


Introduction to Reinforcement Learning Series.

Introduction to Reinforcement Learning Series. Tutorial 1; Motivation, States, Actions, and Rewards
Table of Content:
1. What is Reinforcement Learning?
5. Mini-Exercise — Identify State, Action & Rewards
8. Exercise 2 — Barry’s Boeings
Introduction
Welcome to the first tutorial for our Introduction to Reinforcement Learning series!
The idea that we learn by interacting with our environment probably occurs to us first when we think about learning something. When an infant plays or waves its arms, it has no teacher. However, it interacts with its environment by using its senses (e.g. vision, hearing) and taking actions (e.g. moving, speaking). This connection produces a wealth of information about cause and effect, the consequences of actions, and what to do to achieve goals.
This series initially formed part of Delta Academy and is brought to you in partnership with the Delta Academy team’s new project Superflows!

1. What is Reinforcement Learning?
The term Reinforcement Learning refers to both a class of problems & a set of solutions.
Reinforcement Learning problems are sequential decision-making problems, i.e., you must repeatedly make decisions.
Reinforcement Learning solutions are computational approaches to learning from interactions with an environment that solve sequential decision-making problems. They are a type of machine learning that learns from interacting with an environment that gives feedback.
The broader picture of Machine Learning
How does reinforcement learning fit into the broader picture of machine learning algorithms? Machine learning strategies can be divided into three categories.
Supervised Learning: Observations in the dataset are all labeled. The algorithm learns the mapping between data points and their labels. So, after learning, the algorithm can assign labels to new unlabelled data.
Unsupervised Learning: Observations in the dataset are unlabeled. The algorithm learns patterns in the data and relationships between data points. An example is clustering, where an algorithm learns how best to assign data points to groups.
Reinforcement Learning: RL differs from both supervised learning and unsupervised learning in that it does not have access to an unlabelled or labeled dataset, but rather selects actions and learns only from the feedback given by the environment.

2. Why is this Useful?
RL can learn highly complex behavior — it has seen remarkable breakthroughs in recent years. The highest-profile of these have been in playing games.
An RL algorithm, AlphaGo, famously beat the world champion in the game of Go in 2016. There’s a movie about it that’s free on YouTube — would strongly recommend it — see the trailer below.
<a href="https://medium.com/media/1b388b74424674a7e9d562239584576a/href">https://medium.com/media/1b388b74424674a7e9d562239584576a/href</a>
RL is also the technology behind this amazing feat accomplished by OpenAI in 2019 — they trained a robotic hand to solve a Rubik’s cube one-handed! It uses the video from cameras around the robotic hand to give it feedback as to how it’s doing.
<a href="https://medium.com/media/8a8b0eb4ecda27d04893d126486977d2/href">https://medium.com/media/8a8b0eb4ecda27d04893d126486977d2/href</a>
Reinforcement Learning has also reached a superhuman level of play in Poker, and numerous video games including DOTA & Starcraft 2.
While game-playing may seem like a small niche, RL can be applied far beyond this — it’s already used practically in a massive range of industries — from autonomous driving and robotics to advertising and agriculture. And as the technology develops in capabilities, so too will the number of practical applications!
Examples
A good way to understand reinforcement learning is to consider some examples of applications.
A master chess player looks at the pieces on the board and makes a move.
An adaptive controller adjusts an oil refinery’s operation in real-time. The controller optimizes the yield/cost/quality trade-off.
A mobile robot decides whether it should enter a new room in search of more trash to collect or start trying to find its way back to its battery recharging station.
These examples share features that are so basic that they are easy to overlook. All involve interaction between a decision-making agent and its environment. The agent seeks to achieve a goal. The agent’s actions affect the future state of the environment (e.g. the level of reservoirs of the refinery, the robot’s next location, and the future charge level of its battery). This, therefore, affects the actions and opportunities available to the agent at later times.
Note: from here on, this tutorial is unusually terminology-heavy. Stick with it, and keep the above examples in mind, it’ll be worth the effort in the end!
3. Markov Decision Process
Markov Decision Process is the technical name for the broad set of problems that Reinforcement Learning algorithms solve.
They are discrete-time processes. This means time progresses in discrete steps. E.g. a single action is taken every 0.1 seconds, so at 0.1s, 0.2s, 0.3s, …
At each timestep t, the agent takes an action a, the state s updates as a result of this action, and a reward r is given.
They have specific definitions of their 3 key elements, which are detailed below:
The state (denoted s ) — the state the environment is in
An action (denoted a ) — one of the possible decisions made or actions taken by the agent
The reward (denoted r ) — the feedback signal from the environment
The aim of solving the MDP is to find a way of acting that maximizes the sum of future rewards. I.e. the reward at every future timestep added up.

Review
This course uses an experimental learning system called Orbit, intended to make it much easier for you to remember and apply this material, over the long term. Throughout the tutorials, we occasionally pause to ask a few quick questions, testing your understanding of the material just explained. In the weeks ahead, you’ll be re-tested in follow-up review sessions. Orbit carefully expands the testing schedule to ensure you consolidate the answers into your long-term memory while minimizing the review time required. The review sessions take no more than a few minutes per session, and Orbit will notify you when you need to review.
The benefit is that instead of remembering how reinforcement learning works for a few hours or days, you’ll remember for years. It’ll become a much more deeply internalized part of your thinking. Please indulge us by answering these questions — it’ll take just a few seconds. For each question, think about what you believe the answer to be, click to reveal the actual answer, and then mark whether you remembered or not. If you can recall, that’s great. But if not, that’s fine, just mentally note the correct answer, and continue.
Review the Questions and Answers:
1. Give two examples of problems RL could solve.
➥ e.g. choosing moves to make in a board game; adjusting the shower knobs to maintain a comfortable temperature; a search-and-rescue robot deciding how to navigate a building.
2. What kind of problems do reinforcement learning systems solve?
➥ Sequential decision-making problems (i.e. situations where an agent must repeatedly choose an action)
3. What three key elements occur at each time step in a Markov decision process?
➥ Agent takes action a; the environment state s is updated; a reward r is given.
4. What defines the optimal solution to a Markov decision process?
➥ It maximizes the sum of future rewards.
5. How do Markov decision processes model time?
➥ As a series of discrete, fixed-size steps.
6. What’s the technical name for the problems which RL algorithms solve?
➥ Markov decision processes.
7. How does the data used to train RL systems differ from supervised and unsupervised learning?
➥ Supervised/unsupervised systems learn from a dataset; RL systems learn from feedback given by an environment.
4. State, Actions & Rewards
State st
Note: the subscript t in st just means it’s the state at time t. We’ll follow this convention throughout the course when talking about quantities that change over time t.
The key aspect of the state in a Markov Decision Process is that it is ‘memoryless’.
This means that the current state fully summarises the environment. Put another way, you gain no information about what will happen in the future by knowing preceding states (or actions).
Put a third way, if you knew only this, you could recreate the game completely from this point on.
Examples:
The pieces and their locations are on a chessboard
The position & orientation of the mobile robot plus the layout of its environment
Action at
These are the choices the agent can make. At each timestep, the agent takes one action. These affect the successor state of the environment — the next state you are in.
Action can have multiple independent dimensions. E.g. a robot can decide its acceleration/deceleration independent from deciding its change in turning angle.
Examples:
Any move of your piece on the chessboard
The heating/cooling and the stirring occur in the oil refinery
Reward rt
A reward signal defines the goal of a reinforcement learning problem. At each timestep, the environment sends a single number called the reward to the reinforcement learning agent.
The agent’s objective is to maximize its total reward over the long run.
The reward is received as the environment transitions between states. So the sequence of events when interacting with an environment is shown below & after step 3, steps 2 & 3 alternate. Your agent is only in control of step 2 while the environment is in control of step 3.

For many tasks you might want to train a reinforcement learning agent to solve, there isn’t a well-defined reward function.
Take robot navigation as an example. Reaching the desired destination should give a positive reward, but what about the reward from all the other timesteps? Should they be 00? Or how about higher rewards given based on how close it is to the destination? In such cases, it is often the RL designer’s job to decide what the reward should be based on the task he wants the agent to solve.
This means that by defining the reward function, you can train your agent to achieve different goals. For example, in chess, if you want to train your agent to lose as fast as possible, you could give a positive reward for losing and a negative one for winning.
Examples:
+1 for winning a chess game, -1 for losing, 0 otherwise
+100 To reach the goal location, -1 otherwise*
∗∗ The -1 is to encourage the robot to make it there as fast as possible, as the longer it takes, the more negative reward it gets.
5. Mini-Exercise — Identify State, Action & Rewards
The code for all our tutorials is hosted on a platform called Replit. It runs the code in the cloud and allows easy, live collaboration in an IDE with zero setups.
Replit is great because it means you don’t have to do any installs yourself — the environment is taken care of. If you have any trouble with it, please contact us on Slack!
Join Replit here
Once you’ve clicked the above link, you should be able to access the link below.
Each of the mini-exercises is an example of MDP.
For each mini-exercise, there are 5 quantities listed. 2 of these are false flags, and the other 3 are the state, action & reward.
Enter in the line at the bottom which string describes the state, action & reward in this scenario.
https://replit.com/team/delta-academy-RL7/12-MDP-MCQs
6. Policy π(s)
(last bit of terminology for this tutorial, I promise!)
A policy is a function that picks which action to take when in each state. It’s the core of a reinforcement learning agent — determines the agent’s behavior.
It’s commonly represented by the Greek letter Pi (pronounced ‘pie’), π. Mathematically, it’s a policy that takes a state as input and outputs an action
Example:
In the case of a game of chess, the policy tells you what action to take in each state.
In some cases, the policy may be a simple function or a lookup table (i.e. in-state X, take action Y, defined for all states), whereas in others it may involve extensive computation such as planning a sequence of actions into the future (and then performing the first action in this sequence).
In general, policies may be stochastic, specifying probabilities for each action.
Note: stochastic simply means ‘includes randomness’, as opposed to deterministic, which will give the same output every time for the same input.
Review the Questions and Answers:
1. In a Markov decision process, action at produces reward r at what time step?
➥ t+1, i.e. at yields rt+1
2. How might you cause a robot trained via RL to find the quickest path to its destination?
➥ e.g. Give a negative reward for every time step before it reaches its destination.
3. What does it mean for a policy function to be stochastic?
➥ It outputs a probability for each action, rather than defining a single definite action.
4. Why might it not be the best strategy for an RL agent to simply choose the next action with the highest estimate reward?
➥Its goal is to maximize the total reward over all future steps, not just the next one.
5. If you wanted to losslessly save and restore a Markov decision process, what information would you need to persist?
➥ Only the current state.
6. What does it mean that Markov decision processes are memoryless?
➥ The current state fully defines the environment — i.e. previous states and actions provide no extra information.
7. In a chess-playing RL system, what might the policy function take as input and produce as output?
➥ The input is the state, i.e. the positions of all pieces on the board. The output is the action, i.e. a move to make.
8. In this course, what’s meant by the notation xt?
➥ The value of x at time t.
9. If a Markov decision process takes only one action per time step, how to model a search-and-rescue robot which can both accelerate and turn?
➥ Model changes to acceleration and orientation as independent dimensions of a single action vector.
10. What is a “successor state” in a Markov decision process?
➥ The agent’s next state (after taking its next action).
11. What is a “policy” in an RL system?
➥ A function which chooses an action to take, given a state.
12. Practically speaking, how does an RL designer express different goals for his agents?
➥ By defining different reward functions.
13. In a Markov decision process modeling a search and rescue robot, what might the state describe?
➥ e.g. Estimates of the robot’s pose and the building’s layout.
7. Example Solved MDP
So what does it mean to solve a Markov Decision Process? It means finding the policy which maximizes the future sum of rewards.
This is typically called the optimal policy. It’s what every Reinforcement Learning algorithm is trying to find.
Here is an example of MDP that is perhaps relevant to you!

There are 3 states — Learning RL, Sleep & Pub. In this MDP, at any point in time, you are in one of these 3 states.
You have 3 actions you can take: Go to sleep, Go to Pub and Study. Each of these gives a different reward based on what state you're in. These rewards are shown in red.
The Optimal Policy
The optimal policy is the mapping from state to action that gets the highest possible reward over time.
Taking a quick look at the MDP diagram, we should quickly see that Pub is a bad state to enter or be in.
Staying in Sleep state gets a reward per timestep of 1. Learning RL gets us a reward of 6 per timestep. And going from Sleep to Learning RL (learning RL when fresh is best) gets 10, the biggest reward!
So to get the maximum future reward, you want to alternate between Sleep and Learning RL, giving an average reward per timestep of 7.5.
This isn’t the same as just taking the action that gives the maximum reward the next timestep. That would mean staying in Learning RL forever since the reward of 6 the Study action is higher than the 5 of Go to Sleep. Over time, the average reward is higher if you alternate.
And what do we do if we’re in the state Pub? We should take the action that takes us to either Sleep or Learning RL which costs us the least. In this case, taking the Go to sleep action costs us the least.
We can represent this in a Python dictionary like so:
# Dictionary of {state: action} pairs
optimal_policy = {
"Pub": "Go to sleep",
"Sleep": "Study",
"Learning RL": "Go to sleep"
}
for state, action in optimal_policy.items():
print(f"If in state: {state}, then take action: {action}")
### Result --->
"""
If in state: Pub, then take action: Go to sleep
If in state: Sleep, then take action: Study
If in state: Learning RL, then take action: Go to sleep
"""8. Exercise 2 — Barry’s Boeings

https://replit.com/team/delta-academy-RL7/12-Barrys-Boeings
You’ve ended up in the orbit of Barry. He’s the CEO of a major airline called BarryJet (haven’t you heard of it?).
Boeing has sold him planes with faulty ailerons, but the replacement parts they sell are also faulty! After every flight they become faulty, and after 2 flights without repair, they go out of operation.
He wants you to figure out the right policy for this MDP — what action should he take in each state?
Write the optimal policy dictionary in the Replit linked above.
Exercise 3 — Barry’s Execs
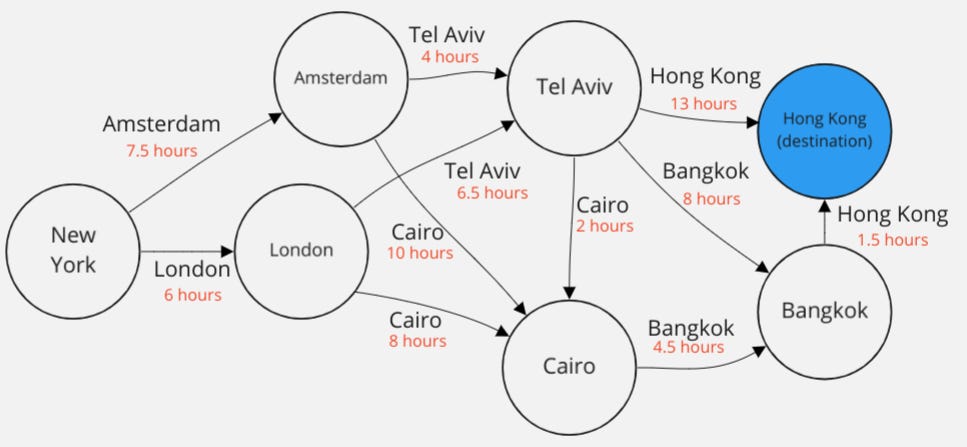
https://replit.com/team/delta-academy-RL7/13-Barrys-Execs
Barry’s senior execs are spread out across the world. But they have a very important meeting to attend in Hong Kong.
To show brand loyalty, they must always travel by BarryJet, but sadly for them, their planes are economy-only and the passengers are crammed in so tightly that it’s physically impossible to work. So Barry wants to work out the fastest way for his senior execs to travel to Hong Kong.
Barry again wants you to find the policy (in your head) which minimizes the time wasted by his execs.
Write the optimal policy dictionary in the code linked above.
Introduction to Reinforcement Learning Series. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.