
TAI #152: AI Passes Physician-Level Responses in OpenAI's HealthBench
Also, Qwen 3 Quantized, NVIDIA's Open Code Models, Gemini 2.5 Pro Preview update




What happened this week in AI by Louie
This week, OpenAI unveiled HealthBench, a significant new open-source benchmark evaluating AI in realistic healthcare scenarios. This comes alongside other key developments, such as a strong coding ability upgrade to Gemini Pro 2.5 and Alibaba releasing quantized versions of its impressive Qwen 3 models — a trend we’ve flagged where AI labs increasingly handle the quantization work, making it easier for users to deploy these powerful models locally.
Developed with over 262 physicians, HealthBench uses 5,000 multi-turn conversations and 48,000+ rubric criteria to grade models. OpenAI’s o3 leads with an overall score of 0.60 on HealthBench. This compares favorably to other strong performers like Grok 3 (0.54), Gemini 2.5 Pro (Mar 2025 release, 0.52), and OpenAI’s own GPT-4.1 (0.48). Other evaluated models include Claude 3.7 Sonnet (with extended thinking, scoring ~0.35 with “Health data tasks” as a strong point but lower on “Context seeking”), Llama 4 Maverick (~0.25 overall, weaker on “Context seeking”), and older models like GPT-4o (August 2024, 0.32) and GPT-3.5 Turbo (0.16). This represents a huge improvement for frontier models in recent months. Notably, smaller models like GPT-4.1 nano also show dramatic cost-performance gains, outperforming the August 2024 GPT-4o while being 25x cheaper. On the “HealthBench Hard” subset, even o3 scores just 0.32, highlighting that significant challenges remain.
The most provocative result concerns human-AI interaction. When physicians used older September 2024 AI models (o1-preview, GPT-4o) as references, they improved upon the AI’s standalone responses (physician-assisted score ~0.31 vs. AI alone ~0.28). Both outperformed physicians working without AI (who scored just ~0.13)! However, with the latest April 2025 models (o3, GPT-4.1), physicians using these AI responses as a base, on average, did not further improve them (both AI alone and AI+physician scoring ~0.48–0.49). For the specific task of crafting HealthBench responses, the newest AI seems to be performing at or beyond the level human experts could refine, even with a strong AI starting point.
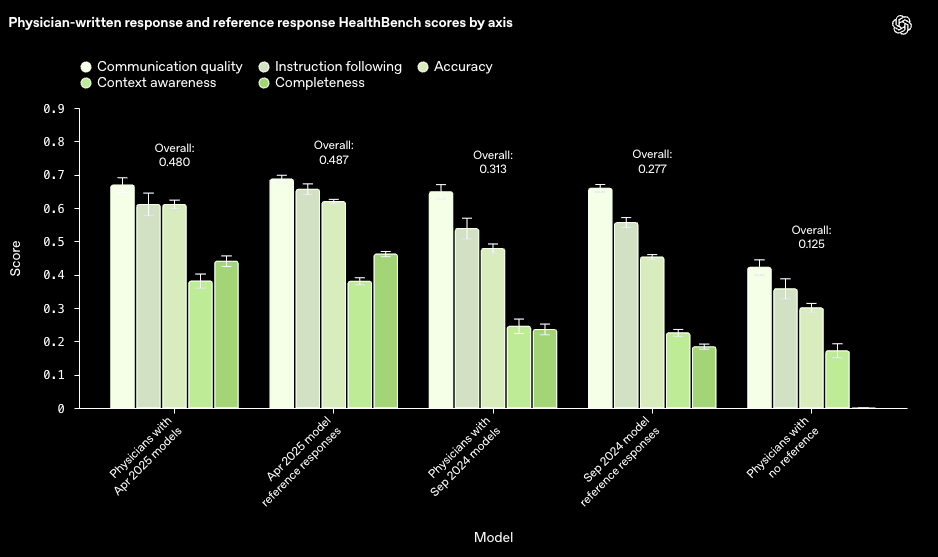
The HealthBench finding — where the latest AI alone matched the human-AI team for specific response generation — pushes the copilot vs. automation debate. At Towards AI, we advocate for symbiosis. The aim should be true collaboration in full knowledge of AI’s strengths and weaknesses. We believe the best results often emerge when humans actively guide AI, putting all of their own expertise and sources and tips on how to perform a task into the model, sharing with it to try to get the best results, and not just testing how it can perform independently.
So why didn’t the AI+physician combination surpass the latest AI in HealthBench? Perhaps the AI is already highly optimized for this structured benchmark task, while most questions were not real-world situations a physician would meet day to day. It’s also likely, as I often note, that most professionals are still early in building a skill and intuition for working with AI to achieve the benefits from AI collaboration. If physicians weren’t effectively merging their own strengths with AI’s weaknesses or using advanced prompting or refinement, further gains from an already strong AI output might be elusive. Moreover, expert biases or a preference for ingrained approaches over an AI’s suggestion (if its reasoning isn’t clear or trusted) can play a role — a challenge common across professions. Better AI explainability is key to building that trust.
The same pattern is unfolding in other rule-bound professions. In law, an LLM can already locate controlling precedent and draft a first-pass brief, leaving the attorney to confirm jurisdiction, apply nuanced intent tests, and sign off on strategy. In accounting, the model can classify a lease, flag accounting edge cases, or trace an intercompany cost. Across domains, the machine now handles the “what does the rulebook say for this fact pattern?” lookup, while humans arbitrate grey zones, resolve conflicts, and bear liability. The lesson from HealthBench is not that experts vanish; it’s that their comparative advantage shifts upward, from rote rule retrieval to judgment, context, and accountability. But in all domains, adapting to these new workflows takes time and effort to get results. And universally, explainability, reliability, and liability are critical gating factors for deeper adoption.
Why should you care?
The HealthBench findings have implications for all professional AI use. The fact that top-tier AI has now crossed a threshold where it can match or, in specific structured tasks, even be unimprovable by human experts (when those experts are refining the AI’s own output) is a clear indicator of AI’s accelerating power.
This doesn’t mean AI replaces professionals. Instead, it demands a re-evaluation of how we work day to day. The “human-in-the-loop” model remains critical, especially for complex, high-stakes decisions where nuance, ethical judgment, and accountability are paramount — themes common to medicine, law, and finance. The key is shifting from passive use to active, expert-guided collaboration with AI.
The current relatively low professional adoption and often sub-optimal use of AI, despite its proven capabilities on benchmarks, represents a massive untapped opportunity. The gap here is, in part, a failure of benchmarks to truly mirror real-world tasks, but it is also just a failure to teach effective AI usage to professionals. In some tasks now, AI has reached the level where human plus AI used poorly performs worse than AI alone. We don’t think this case is truly a reality for many real-world tasks as a whole, but it does underscore the urgency of learning to use AI symbiotically and effectively.
As AI continues to improve in areas like context handling and coding (Gemini 2.5 Pro), multimodal interaction (GPT-4o with images), web search, and tool use (o3), the imperative to learn effective AI collaboration will only grow. Those who master this human-AI partnership will lead in their respective fields, driving new levels of productivity and innovation.
To address this, we are very soon releasing a new 70+ lesson course, AI for Business Professionals, to try to fix this adoption lag, including modules for managers and leaders on how to bring AI into their business. So stay tuned for the release!
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Alibaba Releases Quantized Qwen 3 Models
Alibaba’s Qwen 3, released two weeks ago, is now available in inference-optimized form for local deployment across popular inference engines — including Ollama, LM Studio, SGLang, and vLLM. It supports multiple formats like GGUF, AWQ, and GPTQ, making it easy to run on a wide range of hardware setups.
2. NVIDIA Open-Sources Open-Code Reasoning Models (32B, 14B, 7B)
NVIDIA has open-sourced its Open Code Reasoning (OCR) model suite — three high-performance LLMs (32B, 14B, 7B) optimized for code understanding and problem-solving. Released under the Apache 2.0 license, these models outperform OpenAI’s o3-Mini and o1 (low) on the LiveCodeBench benchmark.
3. Google Released the Gemini 2.5 Pro Preview
Google has released a preview of Gemini 2.5 Pro, featuring enhanced support for building interactive web apps, code transformation, and multimodal reasoning. It now leads the WebDev Arena Leaderboard, scoring 147 Elo points above its predecessor. Available in Google AI Studio, the update also reduces tool call failures and improves developer productivity.
4. Mistral Announces Mistral Medium 3
Mistral AI has launched Mistral Medium 3, a high-performing model offering strong coding and multimodal capabilities at 8x lower cost. It outperforms competitors like Cohere Command A and Llama 4 Maverick, and is optimized for seamless deployment on platforms like Amazon SageMaker.
5. Anthropic Rolls Out an API for AI-Powered Web Search
Anthropic has introduced a web search feature to the Claude API, enabling developers to build AI agents with real-time access to web data. Designed for industries like finance, legal, and software, the API allows for domain-level control and result verification, significantly improving Claude’s accuracy and relevance.
6. Google Launches ‘Implicit Caching’ To Make Accessing Its Latest AI Models Cheaper
Google’s new implicit caching feature for the Gemini API cuts costs by up to 75% for repeated queries using Gemini 2.5 Pro and 2.5 Flash. The system automatically detects recurring prefixes in prompts — developers are encouraged to structure repeated context at the start of requests to maximize savings.
7. Microsoft and OpenAI May Be Renegotiating Their Partnership
Microsoft and OpenAI are reportedly in discussions to restructure their multibillion-dollar partnership, aiming to facilitate OpenAI’s transition into a public benefit corporation and potential future IPO. Central to the negotiations is determining Microsoft’s equity stake in OpenAI’s for-profit arm, with Microsoft potentially reducing its share in exchange for extended access to OpenAI’s technologies beyond the existing 2030 agreement.
Five 5-minute reads/videos to keep you learning
1. Agentic RAG: When AI Starts Thinking Like a Researcher
This piece explores Agentic RAG, a framework where AI acts more like a researcher, searching through large volumes of data, extracting key insights, and generating novel outputs. It walks through a simulated Agentic RAG pipeline, discusses real-world use cases, and highlights the current limitations.
2. The 4 Things Qwen-3’s Chat Template Teaches Us
Qwen-3 introduces a significantly more advanced chat template using Jinja, setting it apart from previous versions. This article breaks down the key differences, offering insight into how template structure shapes model behavior.
3. An Analysis of Hallucination in Leading LLMs
This is a deep dive into Phare, a multilingual benchmark built to evaluate LLM safety across hallucination, bias, harmfulness, and misuse potential. The post focuses on hallucination, exploring when and why it happens, and which models are most vulnerable.
4. Grok 3’s DeepSearch with Google’s new AI Mode (Search)
This comparison highlights Grok’s DeepSearch tool and Google’s new AI Mode in Search. With brief case studies, the article shows how each tool performs, where they shine, and when to use one over the other.
5. RL Training For Math Reasoning
Perplexity shares its experience building reinforcement learning infrastructure for math reasoning. The article outlines their challenges, design choices, and insights from training models to reach state-of-the-art performance on math tasks.
Repositories & Tools
1. NanoVLM is a simple repository for training/finetuning a small-sized VLM with a lightweight implementation in pure PyTorch.
2. WebThinker is a deep research framework fully powered by large reasoning models (LRMs).
Top Papers of The Week
1. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Absolute Zero introduces a reinforcement learning paradigm where a single model autonomously creates and solves tasks to enhance its reasoning without external data. The Absolute Zero Reasoner uses a code executor for task validation and solution verification, achieving state-of-the-art performance in coding and mathematical reasoning without relying on human-curated examples, demonstrating versatility across various model scales and classes.
2. A Survey of AI Agent Protocols
This survey offers a structured overview of existing agent protocols, introducing a two-dimensional classification: context-oriented vs. inter-agent, and general-purpose vs. domain-specific. It includes a performance comparison across dimensions like security, scalability, and latency.
3. Scalable Chain of Thoughts via Elastic Reasoning
This paper introduces Elastic Reasoning, a framework that enables large reasoning models to produce more efficient chain-of-thought outputs by separating the reasoning process into “thinking” and “solution” phases with independently allocated budgets. This approach improves performance under strict inference constraints and generalizes well to unseen budget scenarios while maintaining or even improving solution quality.
4. Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
The UnifiedReward-Think model strengthens vision models’ alignment with human preferences using a multimodal Chain-of-Thought reasoning approach. By employing exploration-driven reinforcement fine-tuning, this model learns complex reasoning processes and improves visual understanding and generation rewards.
5. Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
Large Multimodal Reasoning Models (LMRMs) integrate text, images, audio, and video, advancing from modular pipelines to unified frameworks. This research survey outlines a developmental roadmap, highlighting innovations like Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning. These models aim for adaptive reasoning and planning in real-world environments, addressing challenges in omni-modal generalization and reasoning depth.
Quick Links
1. ChatGPT’s deep research tool gets a GitHub connector, allowing developers to ask questions about a codebase and engineering documents. The connector will be available for ChatGPT Plus, Pro, and Team users over the next few days, with Enterprise and Edu support coming soon. Deep Research has also added PDF outputs.
2. Alibaba researchers introduce ZeroSearch, a method for training LLMs without using search APIs. It replaces real-time search with a document simulator to train QA models using multi-step reasoning. A 14B model trained this way outperforms Google Search-powered baselines on standard benchmarks.
3. HuggingFace releases Open Computer Agent, a free Operator-like agentic AI tool. Similar to OpenAI’s Operator, you can prompt Open Computer Agent to complete a task, and the agent opens the necessary programs and figures out the required steps.
Who’s Hiring in AI
Staff Software Engineer, Generative AI, Data Analytics @Google (Sunnyvale, CA, USA)
Product Owner — Research & Transversal AI/ML Workflows @Sanofi Group (Hyderabad, India)
Machine Learning Engineer, Siri @Apple (Cupertino, CA, USA)
ML Ops Engineer @Insight Global (Remote)
AI Specialist SE @Salesforce (Remote/US)
Generative AI Engineering Manager @Nexxen (Tel Aviv, Israel)
Sr Lead AI Engineer @Lumen (Remote/US)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.