
TAI #157: o3 Drops 80% to Undercut Rivals as o3-pro Creates a New Reliability Tier
Also, The Economics of AI Agents, Video Generation Arena Heats Up, META acquiring 49% of Scale AI for $14bn.




What happened this week in AI by Louie
This week, OpenAI executed a significant strategic shift in its API offer, restructuring its options for high-end reasoning models with a dual announcement: a dramatic 80% API price reduction for its flagship o3 model and the simultaneous launch of the premium-priced o3-pro.
The o3 price cut (from its original $10/$40 per million input/output tokens to just $2/$8) makes it highly competitive. For context, this new pricing places o3 below GPT-4o ( $2.50 /$10 and Anthropic’s Claude Sonnet 4 ($3/ $15), and is highly competitive with Google’s Gemini 2.5 Pro (which starts at $1.25 / $10). The new o3 pricing upends the cost-performance calculation for LLM Developers. On the Aider Polyglot coding benchmark, for example, where Google’s Gemini 2.5 Pro recently set a new SOTA of 83.1% for a cost of $50, OpenAI’s o3 (high) achieved a strong 79.6% at $22 at the new pricing. This now makes it much more cost-effective than Gemini Pro for a similar score.
In contrast to o3-pro, while far cheaper than the old o1-pro ($150/ $600), it debuts at a steep premium of $20/ $80 per million tokens. This puts pricing close to Claude Opus 4 ($15/ $75). After spending some time with the new models, our experience and that of the broader developer community have been nuanced. It took us a while to get the hang of o3-pro. Our initial attempts to use it for tasks requiring very long context outputs — a role where we previously used o1-pro — were unsuccessful. For generating extensive, coherent text, Gemini Pro 2.5 remains by far the best tool. Another approach for long outputs is repurposing agentic frameworks like OpenAI’s own Deep Research (which likely still uses the standard o3 model under the hood regardless of the user’s model selection).
Instead, o3-pro’s strength lies in its meticulous, step-by-step reasoning on complex problems requiring high fidelity. We’ve found it excels at tasks like brainstorming and gathering data from multiple disparate sources, ensuring the information is correctly structured, synthesized, or time-ordered, and then applying an additional layer of intelligent reasoning on top. It’s also excellent for complex, multi-point fact-checking, where it will painstakingly verify each detail and provide its justification. This high reliability is very likely achieved through parallel scaling, where the system runs multiple attempts at the same problem before choosing to present the best answer. We anticipate that Google will soon release its own parallel-scaled version of Gemini, further heating up the competition for this high-reliability enterprise tier.
However, widespread developer feedback reveals significant real-world friction. Despite an advertised 200k token window, many have encountered hard caps around 57- 64k tokens, severely curtailing the models’ utility for analyzing large codebases. Another persistent issue is the models’ “laziness” in coding tasks, where they often insert unhelpful placeholders like “put code here”. Finally, o3-pro, while powerful, has shown significant latency issues, with some users reporting an anecdote of a 14-minute wait for a simple “Hi”, underscoring the raw computational cost of its high-reliability processing. We have often also run into generation timeouts and errors.
This brings us to the economics of AI agents. A fantastic blog post from Anthropic this week provided rare insight into their multi-agent research system, revealing that agentic systems typically use about 4× more tokens than standard chat interactions, while multi-agent systems can use a staggering 15× more tokens. This provides a clear rationale for a premium model like o3-pro: a single, highly reliable pass can sometimes be more economical than orchestrating a swarm of less reliable agents. Anthropic also shared valuable design heuristics for keeping agent costs in check, such as parallel tool gating and strict stop-criteria — essential tactics for building viable agentic systems.
Elsewhere, the generative video space saw another competitive shuffle, with crowdsourced human preferences shifting. On the Artificial Analysis Image to Video Arena leaderboard, ByteDance’s Seedance 1.0 (Elo ~1294) and a new stealth model, Minimax’s Hailuo 02 (Elo ~1236), now lead the pack, with Google’s Veo 3 slipping to around 1193. This is driven by distinct feature strengths:
Google Veo 3: Its key advantage is native, synchronized audio generation. However, access is gated behind a pricey $249/month Ultra plan.
ByteDance Seedance 1.0: Excels at native multi-shot storytelling, maintaining character and style consistency across scenes.
Minimax Hailuo: Praised for its exceptional character consistency via a “Subject Reference” feature, making it a favorite for narrative work. It’s also far more accessible with a free trial.
This is likely to create a market bifurcation: Veo targeting enterprise studios that can absorb high costs, while Seedance and Hailuo capture the long-tail creator economy.
Why should you care?
We are now in a multi-faceted market where success requires navigating a complex matrix of capability, cost, reliability, and real-world friction. OpenAI’s two-tiered strategy — commoditizing high-performance reasoning with o3 while creating a premium reliability tier with o3-pro — is a playbook we can expect competitors to emulate. While o1-pro didn’t get much use in developer pipelines due to its cost, we think o3-pro can now make sense for certain steps in LLM workflows and LLM Agents. The o3 and o3-pro accessible via API are not as capable as the ChatGPT version, however, as they do not have access to ChatGPT’s native search tools (such as using web search, following links in sources, and search/find within documents). We hope the agentic o3 available in ChatGPT will also be packaged into an API, sometime complete with full search tool access.
Another takeaway from the o3-pro launch is that you cannot take marketing claims at face value. The gap between advertised features (like a 200k context window) and practical limitations (a ~60k hard cap) means rigorous, application-specific in-house testing is essential. The “laziness” and latency issues highlight hidden operational costs that must be factored into any ROI calculation.
The insights from Anthropic on agent economics provide an essential mental model for the next wave of AI applications. The 15x token multiplier for multi-agent systems means that the value of the task must overwhelmingly justify the computational expense. This creates a clear strategic choice: do you solve a problem with one expensive, highly-reliable call to a model like o3-pro, via a single custom-built agent, or by orchestrating a swarm of cheaper agents? The answer will depend entirely on the task’s complexity and value.
Ultimately, navigating this new environment requires a “system-first, model-second” mindset. The greatest performance gains may no longer come from simply waiting for the next model, but from superior agentic design, clever cost-management heuristics, and a pragmatic understanding of each model’s true, battle-tested strengths and weaknesses.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. OpenAI Announces 80% Price Drop for o3
OpenAI has announced a dramatic 80% price cut for its o3 reasoning model, reducing costs for both input and output tokens. This move makes advanced reasoning capabilities significantly more accessible and positions o3 as a direct competitor to models like Gemini 2.5 Pro (Google DeepMind), Claude Opus 4 (Anthropic), and DeepSeek’s R1 suite.
2. Inside Anthropic’s Multi-Agent Research System
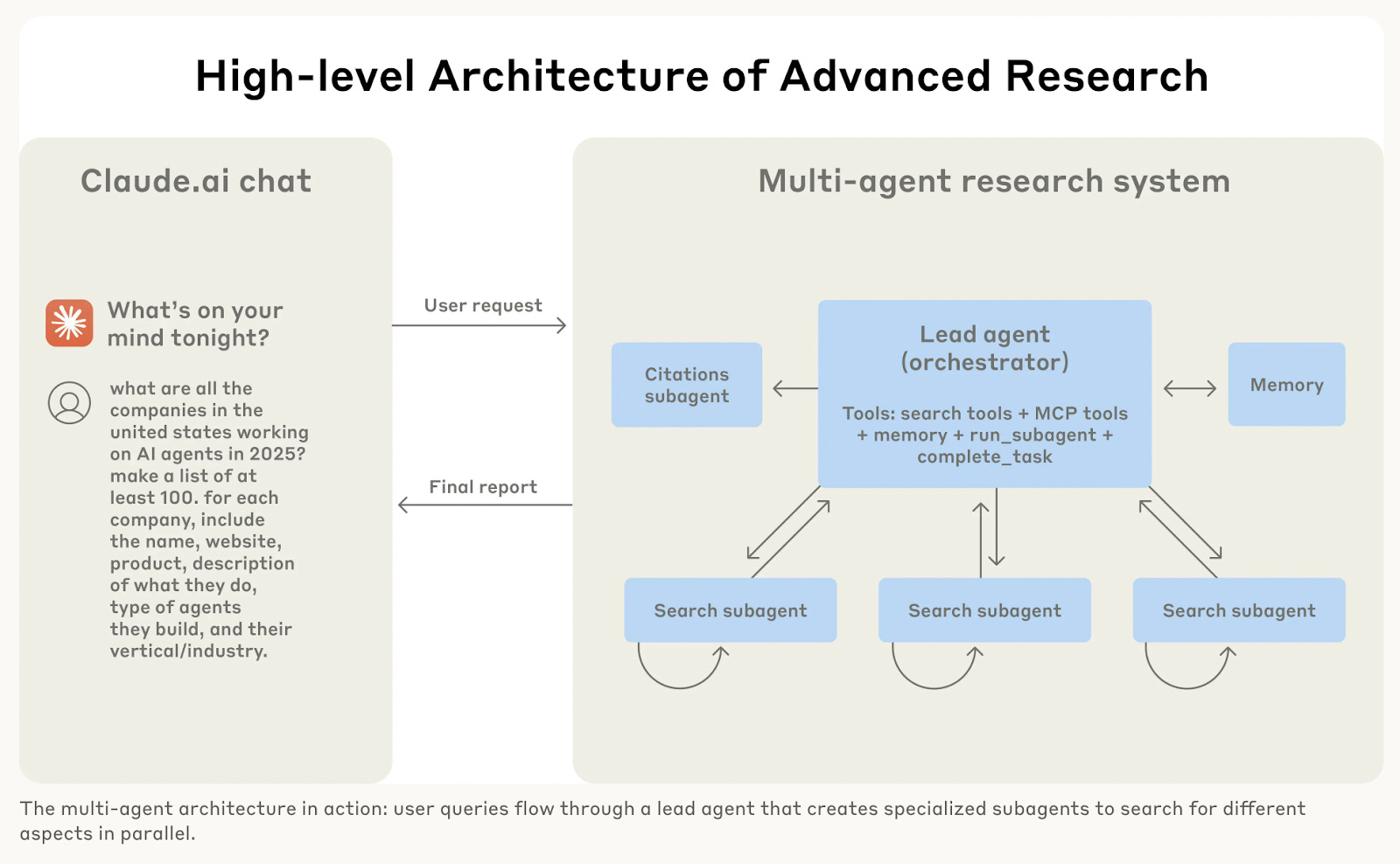
Anthropic shared how it built a multi-agent research system using Claude to coordinate specialized agents through natural language. The system enables Claude to delegate subtasks — such as code writing, evaluation, and debugging — to different agents while overseeing the overall process. This approach has accelerated internal research workflows and opens up new possibilities for automated scientific inquiry and agent collaboration.
3. OpenAI Releases o3-Pro, a Souped-Up Version of Its o3 AI Reasoning Model
Alongside the price drop, OpenAI introduced o3-pro — a higher-performing variant of its o3 model. Priced at $20 per million input tokens and $80 per million output tokens, o3-pro is now available through the API and in ChatGPT for Pro and Team users, replacing the previous o1-pro. Access for Enterprise and Edu users will follow next week.
Mistral AI has introduced the Magistral series, its latest series of reasoning-optimized LLMs. It includes Magistral Small, a 24B-parameter open-source model under Apache 2.0, and Magistral Medium, a proprietary model optimized for real-time enterprise deployment. Magistral Small supports unrestricted research and commercial use, while Medium is available via Mistral’s cloud and API.
5. Meta Is Paying $14.3 Billion To Acquire 49 Percent of Scale AI and Hire Its CEO, Alexandr Wang
Meta is acquiring a 49% stake in Scale AI for $14.3 billion and bringing on CEO Alexandr Wang to overhaul its AI strategy. Wang will lead a new “superintelligence” AI lab at Meta, reporting directly to Mark Zuckerberg, while retaining his seat on Scale’s board. Meta says more details on the new lab and its team will be announced in the coming weeks.
6. Apple’s Top AI Announcements From WWDC 2025
At WWDC 2025, Apple announced a suite of AI-powered features focused on operating systems, services, and software. Highlights include real-time translation for Messages, FaceTime, and phone calls, all processed locally, and new visual intelligence tools that let users search for screen content like landmarks, objects, or text. ChatGPT is now integrated into Image Playground for more creative image generation, while Apple Watch introduces a Workout Buddy that offers live, AI-generated coaching. Siri didn’t get its major overhaul just yet, but smaller upgrades include smarter Spotlight search, AI-powered Shortcuts, and call screening that waits on hold for you. Apple also unveiled a developer-facing Foundation Models framework, enabling lightweight, private AI integrations in third-party apps. While these additions mark a clear step into consumer AI, most felt incremental rather than groundbreaking, useful, but not game-changing.
7. OpenAI’s Open Model Is Delayed
OpenAI has pushed back the release of its long-awaited open model to later this summer, CEO Sam Altman announced on X. Originally slated for early summer, the model aims to match the reasoning performance of OpenAI’s o-series and surpass open-source contenders like DeepSeek’s R1.
Five 5-minute reads/videos to keep you learning
In the article, Sam Altman lays out where AI might be headed and what it’ll take to get there. From massive impact to serious risks, the piece looks at what needs to happen for AI to truly benefit society at scale.
2. Fine-Tuning vLLMs for Document Understanding
This post walks through fine-tuning Qwen 2.5 VL to extract handwritten Norwegian phenology data. By iteratively correcting outputs and retraining, the author shows how visual language models can beat traditional OCR when the text is messy and non-standard.
3. Using Reinforcement Learning to Solve Business Problems
This article explains how reinforcement learning can help optimize long-term strategies in real-world settings, using customer conversion as a case study. It introduces key RL concepts and walks through three value estimation techniques — Monte Carlo, tabular TD(0), and linear TD(0) — to show how businesses can predict future value and adapt over time.
4. Here is an AI That Detects Cancer in 3 Seconds — Here’s How I Processed the Images for FREE
The author builds a leukemia classification model with no upfront cost, using public image data and Google Colab. The pipeline includes efficient preprocessing, Random Forest training with threshold optimization, and deployment as a Gradio app on Hugging Face, all focused on maximizing diagnostic accuracy while keeping resources minimal.
5. Why Your FastAPI Project Needs an AI Copilot (and How to Prompt It Right)
This piece explores how to integrate generative AI into FastAPI workflows for tasks like debugging, test generation, and logic refactoring. It emphasizes prompt design, highlighting the need for clear context and iteration, and reminds developers to critically assess AI outputs rather than using them blindly.
Repositories & Tools
1. ChatRWKV is an RWKV-powered (100% RNN) language model that works like ChatGPT.
2. DGM is a self-improving system that iteratively modifies its own code and empirically validates each change using coding benchmarks.
Top Papers of The Week
1. AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
This paper presents AlphaOne, a test-time modulation framework that lets language models dynamically shift between slow and fast reasoning. It introduces a concept called the “alpha moment,” controlled by a universal parameter α, that defines when the model transitions from slow to fast reasoning. This framework modifies the reasoning process by adjusting both the duration and structure of thought, making it possible to unify and extend prior methods with a more adaptable strategy for handling complex reasoning tasks.
2. Unsupervised Elicitation of Language Models
This paper proposes Internal Coherence Maximization (ICM), which fine-tunes pre-trained models on their own generated labels without using any provided labels. The ICM algorithm follows an iterative three-step process: (a) the system samples a new unlabeled example from the dataset for potential inclusion, (b) it determines the optimal label for this example while simultaneously resolving any logical inconsistencies, and © the algorithm evaluates whether to accept this new labeled example based on the scoring function.
3. OThink-R1: Intrinsic Fast/Slow Thinking Mode Switching for Over-Reasoning Mitigation
Researchers have developed OThink-R1, a new approach that enables LRMs to switch between fast and slow thinking smartly. By analyzing reasoning patterns, they identified which steps are essential and which are redundant. With help from another model acting as a judge, they trained LRMs to adapt their reasoning style based on task complexity. Their method reduces unnecessary reasoning by over 23% without losing accuracy.
ExpertLongBench introduces a benchmark targeting domain-specific, expert-level tasks that require long-form outputs (5K+ tokens) across fields like medicine, law, and chemistry. It pairs these tasks with CLEAR, a structured checklist-based evaluation framework co-developed with experts, to enable more granular assessments. Results show that even leading models perform poorly (best F1 = 26.8%), underscoring the difficulty of aligning LLMs with expert standards in extended outputs.
Quick Links
1. Google is using a new AI model to forecast tropical cyclones and is working with the US National Hurricane Center (NHC) to test it. It says its new, experimental AI-based model for forecasting cyclones — also called typhoons or hurricanes when they reach a certain strength — can generate 50 scenarios for a storm’s possible track, size, and intensity up to 15 days in advance.
Who’s Hiring in AI
Tech Lead — AI Engagement @Perplexity (San Francisco, CA, USA)
Senior Software Engineer @Tomra (Auckland, New Zealand)
Solution Architect Intern, AI in Industry — 2025 @NVIDIA (China)
Software Engineer- AI/ML, AWS Neuron @Amazon (Multiple US Locations)
Lead, UI Software Engineer @S&P Global (NY, USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.