
TAI #116; Rise of the Protein Foundation Model; Comparing AlphaProteo, Chai-1, HelixFold3, and AlphaFold-3.
Also, Claude Enterprise, Replit Agents, SSI Raise, Deepseek 2.5, and more!

What happened this week in AI by Louie
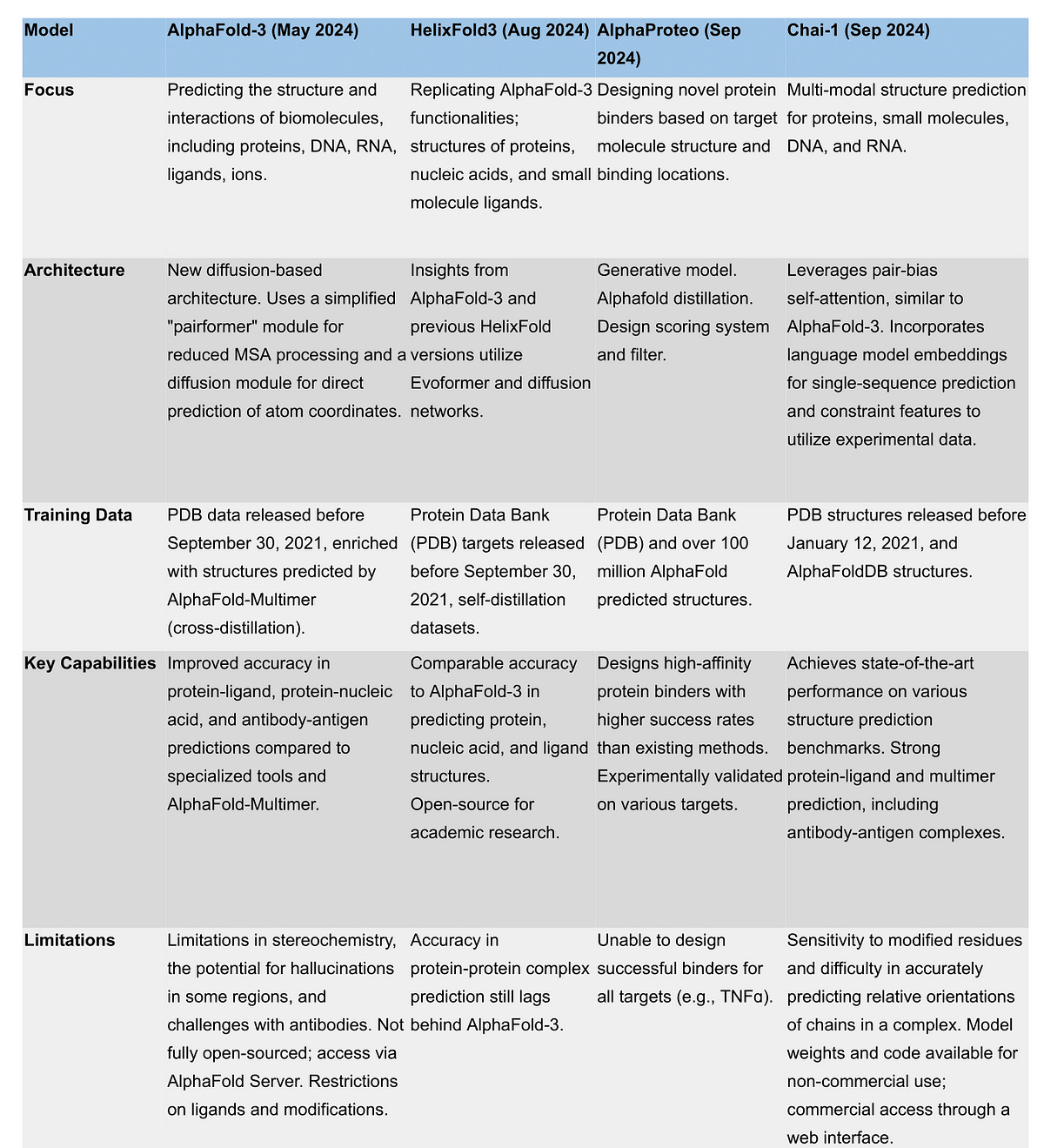
There were plenty of LLM developments again this week, including a new Agent coding product from Replit, an Enterprise LLM platform with a 500k Claude context window at Anthropic, a new Deepseek 2.5 model, and a $1bn seed fundraising by Ilya Sutskever for his new startup. There has also been plenty of progress in AI outside LLMs, and one of our favorite applications for AI is protein, biomolecule, and drug design foundation models. This week was very busy on this front with Deepmind’s AlphaProteo protein binder model and Chai Discovery’s Chai-1 multimodal structure prediction model released. This followed Baidu’s HelixFold3 model last week, which attempted an open-source replication of AlphaFold-3 (itself released in May).
Chai Discovery came out of stealth with a $30m seed round and launch of its Chai-1 model. It stands out as a highly versatile multi-modal model, excelling in various structure prediction tasks. It offers model weights and code for non-commercial use, and commercial access is provided through a web interface. AlphaProteo from Google DeepMind specifically targets the design of novel protein binders, crucial for drug discovery and research. It leverages AI to generate high-affinity binders with greater efficiency than traditional methods. HelixFold3, developed by the PaddleHelix team at Baidu, focuses on replicating the capabilities of AlphaFold-3 in an open-source manner, demonstrating comparable accuracy in predicting the structures of proteins, nucleic acids, and small molecule ligands.
Why should you care?
To fully understand human biology and design treatments for more diseases, we need to have a better understanding of proteins, protein binding, and interactions with other biomolecules. AI use in drug development or drug target identification has already shown very positive early results. It can already cut development time down to ~30 months from initiation to phase 1 trial (vs. 60 months for normal drugs), and a recent study measured an 80–90% phase 1 success rate for AI drugs (vs. 40–65% for normal drugs). However, there are still only ~70 AI drugs in clinical trials relative to many thousands overall, and none has yet passed phase 3.
These four new AI protein models showcase the rapid progress and diverse applications within protein structure prediction, which we expect to lead to faster progress in AI-assisted drug design. Each model offers unique strengths and addresses specific challenges in the field.
While these models alone won’t find a new drug — (separate models need to be used to identify new drug targets, for example, more data needs to be collected for many areas of biology, and many lab experiments are still needed to verify and iterate predictions) — we think the emergence of these protein foundation models could potentially be the catalyst for a “chatgpt” moment for AI’s use in drug design. AI tools are now much more accessible, and we hope many more biology “foundation” models” will be developed and made available.
— Louie Peters — Towards AI Co-founder and CEO
In collaboration with Bright Data:
See how businesses are transforming their AI systems using cutting-edge, real-time, and ethically sourced web data.

Stay current with real-time insights: AI models thrive on real-time data from the web, enabling them to reflect the latest trends and deliver accurate, up-to-the-minute responses.
Access diverse perspectives across the web: Tap into rich, unstructured data from millions of online sources like news platforms, forums, and social media, providing AI with invaluable, varied content for deeper learning.
Boost LLM performance with real-world context: Large Language Models gain a competitive edge by using nuanced web data, improving their ability to understand context, tone, and intent for more refined output.
Scale data collection effortlessly: With Bright Data, businesses can scale data gathering operations based on their needs, seamlessly adapting to real-time changes in demand while fueling AI models with the latest information.
Ensure data collection is ethical and compliant: Navigate the complexities of data privacy regulations confidently. Bright Data ensures data is collected transparently, upholding legal standards and ethical guidelines.
🔗 Read more about how web data can elevate your AI systems today!
Hottest News
1. Replit Announced Replit Agent
Replit announced Replit Agent in early access. It is an AI-powered tool that assists users in building software projects. It can understand natural language prompts and help create applications from scratch, as well as automate tasks such as setting up a dev environment, installing packages, configuring DB, and more.
2. Chai Discovery Releases Chai-1
Chai-1 is a new multi-modal foundation model for molecular structure prediction. It enables unified prediction of proteins, small molecules, DNA, RNA, covalent modifications, and more.
3. Anthropic Introduces Claude for Enterprise
The Claude Enterprise plan to help organizations collaborate with Claude using internal knowledge. It offers an expanded 500K context window, more usage capacity, and a native GitHub integration. It also includes security features like SSO, role-based permissions, and admin tooling.
4. Together AI Presents a New Approach for Distilling and Accelerating Hybrid Models
Together AI presents a case for distilling Transformer models into hybrid linear RNNs like Mamba. As per the research paper, this approach will preserve the generative capabilities of Transformers and significantly enhance their efficiency, making them more suitable for deployment. The distilled hybrid Mamba model (50%) achieves a score in the MT benchmark similar to the teacher model and slightly better on the AlpacaEval benchmark in both LC win rate and overall win rate. We see this as a very promising method to deploy leading LLMs more affordably, and it may join the model inference optimization toolkit, such as quantization, pruning, and more traditional transformer-to-transformer distillation.
5. Ilya Sutskever’s Startup, Safe Superintelligence, Raises $1B
Ilya Sutskever, co-founder of OpenAI, has launched Safe Superintelligence (SSI), an AI startup focused on developing safe superintelligent AI systems. SSI recently raised $1 billion, valuing the company at $5 billion, with backing from top venture capital firms like Andreessen Horowitz and Sequoia Capital. The funds are earmarked for computing power and talent acquisition, with a core focus on foundational AI research and safety.
6. OpenAI Considers $2,000 Monthly Subscription Prices for New LLMs
OpenAI is reportedly considering a $2,000 monthly subscription for advanced LLMs like Strawberry and Orion, a significant increase from the current $20 ChatGPT Plus fee. Additionally, OpenAI is looking to streamline its corporate structure to attract investment, aiming for a valuation above $100 billion, while garnering interest from major investors like Apple and Microsoft. We are skeptical the $2,000 price point will materialize, aside from maybe large enterprise plans, given competition in the LLM space and progress on inference costs. However, we see a lot of potential for investing in significantly higher inference time compute to achieve new capabilities.
7. Intel CEO To Pitch Board on Plans To Shed Assets Cut Costs
Intel CEO Pat Gelsinger is set to present a cost-cutting strategy involving asset sales and scaled-back capital expenditures, which may include halting a $32 billion German factory project. Engaging Morgan Stanley and Goldman Sachs, Intel aims to stabilize amidst financial difficulties and intense AI sector competition.
8. AlphaProteo Generates Novel Proteins for Biology and Health Research
AlphaProteo, a new AI tool by DeepMind, designs novel proteins with high binding affinity for targets like VEGF-A, enhancing drug development and biological research. Trained on extensive protein data, it often outperforms existing methods and optimized binders.
9. Elon Musk Claims He Just Activated the World’s Most Powerful AI Supercomputer
Elon Musk’s xAI has launched Colossus, a major training cluster boasting 100,000 Nvidia H100 GPUs, making it the world’s most powerful AI system. Built in 122 days in Memphis and set to double in capacity soon, this development comes amid a global GPU shortage, with rivals like Meta and Microsoft also competing for AI supremacy.
DeepSeek-AI has released DeepSeek-V2.5, a powerful Mixture of Experts (MOE) model with 238 billion parameters, featuring 160 experts and 16 billion active parameters for optimized performance. The model excels in chat and coding tasks, with cutting-edge capabilities such as function calls, JSON output generation, and Fill-in-the-Middle (FIM) completion.
11. SalesForce Releases xLAM: A Family of Large Action Models for AI Agents
Salesforce has introduced two advanced AI models, xGen-Sales and xLAM, to help businesses increase automation and efficiency. These models are designed to set a new standard for AI-driven automation, particularly in sales and tasks that require triggering actions within software systems.
Seven 5-minute reads/videos to keep you learning
1. A Beginner’s Guide to Converting Numerical Data to Categorical: Binning and Binarization
This post explores two techniques: Binning and Binarization. These techniques are perfect for scenarios involving datasets such as Google Playstore data, where categories — like the number of app downloads — are more telling than raw numbers. The post provides easy-to-follow code examples for wrangling numerical data into meaningful categories.
2. In Defense of the Small Language Model
The article highlights that smaller language models (SLMs) like Llama 3.1–8B can excel in specific tasks such as PII redaction using advanced prompt engineering and efficient fine-tuning. These SLMs offer a cost-effective alternative to larger models like GPT-4o, making them suitable for enterprises balancing performance with budget constraints.
3. The Missing Guide to the H100 GPU Market
The article analyzes the H100 GPU market, highlighting stable prices and flexible short-term rentals. It compares the H100 to the A100 GPU, noting falling prices and growing availability. It also outlines the costs of purchasing versus renting, recommending rentals for better scalability and operational efficiency in AI applications
4. Top 10 Things We Learned About Educating Our Teams on Using AI Every Day
This article shares essential lessons about educating teams on the effective use of AI in their everyday tasks. It includes insights from Atlassian’s observation of 25 project managers and knowledge workers as they tested and implemented AI into their daily routines.
ggml is a minimalist C/C++ machine learning library designed for efficient Transformer inference, offering benefits like easy compilation, small binary size, and optimized memory usage. While it supports various hardware platforms, it requires low-level programming skills and may not support all tensor operations across all backends.
Machine learning projects often require the execution of a sequence of data preprocessing steps followed by a learning algorithm. Managing these steps individually can be cumbersome and error-prone. This post will explore how pipelines automate critical aspects of machine learning workflows, such as data preprocessing, feature engineering, and the incorporation of machine learning algorithms.
7. Simplifying Data Preprocessing With ColumnTransformer in Python: A Step-by-Step Guide
This blog explores how to handle data without ColumnTransformer and how it can make data preprocessing tasks much easier. The author works with a dummy dataset to make the concepts more digestible.
Repositories & Tools
1. Anthropic Quickstarts is a collection of projects designed to help developers quickly get started with building deployable applications using the Anthropic API.
2. Composio equips your AI agents & LLMs with 100+ high-quality integrations via function calling.
3. Laminar is a small library for building web application interfaces. It keeps the UI state in sync with the underlying application state.
4. CAR is a tool that creates and extracts archives without copying data.
Top Papers of The Week
1. LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
LongRecipe presents an efficient training method to extend LLMs’ context windows from 8k to 128k using innovative techniques that reduce computational resources by 85%, enabling this expansion on modest hardware.
2. LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
LongLLaVA is a Multi-modal Large Language Model (MLLM) designed to process extensive image datasets efficiently. It integrates Mamba and Transformer blocks, focuses on temporal and spatial dependencies, and utilizes progressive training to handle up to a thousand images with high throughput, low memory consumption, and competitive benchmark performance.
3. Evaluating Environments Using Exploratory Agents
This paper uses an exploratory agent to provide feedback on the design of five engaging levels and five unengaging levels of a game. The study shows that the exploratory agent can clearly distinguish between engaging and unengaging levels. This can be an effective tool for assessing procedurally generated levels in terms of exploration.
4. Attention Heads of Large Language Models: A Survey
This survey aims to shed light on the internal reasoning processes of LLMs by concentrating on the interpretability and underlying mechanisms of attention heads. It distills the human thought process into a four-stage framework: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. Using this framework, it reviews existing research to identify and categorize the functions of specific attention heads.
FluxMusic is an advanced text-to-music generation model that combines diffusion-based rectified flow Transformers with a latent VAE framework for mel-spectral analysis. Leveraging attention sequences and pre-trained text encoders improves semantic capture and input flexibility. The model surpasses existing methods based on both automatic metrics and human evaluations.
6. OLMoE: Open Mixture-of-Experts Language Models
OLMoE is a fully open language model leveraging sparse Mixture-of-Experts (MoE). It has 7 billion (B) parameters but uses only 1B per input token. It is pretrained on 5 trillion tokens and further adapted to create OLMoE-1B-7B-Instruct. The model outperforms all available models with similar active parameters, surpassing larger ones like Llama2–13B-Chat and DeepSeekMoE-16B.
Upcoming Events
The Towards AI team is attending the AI & Big Data Expo Europe, 1–2 October 2024
Event Highlights:
6 Co-Located Events — A comprehensive exploration of AI and Big Data with six co-located events.
7,000+ Attendees — Professionals, thought leaders, and enthusiasts from around the globe.
200+ Speakers — Industry experts from Netflix, IKEA, The UN, Deloitte, Booking.com, and more to share their insights, experiences, and forecasts.
Thematic Tracks — Covering Enterprise AI, Machine Learning, Security, Ethical AI, Deep Learning, Data Ecosystems, NLP, and more.
Date & Location: 1–2 October 2024 at the RAI, Amsterdam.
Your in-person ticket will also grant you access to the co-located events exploring IoT Tech, Intelligent Automation, Cyber Security & Cloud, Unified Communications, Edge Computing, and Digital Transformation!
Quick Links
1. At its annual fall product event, Apple unveils its latest generation of iPhones. While the new lineup has minimal hardware upgrades, the artificial intelligence-boosted iPhone 16 promises improvements in its Siri personal assistant as it rolls out new software.
2. In a recent post on Twitter (now X), music producer Timberland endorsed Suno AI, an AI-powered music tool. The reactions to Timbaland’s post are a mix of excitement and concern.
3. X permanently stopped Grok AI from using EU citizens’ tweets after Ireland’s Data Protection Commissioner (DPC) took it to court in Ireland. The platform had forcibly opted EU citizens into Grok’s training without asking permission.
Who’s Hiring in AI
Our Towards AI Jobs Search Platform is gaining momentum! We received 500,000 Google search impressions in August and are now listing 29,000 live AI jobs. Our LLM-enhanced pipeline continuously searches for jobs that meet our AI criteria and regularly removes expired jobs. We make it much easier to search for and filter by specific AI skills, and we also allow you to set email alerts for jobs with specific skills or from specific companies. All for free! We hope our platform will make it much quicker to find and apply for jobs that truly match your AI skills and experience.
Data Analyst Intern (6-month) @HoYoverse (Singapore)
AI2 Personalization Data Science Associate Program @TD Bank (Toronto, Canada)
Senior Software Engineer — Ads @Microsoft Corporation (Beijing, China)
AI Research Intern (Summer 2025) @RTX Corporation (Remote)
Sr Manager, Machine Learning @LinkedIn (NY, USA/Hybrid)
AI Tutor — Bilingual (Full-Time) @xAI (Remote)
Data Engineer, Analytics @Meta (Menlo Park, CA, USA)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.

Create a workflow as seamless as a https://colorearm.com/ setup using Replit Agent and Claude Enterprise!
If you’re looking for a fun and addictive online winter game, Snow Rider 2 is the perfect choice. Challenge your reflexes, chase new high scores, and enjoy nonstop snowy excitement. https://snowrider2.io