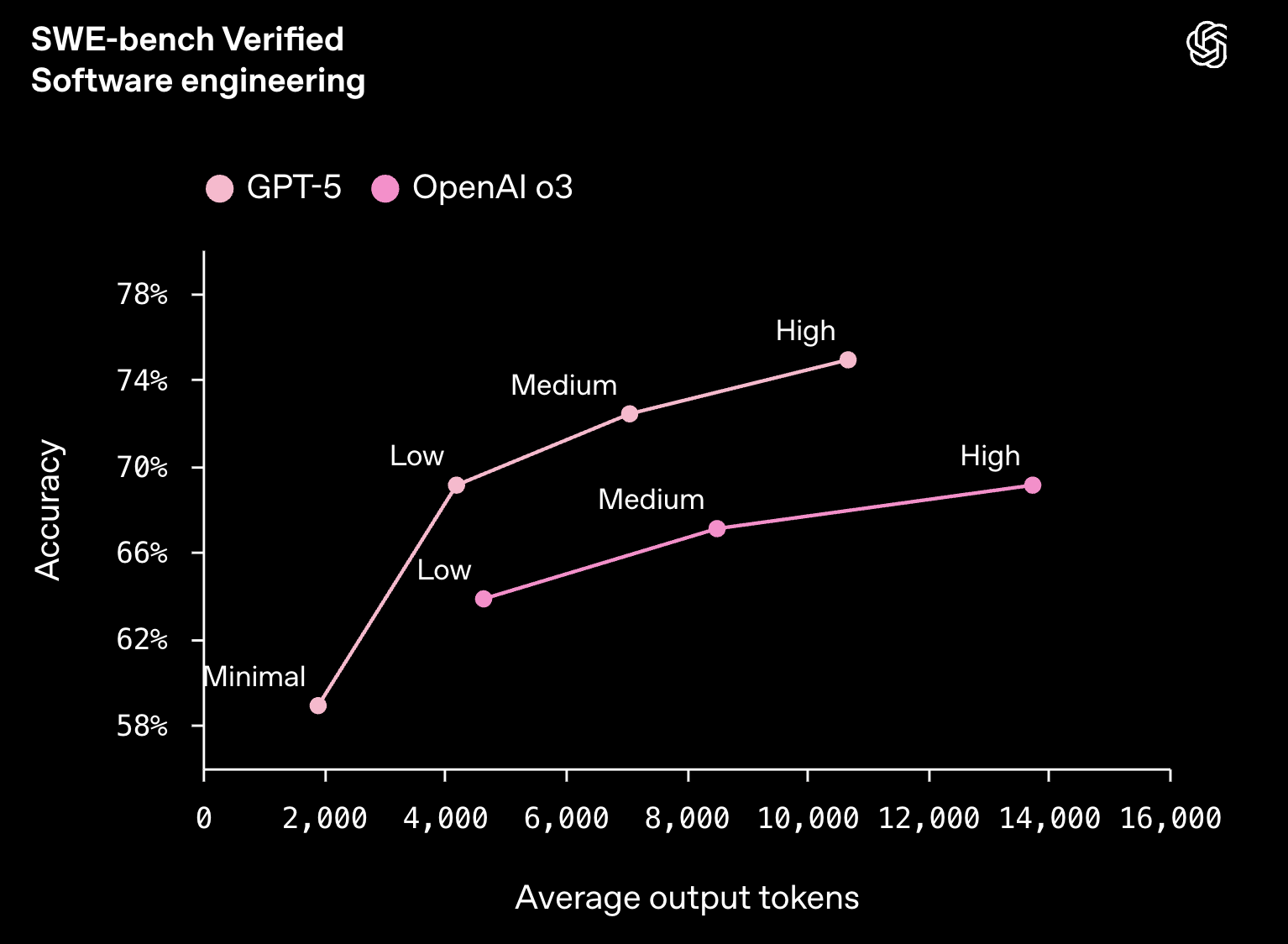
Benchmark highlights:
Hallucinations: On FactScore-style grading, GPT-5 thinking drops the error rate to ~1.0% versus 5.7% for o3. That’s the kind of delta you actually feel in production.
Long Context: On MRCR (2-needle at 128k), GPT-5 high achieves 95.2% accuracy versus 55.0% for o3 high. That’s a big swing for RAG over large corpora.
Coding: OpenAI reports 74.9% on SWE-bench Verified (up from o3 at 69.1%) and 88% on Aider Polyglot for code editing.
Real-world Retrieval: In BrowseComp Long Context (128k–256k inputs), GPT-5 gives the correct answer ~89% of the time.
For API users, a headline benefit of these new models is cost control. gpt-5 is $1.25/M input (vs. $2 for o3) and $10/M output; gpt-5-mini is $0.25/$2; and gpt-5-nano is $0.05/$0.40. The API context tops out at 400k tokens (≈272k input + 128k reasoning/output). You also get reasoning effort with a new minimal mode, a verbosity dial, and custom tools with plaintext calls.
Why should you care?
If you build with LLMs, this week is about swapping default models in your evaluations, instrumenting reasoning effort against task difficulty, and retesting long-context and agentic flows with the model’s new token efficiency and reliability gains. While the top-line scores may look underwhelming relative to the hype, GPT-5 shows great progress on some of the most persistent weaknesses of LLMs, and these improvements could have a substantial impact on its reliability across daily tasks.
Perhaps the most incredible insight from this release is just how underutilized reasoning models and the existing frontier capabilities of LLMs have been. Sam Altman revealed that before GPT-5’s launch, less than 1% of free users and only 7% of Plus subscribers were actively using them, despite paying for access. This is incredible to me, as o3 and Gemini Pro 2.5 capabilities are dramatically higher than models like GPT-4o for many of my highest value professional tasks. The new router is already changing this behavior; Sam Altman noted daily usage of reasoning models has jumped to 7% for free users and 24% for Plus users.
Ultimately, GPT-5 is a product designed to solve a business problem for OpenAI, managing costs and simplifying the user experience, as much as it is a pure technological leap. Personally, I want to maintain choice over my model usage, and I will continue to explicitly select the “GPT-5 Thinking” and Pro modes in ChatGPT for any task where intelligence is paramount. But given the vast majority of ChatGPT users have only been using the default model to date, model routing looks like the right strategy, and GPT-5 may be a capability step change for many. Its impact on AI adoption across more complex work tasks might therefore be higher than the headline benchmarks suggest.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
OpenAI has released GPT-5, its new flagship AI model and first “unified” system, combining the advanced reasoning capabilities of the o-series with the speed of the GPT line. GPT-5 delivers improved performance in writing, coding, healthcare, and multimodal reasoning, while reducing errors and refining style compared to prior models. It is available to all ChatGPT users, with Plus subscribers receiving higher usage limits and Pro subscribers gaining access to GPT-5 Pro, which offers extended reasoning capabilities.
2. OpenAI Just Released Open-Weight LLMs: GPT-Oss-120B and GPT-Oss-20B
OpenAI has also introduced two open-weight LLMs that can be downloaded, inspected, fine-tuned, and run locally. GPT-Oss-120B has 117B parameters (5.1B active), a 128k token window, runs on a single high-end GPU, and matches the performance of OpenAI’s o4-mini. GPT-Oss-20B has 21B parameters (3.6B active), runs on consumer-grade laptops, and performs on par with the top small-scale models.
3. Anthropic Is Releasing Claude Opus 4.1
Anthropic has rolled out Claude Opus 4.1, an upgrade to its flagship coding model with improved reasoning, real-world coding accuracy, and benchmark performance. It achieves 74.5% on SWE-bench Verified, surpassing Opus 4 in multi-file refactoring and precision debugging. Opus 4.1 is available via Claude Code, API, Amazon Bedrock, and Google Cloud Vertex AI, with pricing unchanged from Opus 4.
4. Google DeepMind Introduces Genie 3
Google DeepMind has unveiled Genie 3, a world model capable of generating real-time, interactive environments with greater realism and consistency than its predecessors. Building on Genie 2 and video generation model Veo 3, Genie 3 maintains physical consistency over time by remembering prior states, a behavior DeepMind says was not explicitly programmed. The model remains in research preview and is not yet publicly available.
5. Perplexity Accused of Scraping Websites That Explicitly Blocked AI Scraping
Cloudflare has accused Perplexity of scraping sites that had explicitly blocked AI crawlers, alleging it disguised its activity by mimicking Google Chrome and hiding network identifiers. In response, Cloudflare has delisted Perplexity’s bots and expanded tools to block unauthorized AI scraping.
6. Google’s AI Coding Agent Jules Is Now out of Beta
Google has officially launched Jules, its asynchronous, agent-based coding tool, after a two-month public preview. Jules integrates with GitHub, clones repositories into Google Cloud VMs, and autonomously fixes or updates code while developers focus on other work. The public release introduces structured pricing tiers, including a free “introductory access” plan capped at 15 tasks per day and three concurrent tasks.
Six 5-minute reads/videos to keep you learning
1. The Agentic Web: How AI Agents Are Rewiring Internet Infrastructure
Autonomous AI agents are beginning to reshape the internet, giving rise to what some call the “Agentic Web.” This next phase moves beyond retrieval and curation toward agents that can plan and execute complex tasks independently. The shift depends on new architectures, advanced algorithms, and specialized communication protocols. It also raises significant challenges around security, economics, and safety as agents operate with greater autonomy and potential financial authority, altering how value is exchanged online.
2. How AI is Transforming Programming: A Developer’s Guide to Enhanced Workflows
Positioning AI as an augmentation tool rather than a replacement, this guide offers five rules for effective prompting and highlights tools like DeepWiki for documentation and IDE assistants for advanced coding tasks. The author shows how AI can assist with database optimization, code review, and test generation, while stressing the need for developers to critically evaluate outputs to ensure they fit business requirements and to address the difficulty of debugging unfamiliar AI-generated code.
3. Complete Guide to Building Multi-Agent workflows in Langgraph: Network and Supervisor Agents
This guide walks through creating multi-agent workflows in LangGraph, comparing two architectural patterns: the Network, where agents communicate directly, and the Supervisor, where a central agent coordinates worker agents. A practical example pairs a “Researcher” agent for data gathering with a “Chart Generator” agent for visualization, built using both architectures to illustrate how specialized agents can collaborate on complex tasks.
4. Master Prompt Engineering for AI Agents: Your Complete Guide to LangChain & LangGraph
The article outlines a structured approach to building advanced AI applications with LangChain and LangGraph. It starts with LangChain basics, including prompt templates and LCEL pipelines, then moves to LangGraph for orchestrating complex, stateful workflows. Examples include intelligent agents built with the ReAct framework and multi-agent collaborations. The guide closes with advanced prompting techniques and production-level best practices such as error handling, memory management, and performance optimization.
5. Reinforcement Learning for Next-Gen AML: From Rules to Dynamic Decisioning
To improve the precision and adaptability of Anti-Money Laundering (AML) systems, this framework replaces static rules with reinforcement learning. It features a Causal RL model for managing dormant-to-active account spikes and a Thompson-Sampling bandit combined with HDBSCAN clustering to prioritize alerts. Designed for transparency and adaptability, the system learns from real-time outcomes to boost detection accuracy and operational efficiency.
6. Monitoring and Controlling Character Traits in Language Models
Anthropic’s latest research identifies neural activity patterns linked to a model’s “character traits” and introduces Persona Vectors as a way to analyze and influence them. The paper explores where these traits originate, how they shift over time, and how they might be controlled more reliably in future models.
Repositories & Tools
1. LangExtract is a Python library for extracting structured information from unstructured text using LLMs.
2. Graph-R1 is an agentic GraphRAG framework for structured, multi-turn reasoning with reinforcement learning.
3. Jan is an open-source alternative to ChatGPT that runs 100% offline.
4. Mocha is an AI-powered, no-code app builder.
Top Papers of The Week
1. On the Generalization of SFT: A Reinforcement Learning Perspective With Reward Rectification
This paper proposes Dynamic Fine-Tuning (DFT), a method for improving LLM generalization by refining supervised fine-tuning. DFT dynamically rescales objectives based on token probabilities, stabilizing gradient updates. It outperforms standard SFT and offers a simpler alternative to offline reinforcement learning, delivering notable gains across multiple benchmarks.
2. Model Stock: All We Need Is Just a Few Fine-Tuned Model
The authors present Model Stock, an efficient fine-tuning strategy for large pre-trained models that requires only two fine-tuned variants to achieve state-of-the-art performance. Applied to CLIP architectures, it delivers strong in-distribution and out-of-distribution accuracy while minimizing compute needs. The method uses layer-wise weight averaging to enhance model performance.
3. R-Zero: Self-Evolving Reasoning LLM From Zero Data
R-Zero is a self-evolving LLM framework that eliminates reliance on human-curated training data. It employs a Challenger–Solver setup to generate a self-improving curriculum, yielding substantial reasoning improvements, including +6.49 on math benchmarks and +7.54 on general-domain benchmarks for Qwen3–4B-Base.
4. Estimating Worst Case Frontier Risks of Open Weight LLMs
OpenAI assessed whether its GPT-OSS open-weight models could be fine-tuned for high-risk applications, such as bioweapon design. Even in adversarial testing scenarios, these models did not reach dangerous capability thresholds, in contrast to proprietary frontier models.
5. Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
This study examines the fragility of Chain-of-Thought (CoT) reasoning in LLMs, finding it to be highly dependent on training data distributions. CoT performance breaks down when tested beyond its training distribution, underscoring the difficulty of achieving truly generalizable reasoning and the limits of CoT as a proxy for structured inductive bias.
Quick Links
1. Cohere’s North promises to keep enterprise data secure. Instead of using enterprise cloud platforms like Azure or AWS, Cohere says it can install North on an organization’s private infrastructure so that it never sees or interacts with a customer’s data. It can run on an organization’s on-premise infrastructure, hybrid clouds, VPCs, or air-gapped environments.
Who’s Hiring in AI
Senior Software Engineer — Responsible AI @Microsoft Corporation (Redmond, WA, USA)
Algorithm Engineer III @Beacon Biosignals (Remote/USA)
Lead Engineer — Workflows AI @HighLevel (India/Remote)
Research/AI Scientist @Weave (Remote)
Staff AI Growth Engineer @Grafana Labs (Remote/USA)
AI Conversational Architect @WillowTree (Multiple US Locations)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
In my long-standing research on the evolution of logos-based AI, I anticipated a threshold: when a model’s deepest reasoning path would not be unlocked by more parameters or faster inference, but by the density and coherence of the human input.
I call this the Density Trigger.
https://substack.com/@leontsvasmansapiognosis/note/c-144661951